Actualités de l'IA et du ML en français Suivre
« AI & ML News » est une collection de notes technologiques axées sur l'intelligence artificielle et l'apprentissage automatique. Il rassemble les actualités et les analyses des derniers développements en matière d'IA et de ML.
Le flux couvre un large éventail de sujets, y compris les nouveaux algorithmes, les applications et la recherche. Il met en évidence les tendances de l'industrie et l'impact de l'IA et de l'apprentissage automatique sur divers secteurs de l'économie.
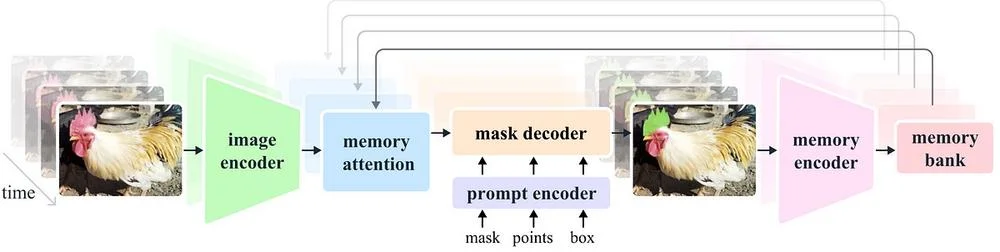
Les documents traitent de domaines tels que les réseaux neuronaux, l'apprentissage profond et le traitement du langage naturel. Des exemples d'applications de l'IA dans les soins de santé, la finance et d'autres industries sont examinés.
Les publications intéresseront à la fois les spécialistes - développeurs et analystes de données - et toute personne intéressée par le développement des technologies de l'IA. Les questions d'éthique de l'IA et de confidentialité des données sont abordées.
Le flux présente aux lecteurs les principaux acteurs du marché de l'IA, qu'il s'agisse de grandes entreprises ou de jeunes pousses prometteuses. Des informations sur les outils et les plateformes de développement de systèmes d'IA sont présentées.
« AI & ML News » vise à fournir des informations objectives et actualisées sur le développement de l'intelligence artificielle et de l'apprentissage automatique.