Amélioration de la pertinence de la recherche sur Pinterest en utilisant de grands modèles de langage
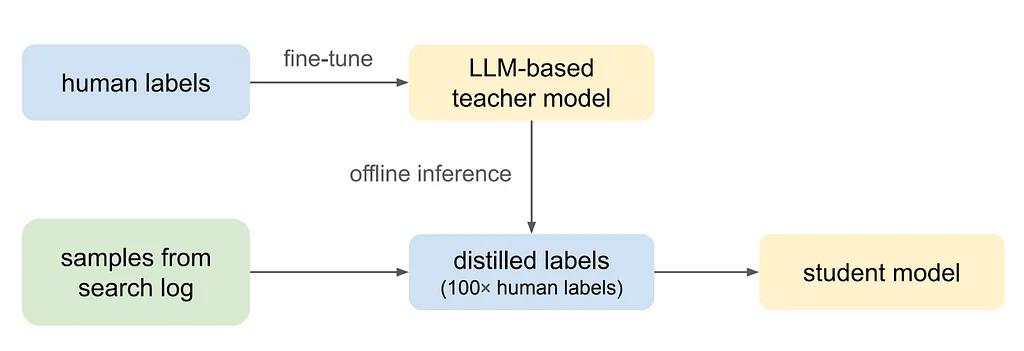
La recherche Pinterest est une surface clé où les utilisateurs peuvent découvrir du contenu inspirant qui correspond à leurs besoins d'information, et la pertinence de la recherche mesure à quel point les résultats de la recherche correspondent à la requête de recherche. Pour améliorer le modèle de pertinence de la recherche, une directive à 5 niveaux est utilisée pour mesurer la pertinence entre les requêtes et les épingles. Un modèle de langage cross-encoder est utilisé pour prédire la pertinence d'une épingle par rapport à une requête, ainsi que le texte de l'épingle, et la tâche est formulée comme un problème de classification multiclasse. Le modèle est affiné en utilisant des données annotées par des humains, en minimisant la perte d'entropie croisée.Pour représenter chaque épingle, un ensemble varié de caractéristiques textuelles est utilisé, notamment les titres et les descriptions des épingles, les légendes d'images synthétiques, les jetons de requête à forte interaction, les titres de planches créés par les utilisateurs et les titres et les descriptions de liens. Cependant, le classificateur basé sur le modèle de langage cross-encoder LLM est difficile à mettre à l'échelle pour la recherche Pinterest en raison de considérations de latence et de coût en temps réel. Par conséquent, la distillation des connaissances est utilisée pour distiller le modèle d'enseignant LLM en un modèle d'apprentissage léger.Le modèle d'apprentissage utilise des caractéristiques au niveau de la requête, des caractéristiques au niveau de l'épingle et des caractéristiques d'interaction requête-épingle pour prédire des scores de pertinence à 5 échelles. La distillation des connaissances et l'apprentissage semi-supervisé sont utilisés pour former le modèle d'apprentissage, qui utilise efficacement de grandes quantités de données initialement non étiquetées et étend les données à un large éventail de langues du monde entier.Les expériences hors ligne démontrent l'efficacité de chaque décision de modélisation, notamment la comparaison des modèles de langage, l'importance de l'enrichissement des caractéristiques textuelles et la mise à l'échelle des étiquettes de formation grâce à la distillation. Les résultats en ligne montrent une amélioration de +2,18 % de la pertinence de l'alimentation de recherche, telle que mesurée par nDCG@20, et une augmentation significative des taux de satisfaction de la recherche à l'échelle mondiale.Le pipeline de modélisation de la pertinence proposé généralise efficacement à travers les langues non rencontrées pendant la formation, et le modèle d'enseignant LLM multilingue généralise à travers les langues non vues. Les travaux futurs exploreront l'intégration de LLM servables, de modèles multimodaux vision-langage et de stratégies d'apprentissage actif pour mettre à l'échelle dynamiquement et améliorer la qualité des données de formation.