Traitement de données de nouvelle génération à grande échelle sur Pinterest avec Moka (1ère partie sur 2)
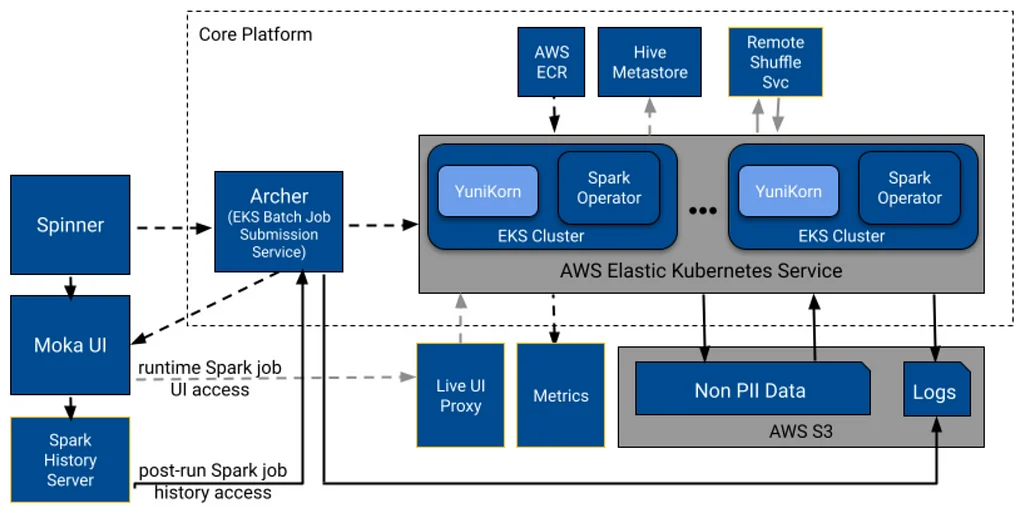
L’équipe d’ingénierie des données de Pinterest est en train de créer une nouvelle plateforme de traitement de données à grande échelle pour remplacer sa plateforme actuelle basée sur Hadoop, Monarch. L’équipe a exploré les systèmes basés sur Kubernetes en remplacement en raison de leur popularité croissante et de leur adoption croissante dans la communauté du Big Data. La nouvelle plateforme devait répondre à certains critères, notamment une prise en charge étendue des conteneurs, l’exécution de la fourche Spark personnalisée de Pinterest et une réduction des coûts d’exploitation et de maintenance. L’équipe a effectué une évaluation complète de l’exécution de Spark sur diverses plates-formes et s’est tournée vers les frameworks axés sur Kubernetes en raison de leurs avantages, notamment l’isolation et la sécurité basées sur les conteneurs, la facilité de déploiement et les frameworks intégrés. Kubernetes offre une prise en charge plus précise de la gestion et du déploiement des conteneurs que les autres systèmes, mais ne prend pas en charge la gestion, le stockage et le traitement des données. Le modèle de déploiement actuel de l’équipe dans Hadoop est lourd, et l’équipe s’oriente vers une approche plus simple à l’aide de Terraform, d’images de conteneurs et de Helm. La nouvelle plateforme s’appuiera sur Kubernetes et EKS pour remplacer Monarch, ce qui présente plusieurs défis, notamment l’intégration d’EKS dans l’environnement Pinterest existant et la recherche de remplacements pour les composants Hadoop. L’équipe a créé une nouvelle plateforme, Moka, capable de traiter des charges de travail Spark par lots qui n’accèdent qu’aux données non sensibles, et ajoutera plus de fonctionnalités à l’avenir. La conception initiale de haut niveau de Moka comprend un système capable de traiter des charges de travail Spark par lots, avec des tâches soumises et traitées par une série de composants, notamment Spinner, Archer et Spark Operator. L’équipe fournira plus de détails sur les principaux aspects de leur plateforme axés sur les applications dans la prochaine partie de leur série de blogs.