Traitement des données de nouvelle génération à grande échelle chez Pinterest avec Moka (Partie 2 sur 2)
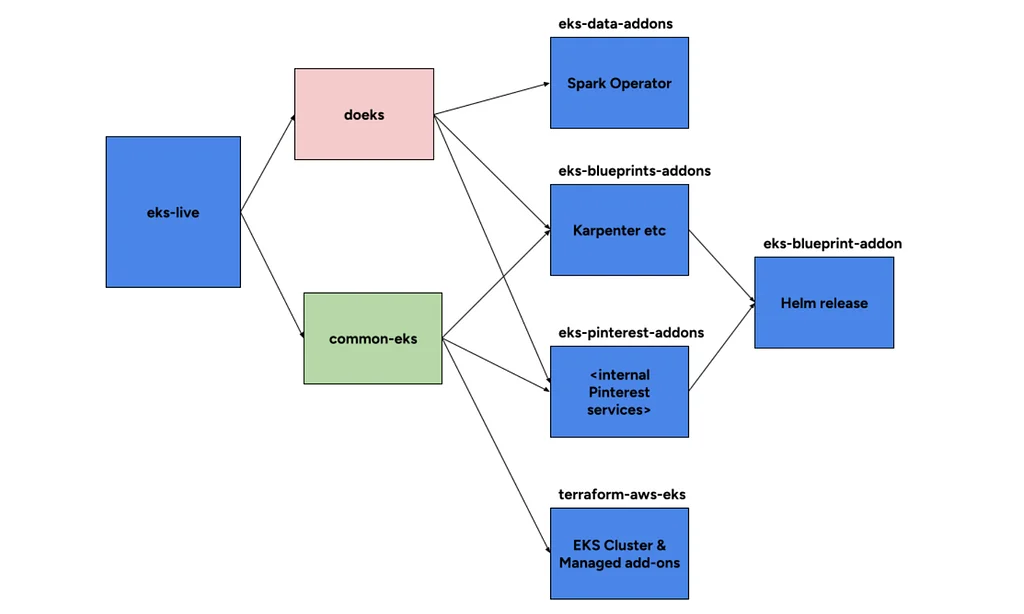
Pinterest développe Moka, une plateforme de traitement de données de nouvelle génération, pour remplacer son ancien système basé sur Hadoop. Cette plateforme est déployée sur AWS Elastic Kubernetes Service (EKS) dans quatre environnements : test, dev, staging et production. Terraform, complété par des modules AWS personnalisés et des graphiques Helm, gère les déploiements de clusters EKS. Un composant essentiel de Moka est son infrastructure de journalisation, qui utilise Fluent Bit pour collecter et exporter les journaux des plans de contrôle EKS, des applications Spark et des pods système vers Amazon S3. Fluent Bit est configuré pour regrouper les journaux des applications Spark par un identifiant de tâche unique et pour analyser les journaux YuniKorn afin d'obtenir des résumés de l'utilisation des ressources. Pour l'observabilité, Pinterest utilise un framework compatible avec Prometheus pour collecter des métriques. Ils ont développé un sidecar personnalisé, kubemetricsexporter, pour relier leur système Statsboard existant basé sur TSDB aux métriques Prometheus. L'OpenTelemetry Collector est utilisé pour recevoir, traiter et exporter les données de télémétrie, avec un pipeline spécifique configuré pour les métriques Prometheus. Cette infrastructure robuste vise à garantir un traitement des données efficace et fiable à grande échelle pour Pinterest.