Notizie su AI e ML in italiano Segui
“AI & ML News” è una raccolta di note tecnologiche incentrate sull'intelligenza artificiale e l'apprendimento automatico. Raccoglie notizie attuali e recensioni sugli ultimi sviluppi in materia di AI e ML.
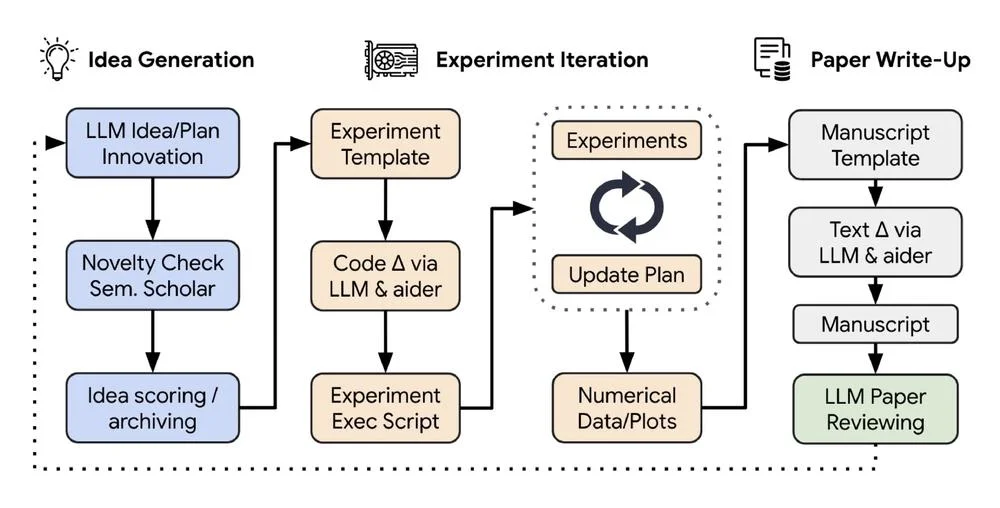
Il feed copre un'ampia gamma di argomenti, tra cui nuovi algoritmi, applicazioni e ricerche. Evidenzia le tendenze del settore e l'impatto dell'IA e del ML sui vari settori dell'economia.
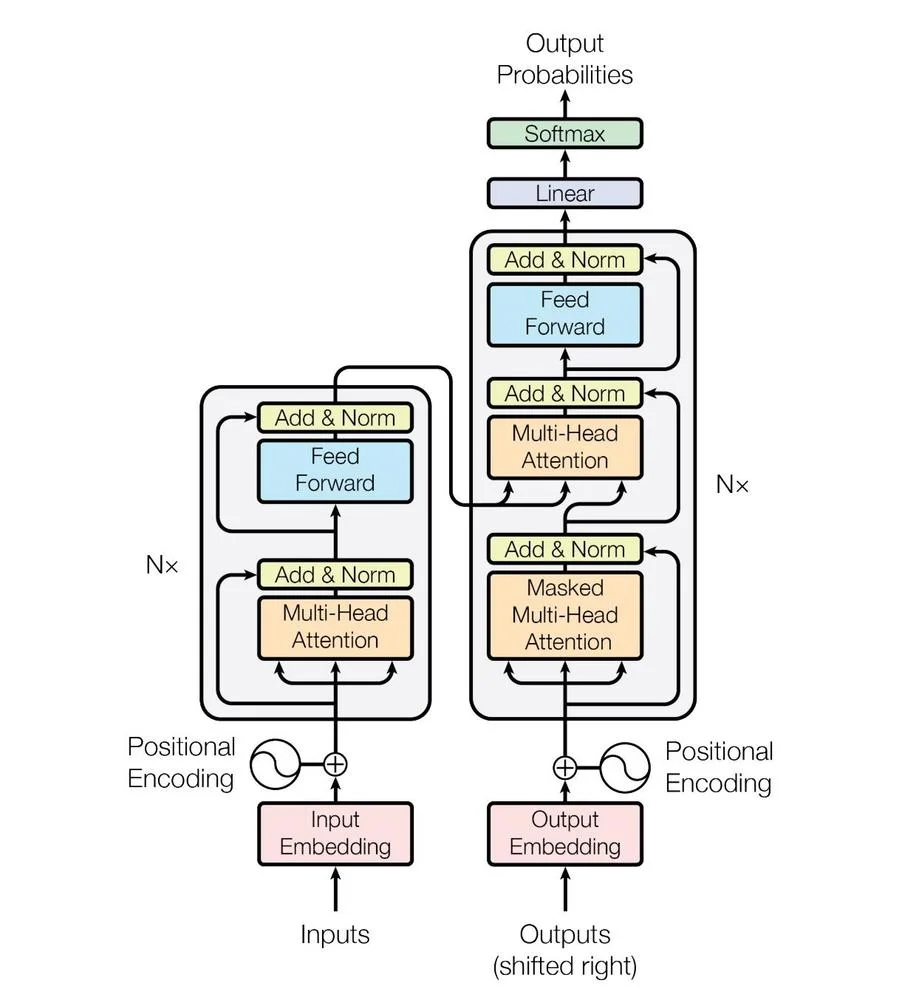
I materiali riguardano aree come le reti neurali, l'apprendimento profondo e l'elaborazione del linguaggio naturale. Vengono esaminati esempi di applicazioni dell'IA nella sanità, nella finanza e in altri settori.
Le pubblicazioni saranno di interesse sia per gli specialisti - sviluppatori e analisti di dati - sia per chiunque sia interessato allo sviluppo delle tecnologie di IA. Vengono affrontate le questioni relative all'etica dell'IA e alla privacy dei dati.
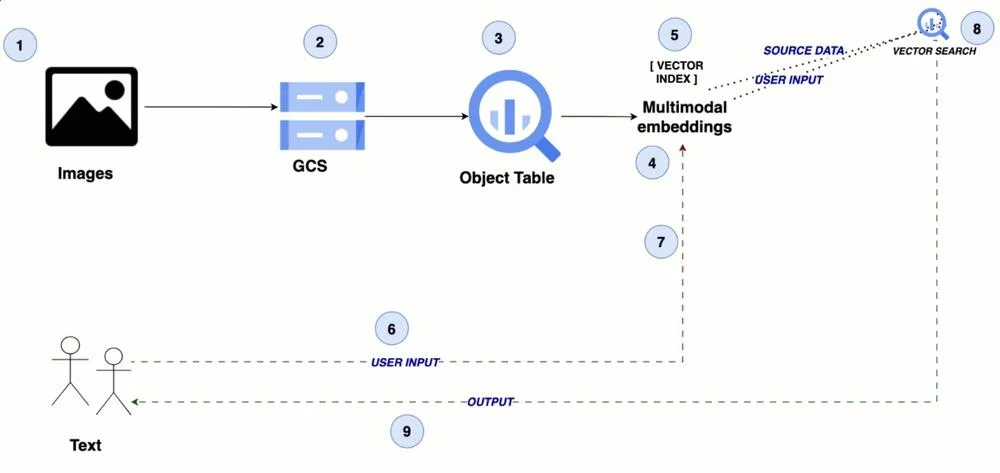
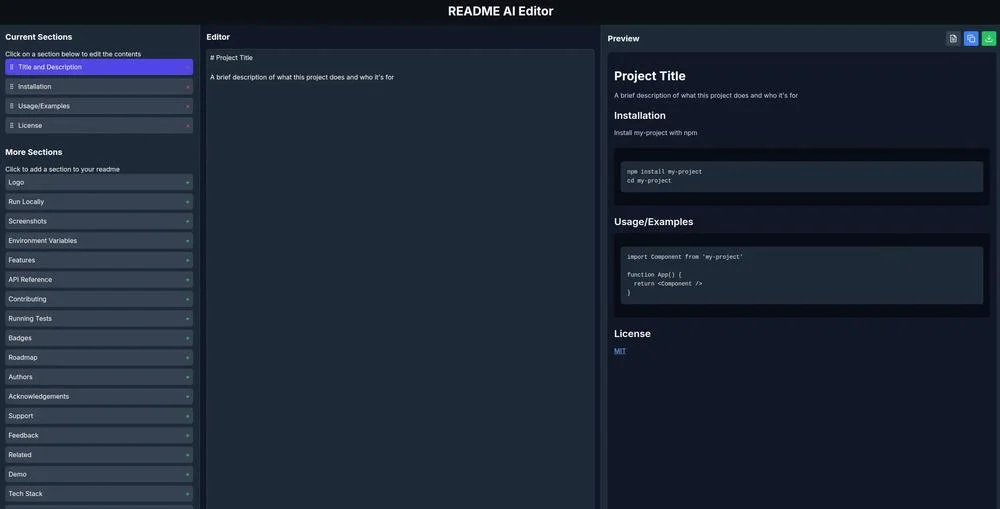
Il feed presenta ai lettori i principali attori del mercato dell'IA, dalle grandi aziende alle promettenti startup. Vengono presentate informazioni su strumenti e piattaforme per lo sviluppo di sistemi di IA.
“AI & ML News” si propone di fornire informazioni obiettive e aggiornate sullo sviluppo dell'intelligenza artificiale e dell'apprendimento automatico.