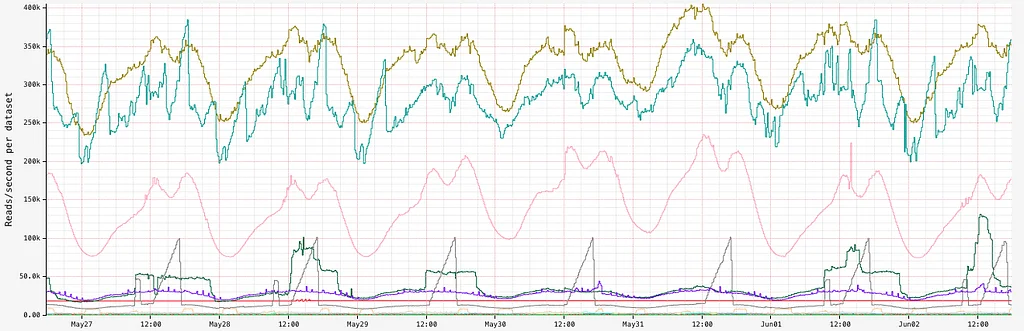
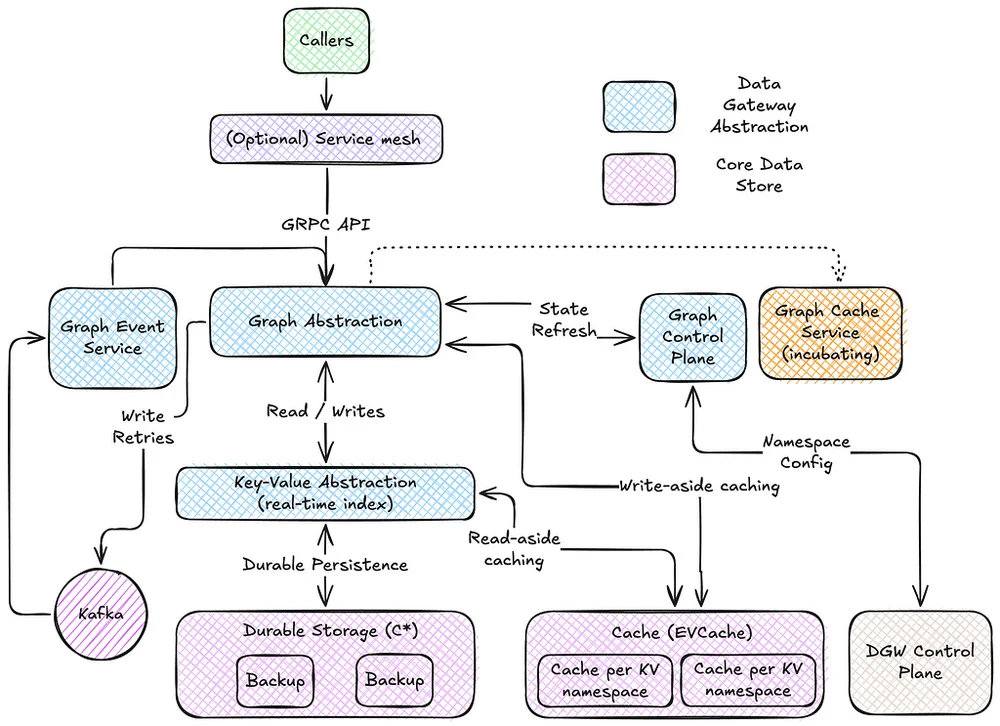
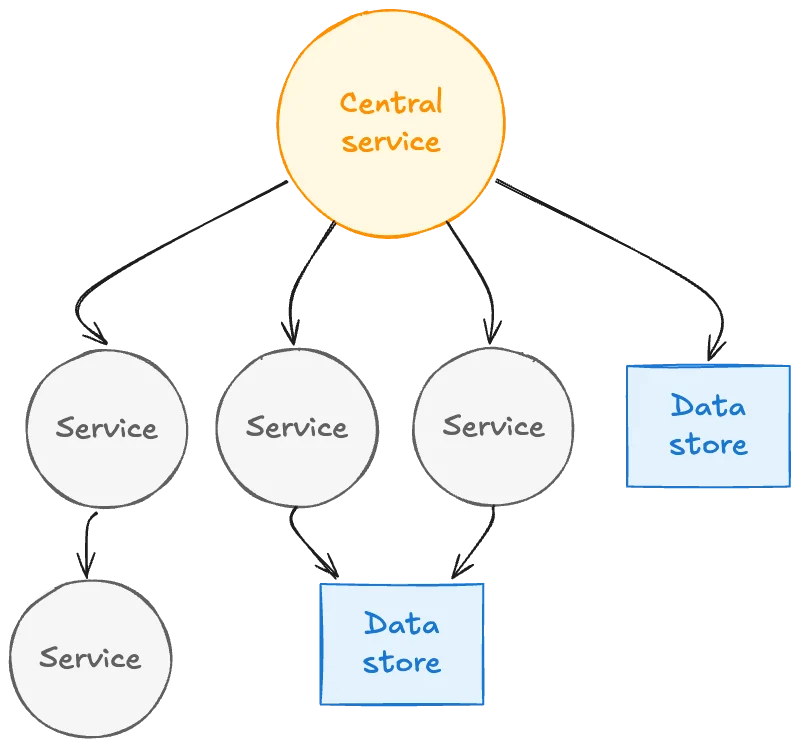
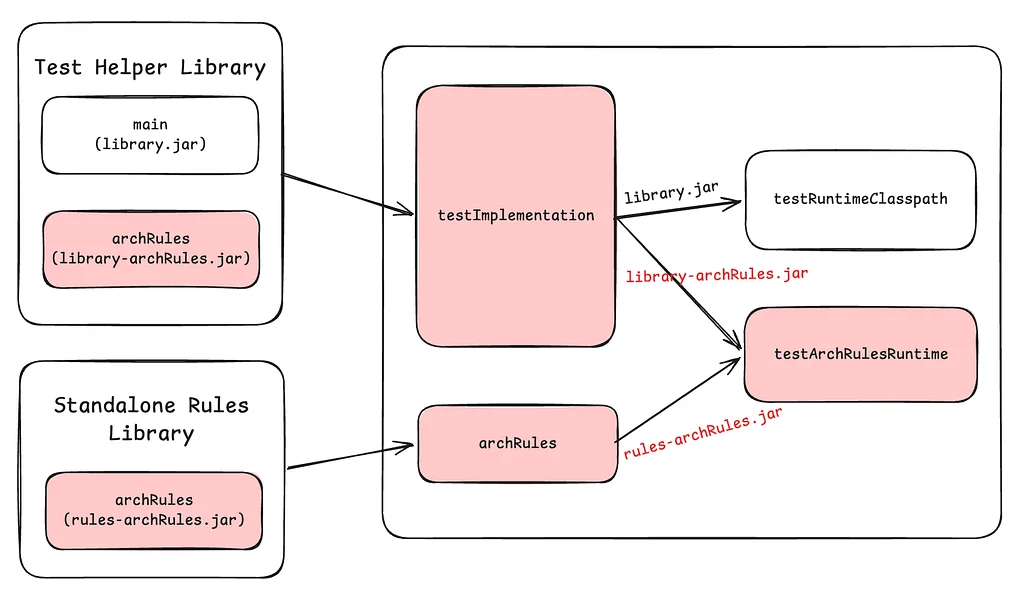
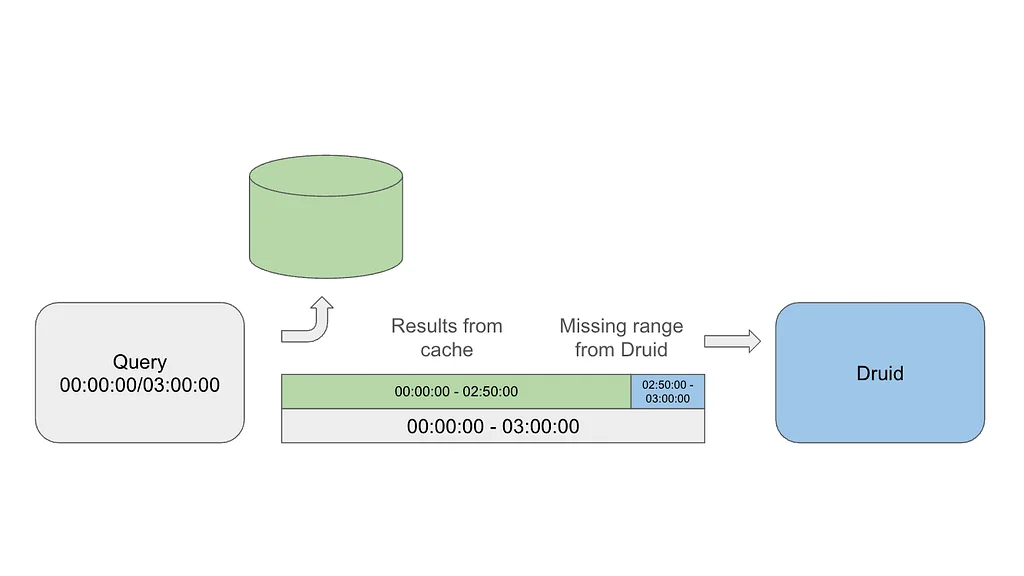
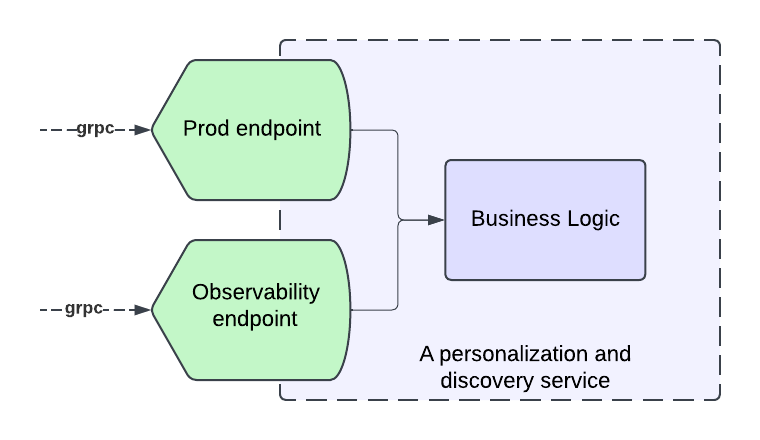
Netflixは、大規模なDruidクエリのパフォーマンスを向上させるために、実験的なキャッシュレイヤーを実装しました。このキャッシュシステムは、特に注目度の高いイベント中に、ダッシュボードからの冗長なクエリという問題を解決します。その中心的なアイデアは、結果の一部をキャッシュし、最新のデータのみをDruidに問い合わせることで、わずかな古さとのトレードオフを導入することです。指数関数的なTime-To-Live(TTL)値が使用され、遅れて到着するイベントに対応するために、古いデータほど長くキャッシュされます。キャッシュシステムは、キャッシュデータの効率的な範囲スキャンのために、マップ・オブ・マップ構造を使用しています。キャッシュはDruidルーターでリクエストを傍受し、必要に応じて結果を提供したり、Druidに問い合わせたりします。このソリューションは、キャッシュされたデータと最新のデータを組み合わせ、完全な結果を返し、最新のデータを非同期的にキャッシュします。空のバケットにはネガティブキャッシュが使用され、末尾の空のバケットをキャッシュしないように注意が払われています。このシステムは、NetflixのKey-Value Data Abstraction Layer(KVDAL)を使用しており、Cassandraをバックエンドとしています。Cassandraは、各データポイントに独立したTTLを提供します。このキャッシュレイヤーは、Druidクエリの負荷を大幅に削減し、特に大量のイベント中にクエリ時間を改善しました。このキャッシュシステムはまだ実験段階であり、今後の目標には、Druid自体への統合が含まれています。
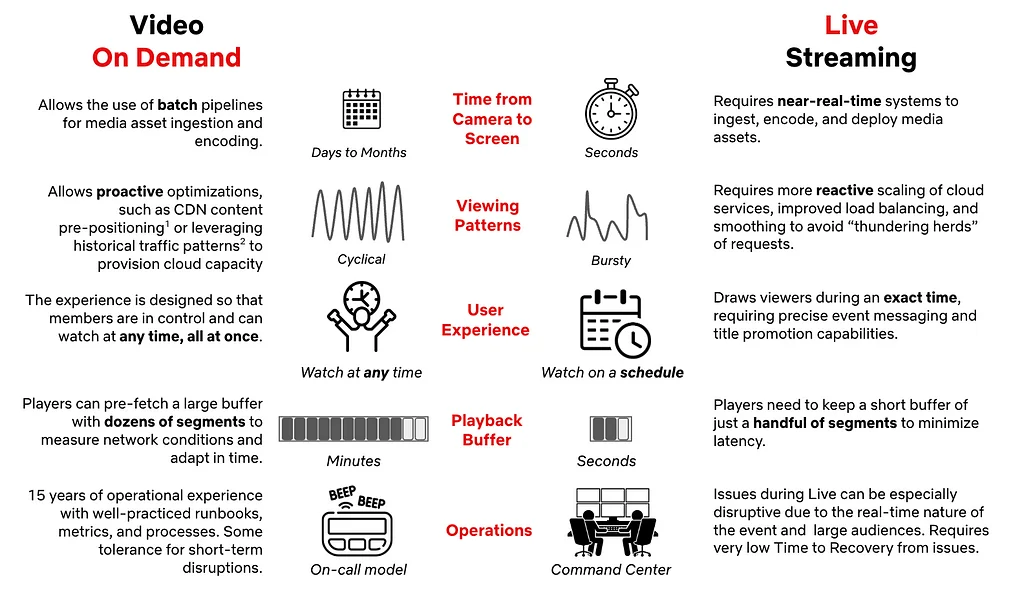
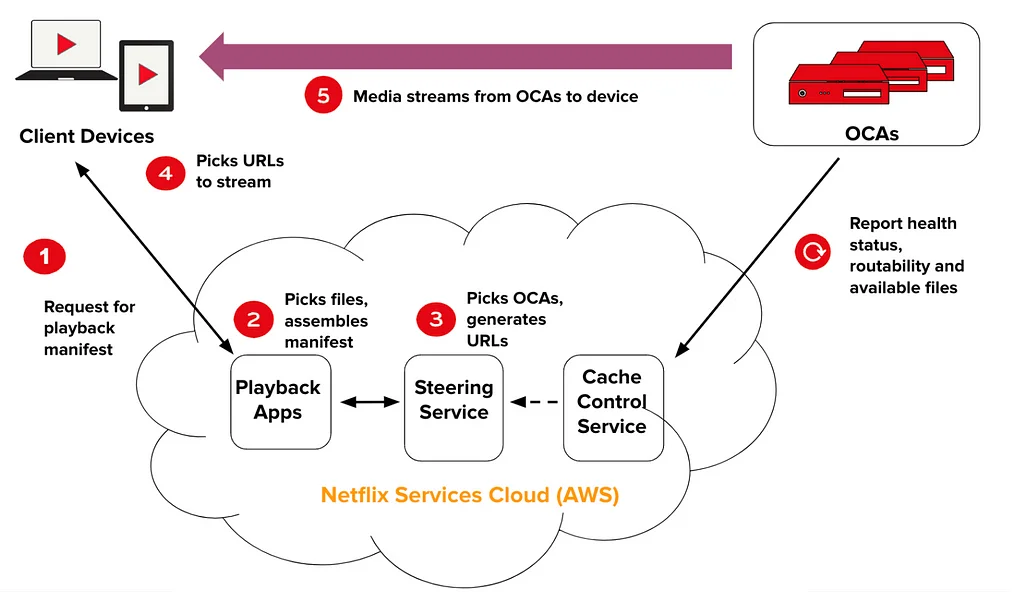
3年前、Netflixは、テレビ放送とほぼ同じくらい歴史の古いフォーマットであるライブストリーミングを通じて世界を楽しませる方法を模索しました。この問いから、コメディショー、スポーツ、WWEイベントなど、何百ものライブイベントが開発されました。Netflixは「Behind the Streams」と題したシリーズで、ライブストリーミング機能構築の技術的な道のりを共有します。ライブストリーミングは、アーキテクチャや技術選定における新たな考慮事項をもたらし、Netflixでうまく機能させるためには、かなりの構築が必要でした。Netflixのライブアーキテクチャの主要な柱には、専用の放送施設、クラウドベースの冗長なトランスコーディングおよびパッケージングパイプライン、ライブコンテンツ配信のスケーリング、ライブ再生の最適化、そしてクラウドでのディスカバリおよび再生制御サービスの実行が含まれます。Netflixはまた、クラウド上でリアルタイムメトリクスを一元化し、専門的なツールと施設を活用しました。ライブ機能の構築は、新たな課題と学習の機会をもたらし、Netflixは現在も日々、ライブイベントをより効果的に配信する方法を学んでいます。これまでの主な学習成果としては、徹底的なテスト、定期的な練習、視聴者予測、段階的な機能低下、そしてリトライストームの重要性が挙げられます。Netflixは堅牢なライブストリーミングシステムの構築において大きな進歩を遂げましたが、学ぶべきこと、改善すべきことはまだ多くあります。
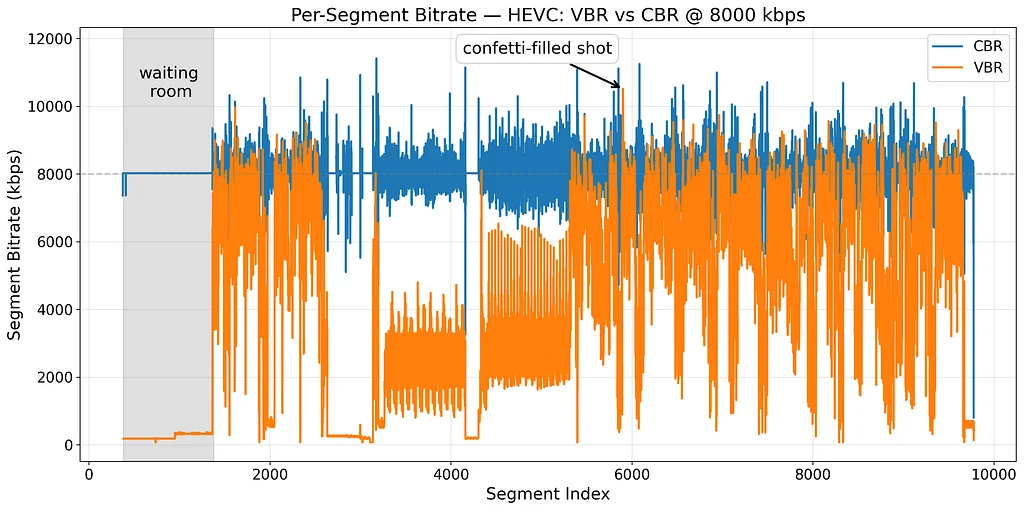
Netflixは、映画の芸術的インテグリティを保持しながらデータ効率を最適化するAV1 Film Grain Synthesis(FGS)ストリームを導入しました。映画のグレインは、映画の物語に深みとリアリズムを追加する重要な要素ですが、伝統的なアルゴリズムでは圧縮するのが困難です。AV1 FGSツールは、映画のグレインを2つのコンポーネントに分割してモデル化しています。すなわち、映画のグレインのパターンと映画のグレインの強度です。映画のグレインのパターンは、自己回帰モデルを使用して複製され、映画のグレインの強度はスケーリング関数によって制御されます。エンコーディングプロセスでは、ビデオから映画のグレインを除去し、圧縮し、圧縮されたビデオデータと一緒にグレインのパターンと強度を送信します。再生中、ブロックベースの方法を使用して映画のグレインが再作成され、ビデオに再統合されます。AV1 FGSの有効化により、ビットレートの削減が達成され、高品質のビデオストリーミングが少ないデータで実現可能になりました。また、視覚的な品質も向上し、合成ノイズが圧縮アーティファクトを効果的にマスクしています。Netflixは、プラットフォーム全体でFGSを展開し、サポートデバイス上でFGS対応ストリームを利用できるようになりました。展開により、Netflixメンバーのためのよりスムーズで信頼性の高いQuality of Experienceが実現され、ビットレートが低下し、再生エラーが減少し、再生の安定性が向上しました。
「映画産業がクラウドベースのワークフローに移行するにつれて、グローバルな実施に課題が生じています。Netflixは、映画製作者向けに設計されたMedia Production Suite(MPS)を通じて、これらの問題を解決しようとしています。MPSは、メディア管理をストリームライン化し、退屈なタスクを排除し、創造的なフォーカスを高めます。物理テープを使用した従来のワークフローは、遅くてcumbersomeであり、コラボレーションを阻害しています。デジタルワークフローも、配布や標準化の課題に直面しています。クラウドは、解決策を提供しますが、運用上の課題や技術的なハードルを克服する必要があります。Netflixは、これらの問題を、メディアに人々やアプリケーションを持ち込む代わりに、逆のアプローチで解決しています。MPSは、技術や標準化のグローバルな格差に取り組み、多様な市場のニーズを考慮しています。スイートは、業界標準に基づくカラーマネジメントやフレーミングなどのプロセスを自動化しています。インフラストラクチャーは、クラウドと物理的な能力を最適化し、ユーザーのパフォーマンスを向上させています。MPSには、インジェスト、メディアライブラリ、デイリーズ、リモートワークステーションなど、多くのツールが含まれています。350以上のタイトルがMPSのツールを使用しており、世界各地からのフィードバックを受けています。ブラジルのシリーズ「セナ」がMPSを採用し、地理的なバリアーを克服する能力を示しています。」
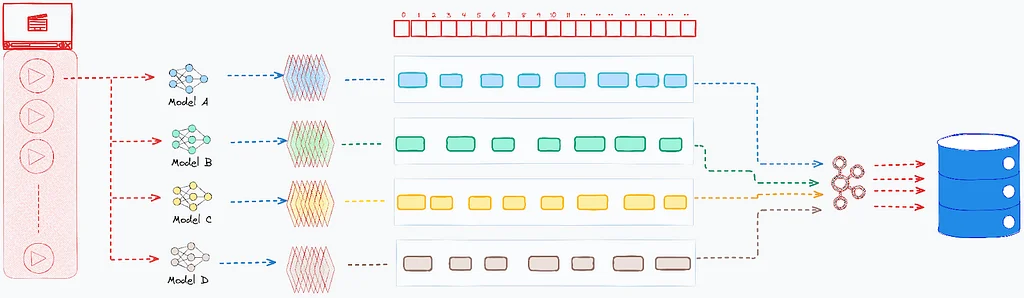
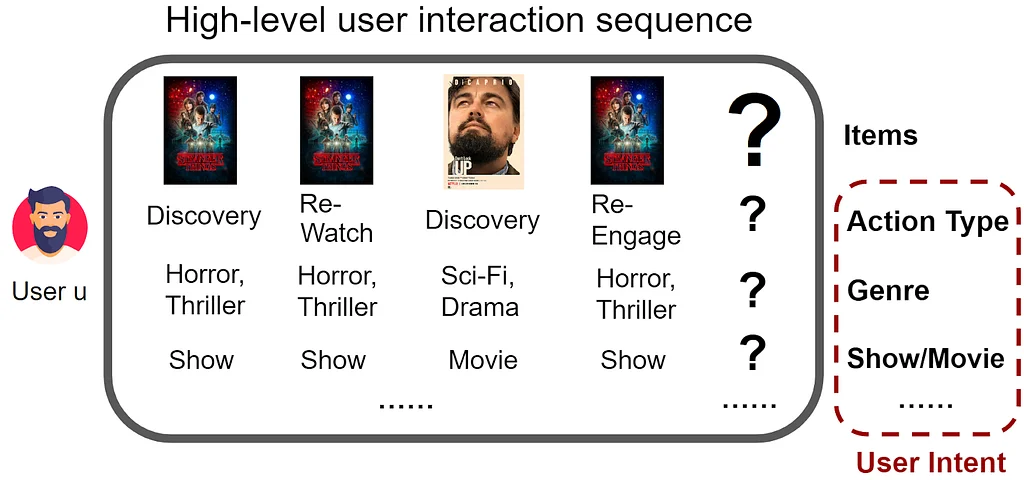
Video Annotator (VA) は、ビデオ分類器のトレーニングに関する課題に対処するフレームワークです。VA は、ビジョン言語モデルとアクティブラーニングを使用し、ドメインエキスパートがプロセスを導くことができます。
VA は、3つのステップで構成されています:テキスト・トゥ・ビデオ・サーチを使用して初期の例を探し、ヒューマン・イン・ザ・ループ・システムを使用してアクティブラーニングとアノテーションの改善を行い、反復的にアノテーションをレビューし改善します。
VA は、サンプル効率を向上させ、コストを削減し、モデル品質を改善します。ドメインエキスパートがアノテーションプロセスに直接関与することを可能にし、信頼と所有権を育む。
VA のアクティブラーニングは、ユーザーが徐々に困難な例に焦点を当てることを許し、アノテーション時間を短縮し、モデル性能を向上させます。
VA は、継続的なアノテーションをサポートし、急速なデプロイメント、監視、およびエッジケースの訂正を可能にします。VA は、ユーザーがデータ・サイエンティストやサードパーティのアノテーターや頼らずにモデルを改善し反復することを可能にします。
実験結果は、VA が従来の分類器トレーニング技術と比較して、より高品質のビデオ分類器を生成することを示しています。
VA は、多様なビデオ理解タスクの効率的なアノテーションを可能にし、ドメインエキスパートと機械学習エンジニアの協力関係を促進します。
著者は、VA を使用してアノテーションされた 56 タスクの 153k ラベルが含まれるデータセットを提供し、レプリケーションのためのコードもリリースします。
VA は、従来の分類器トレーニング技術の課題に対処し、ビデオアノテーションの効率、品質、ユーザー関与を向上させます。VA は、システムに対する信頼と所有権を育むことで、正確なビデオ分類器の急速なデプロイメントと反復的な改善を促進します。