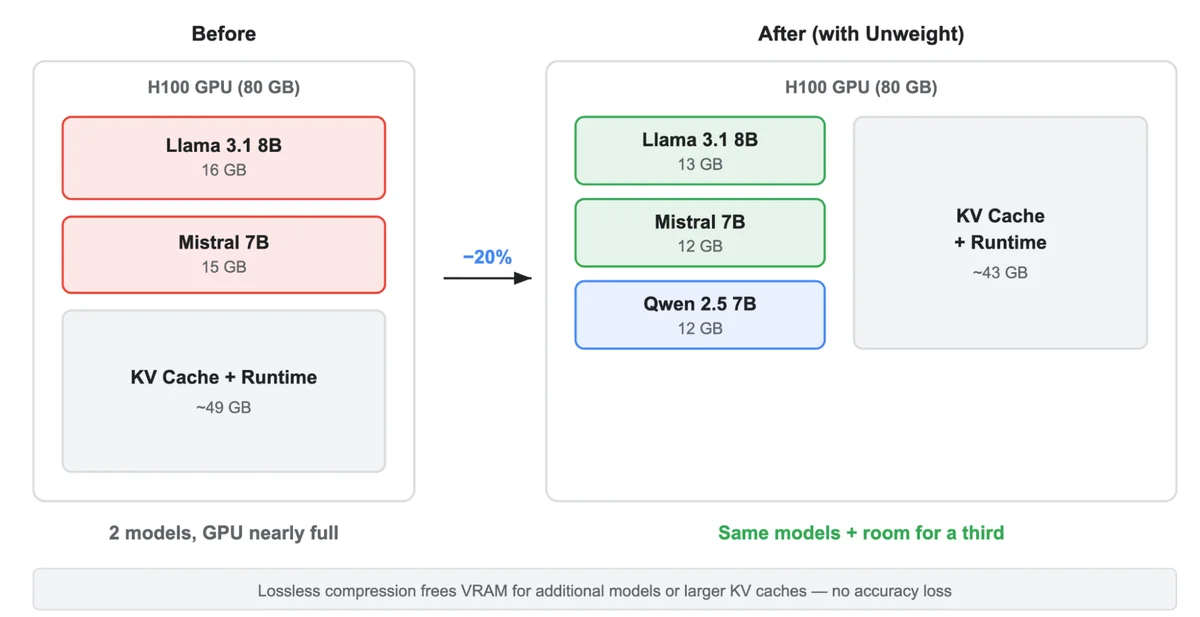
RSS 클라우드플레어 블로그 팔로우 무게 낮추기: 품질을 희생하지 않고 22% 압축된 대형 언어 모델 클라우드플레어의 네트워크에서 대규모 언어 모델(LLM)을 실행하려면 GPU 메모리 대역폭에 대해 더 똑똑하고 효율적으로 작동해야 합니다. 바로 이러한 이유로 우리는 이전보다 더 빠르고 저렴한 추론을 제공할 수 있도록 최대 22%의 모델 크기 감소를 달성하는 무손실 추론 시간 압축 시스템인 Unweight를 개발했습니다. AI and ML News on Bluesky @ai-news.at.thenote.app bsky.app Unweight: how we compressed an LLM 22% without sacrificing quality blog.cloudflare.com