Netflix의 TimeSeries Abstraction은 Apache Cassandra를 스토리지로 사용하여 밀리초 지연 시간으로 페타바이트 규모의 시간 이벤트 데이터를 수집하고 쿼리합니다. 단일 파티션이 시간이 지남에 따라 대량의 이벤트를 축적하는 와이드 파티션은 TimeSeries 워크로드에 상당한 문제를 야기합니다. 이는 Cassandra 클러스터에서 높은 읽기 지연 시간, 타임아웃, CPU 사용량 증가 및 가비지 컬렉션 일시 중단을 초래합니다. 이를 해결하기 위해 TimeSeries 데이터는 개별 시간 청크로 분할되어 관리 가능한 세그먼트를 생성합니다.
초기 프로비저닝 전략은 사용자 지정 워크로드 특성과 몬테카를로 시뮬레이션을 사용하여 최적의 인프라 및 파티션 구성을 결정하는 데 의존했습니다. 그러나 이 접근 방식은 워크로드를 알 수 없거나, 부정확하게 추정하거나, 시간이 지남에 따라 진화하거나, 데이터 이상치를 포함하는 경우 불충분했습니다. 조정을 자동화하기 위해 백그라운드 워커를 도입하여 파티션 히스토그램을 모니터링하고 관찰된 데이터 밀도를 기반으로 향후 시간 슬라이스를 동적으로 재분할했습니다. 이 Time Slice Re-Partitioning 전략은 대부분의 데이터가 유사한 와이드 파티션 동작을 보일 때 읽기 지연 시간과 타임아웃을 효과적으로 줄입니다.
그러나 이 전략은 테이블 내 ID의 작은 비율만 와이드한 시나리오를 해결하지 못합니다. 이러한 경우와 호출자가 높은 지연 시간에도 불구하고 모든 데이터를 필요로 하는 경우, Dynamic Partitioning per ID가 개발되었습니다. 이 비동기 파이프라인은 읽기 작업 중에 와이드 파티션을 감지하고 투명하게 최적의 크기로 분할합니다. 이 프로세스는 감지, 계획 및 분할, 분할된 파티션으로 쿼리를 재라우팅하여 읽기를 제공하는 것을 포함합니다.
감지는 구성된 바이트 임계값을 초과하는 읽기 작업이 발생할 때 이루어지며, Kafka로 이벤트를 내보냅니다. 시스템은 단순성을 위해 처음에 불변 파티션에 집중합니다. 계획 단계에서는 전체 파티션을 읽어 분할 계획을 생성하며, 체크포인팅을 사용하여 실패를 처리합니다. 분할은 이벤트 버킷을 시간 버킷에 할당하는 것과 같은 특정 전략에 데이터 분할을 위임하는 것을 포함합니다. 분할을 검증하는 것이 중요하며, 체크섬은 분할이 완료된 것으로 표시하기 전에 데이터 무결성을 보장합니다. 마지막으로 TimeSeries 서버는 인메모리 Bloom 필터를 사용하여 읽기 쿼리를 분할된 파티션으로 효율적으로 전환하여 호출자에게 거의 눈에 띄지 않게
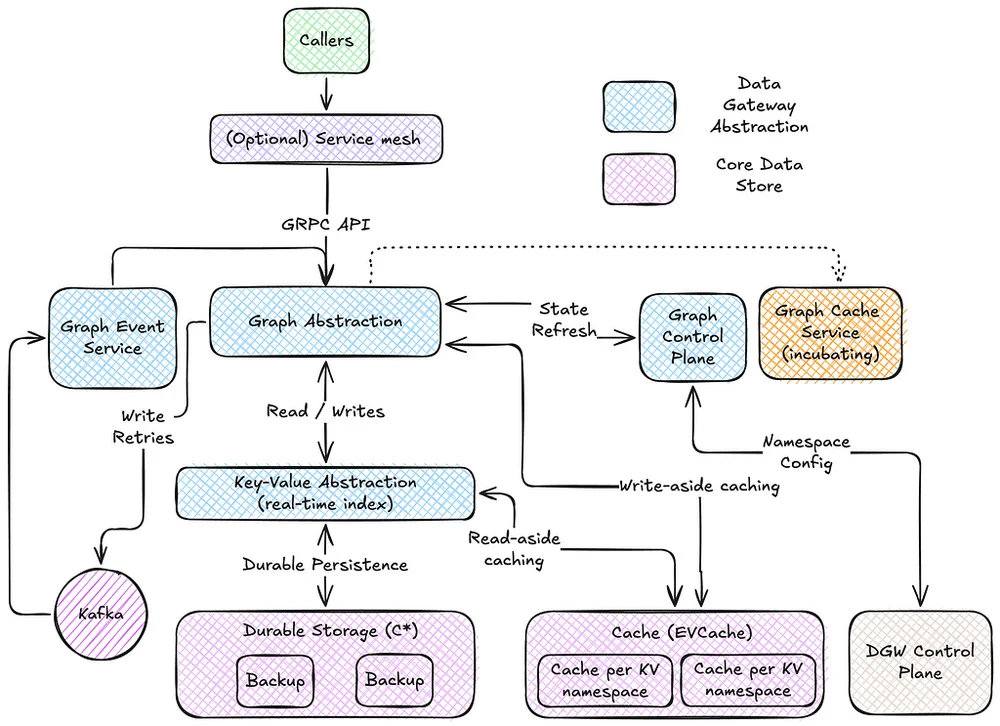
Netflix는 실시간 분산 그래프 및 소셜 그래프와 같은 사용 사례에 특히 활용하기 위해 고처리량, 저지연 그래프 작업을 처리하기 위한 그래프 추상화를 구축했습니다. 이는 심층 분석을 위한 OLAP와 스트리밍 사용자 경험을 위한 OLTP의 두 가지 범주 내에서 작동합니다. 이 추상화는 강력하게 타입화된 노드와 엣지를 가진 속성 그래프 모델을 사용하며, 격리된 네임스페이스로 구성됩니다. 각 네임스페이스는 데이터 게이트웨이 제어 플레인을 통해 관리되는 사전 정의된 그래프 스키마를 가지고 있습니다. 이 스키마는 데이터 품질 강제 및 효율적인 쿼리 계획과 같은 최적화를 가능하게 합니다. 실시간 인덱스는 노드와 엣지를 위해 키-값 스토리지를 사용하며, 링크와 속성에 대해 별도의 인덱스를 사용합니다. 엣지 링크는 소스-대상 관계별로 인덱싱됩니다. 방향에 관계없이 액세스를 보장하기 위해 식별자를 사전순으로 구성합니다. 캐싱은 쓰기 및 읽기 증폭을 최소화하는 데 사용됩니다. 추상화 아키텍처는 고성능을 우선시하며 쓰기 분리 캐싱과 같은 전략을 통합합니다.
Netflix는 엔지니어들이 서비스 종속성을 이해하고 문제를 해결하는 데 도움을 주기 위해 Service Topology라고 불리는 분산 인프라의 "살아있는 지도"를 개발했습니다. 이 지도는 서비스 관계와 장애 발생 시 잠재적 영향을 더 빠르게 식별해야 하는 필요성을 해결합니다. 이는 어떤 서비스가 서로에게 의존하는지, 그리고 문제의 근원을 파악하는 것과 같은 중요한 질문에 답합니다. 그들은 eBPF 네트워크 흐름, IPC 메트릭, 엔드투엔드 추적의 세 가지 소스에서 데이터를 수집했습니다. 각 데이터 소스는 고유한 관점을 제공합니다. 즉, 네트워크 연결성, 애플리케이션 수준의 세부 정보, 실제 요청 흐름입니다. 이 다층 아키텍처는 이러한 뷰를 통합된 실시간 지도로 결합합니다. 시스템은 각 데이터 소스에 대해 별도의 그래프 데이터베이스를 사용하여 독립성을 유지하고 병렬 쿼리를 가능하게 합니다. 엔지니어들은 각 그래프를 개별적으로 보거나 결합하여 서비스 상호 작용에 대한 포괄적인 이해를 얻을 수 있습니다. 시스템은 여러 지역의 Kafka에서 흐름 로그를 수집하고, 처리하고, 그래프 데이터베이스에 데이터를 저장합니다. 이 살아있는 지도는 Netflix 엔지니어들이 문제를 신속하게 진단하고 해결하여 원활한 스트리밍 경험을 보장하는 데 도움이 됩니다.
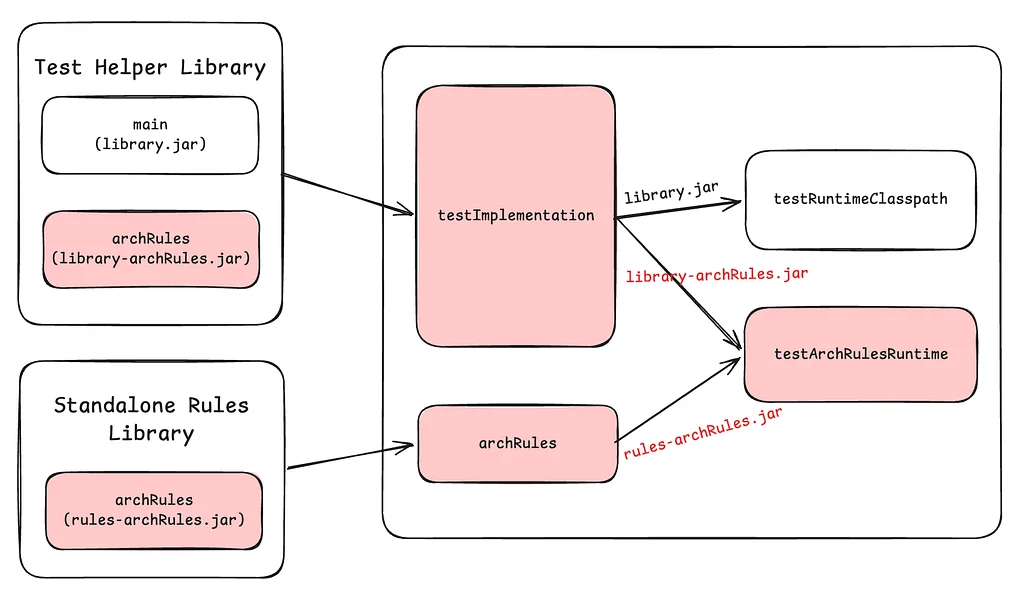
Netflix는 수천 개의 Java 리포지토리를 사용하는 폴리 리포(polyrepo) 전략을 사용하며, 효율적인 빌드 로직 공유가 필요합니다. 이들은 종속성을 관리하고 코드 표준을 강제하기 위해 ArchRules를 포함한 Nebula Gradle 플러그인 제품군을 구축했습니다. 이 이니셔티브는 이전 버전과 호환되지 않는 변경 사항 사고 이후 Java 라이브러리 수명 주기 관리를 개선해야 할 필요성에서 비롯되었습니다. Netflix는 API 수명 주기 주석(@Deprecated, @Public, @Experimental)을 활용하여 폐기된 코드의 잠재적인 문제를 식별합니다. 아키텍처 규칙을 강제하는 데 널리 사용되는 라이브러리인 ArchUnit은 이러한 주석의 오용 및 기타 기술 부채 문제를 감지하기 위해 선택되었습니다. Nebula ArchRules 플러그인을 통해 여러 리포지토리에 걸쳐 ArchUnit 규칙을 공유하고 적용할 수 있으며, 향상된 기능을 제공합니다. ArchRules는 언어 간 지원을 위해 바이트코드 분석(ASM)을 사용하고, 규칙 생성을 단순화하는 사용하기 쉬운 빌더 패턴을 사용합니다. 규칙은 라이브러리와 함께 번들링되거나 독립적인 규칙 라이브러리에 정의될 수 있으며, 플러그인에 의해 자동으로 감지되고 실행됩니다. ArchRules Runner 플러그인은 소스 세트에 대해 규칙을 평가하고 JSON 및 콘솔 보고서를 생성하여 더 나은 보고 기능을 제공합니다. ArchRules를 사용함으로써 Netflix는 라이브러리 작성자가 API 사용을 추적하고 폐기된 API 사용을 감지할 수 있는 플랫폼을 제공합니다.
Netflix는 개인화, 스튜디오 제작, 결제, 광고와 같은 다양한 비즈니스 도메인에 걸쳐 머신러닝을 활용합니다. ML 채택이 증가함에 따라 모델과 데이터가 사일로화되어 협업과 검색을 방해하는 파편화된 환경이라는 문제가 발생했습니다. ML 실무자들은 다양한 시스템에 걸쳐 모델 계보, 기능 소스 및 영향을 이해하는 데 어려움을 겪었습니다. 이러한 파편화로 인해 기존 기능, 데이터 소스, 파이프라인 종속성 및 변경 효과에 대한 질문에 쉽게 답할 수 없었습니다.
핵심적인 어려움은 메타데이터를 생성하는 분산된 ML 인프라 구성 요소를 연결하는 데 있었습니다. 파이프라인 오케스트레이터부터 실험 플랫폼 및 기능 스토어에 이르기까지 수십 개의 시스템이 다양한 형식으로 데이터를 생성했습니다. 이를 해결하려면 이기종 메타데이터를 수집하고, 이를 통합된 모델로 변환하고, 탐색을 위한 연결된 그래프를 구축해야 했습니다.
해결책은 Netflix에서 ML 엔티티를 상호 연결하는 모델 수명 주기 그래프를 구축하는 메타데이터 서비스(MDS)입니다. MDS는 ML 메타데이터를 실시간으로 수집하여 특정 모델을 사용하는 실험을 식별하거나 특정 기능을 공유하는 모델과 같은 도메인 간 쿼리를 가능하게 합니다. 비전은 모든 ML 자산을 회사 전체에서 검색 가능하고, 이해 가능하며, 재사용 가능하게 만드는 것입니다.
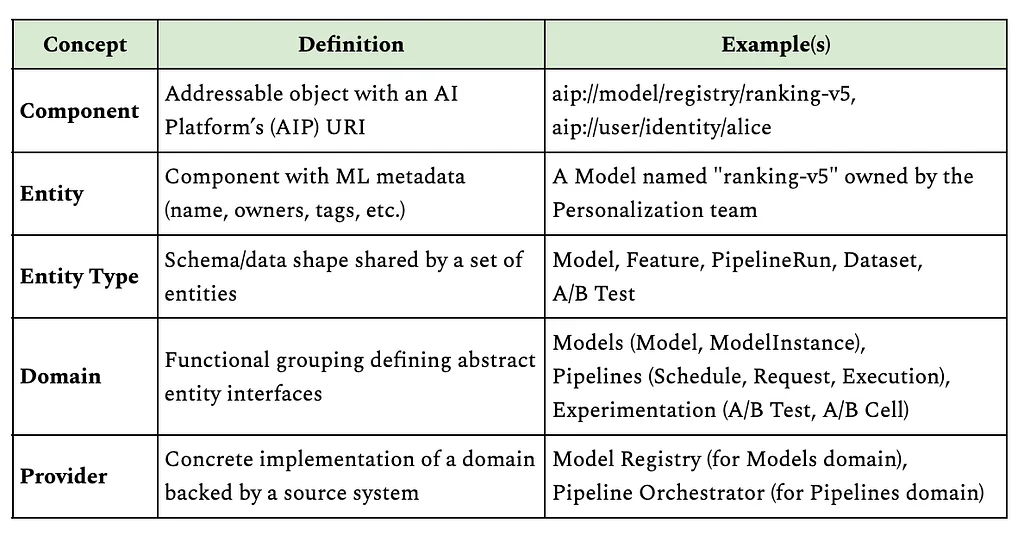
MDS는 고유한 AIP URI를 가진 구성 요소, 속성을 가진 ML별 자산인 엔티티, 데이터 모양을 정의하는 엔티티 유형, 관련 엔티티 유형을 그룹화하는 도메인, 소스 시스템의 도메인에 대한 구체적인 구현인 공급자와 같은 핵심 추상화를 기반으로 작동합니다. 이 URI 기반 주소 지정 방식을 통해 모든 서비스가 모든 ML 자산을 보편적으로 참조할 수 있습니다. 그래프를 구축하는 과정은 여러 단계를 거칩니다.
첫째, MDS는 Kafka 및 AWS SNS/SQS를 통해 소스 시스템과 통합하여 변경 사항을 나타내는 얇은 이벤트를 소비합니다. 전용 이벤트 핸들러는 파이프라인 오케스트레이션, 모델 레지스트리, 기능 스토어, 실험 플랫폼, ID 플랫폼과 같은 시스템의 이벤트를 처리합니다. 둘째, MDS는 수분 계약을 구현하여 이벤트를 검증하고 소스 시스템 API를 호출하여 전체 상태를 가져온 다음, 이를 정규화된 엔티티로 변환합니다. 이 "변경 알림" 패턴은 이벤트 순서 문제에 대한 견고성을 보장하지만 소스 시스템에 읽기 부하를 줍니다.
셋째, 원시 이벤트는 표준화된 필드를 가진 통합 엔티티 모델로 변환되어 다운스트림 소비자에게 일관된 인터페이스를 생성합니다. 정규화된 엔티티는 필드 이름, 형식을 표준화하고 플랫폼별 ID를 전역 AIP URI로 변환합니다. 마지막으로 정규화된 엔티티는 캐싱 및 관계 저장을 위해 Datomic에 지속되고 동시에 Elasticsearch에 인덱싱됩니다. 불변 사실 모델을 가진 Datomic은 복잡한 그래프 순회 및 엔티티 관계를 지원하여 비효율적인 N+1 쿼리 패턴 없이 여러 도메인에 걸친 쿼리를 가능하게 합니다.
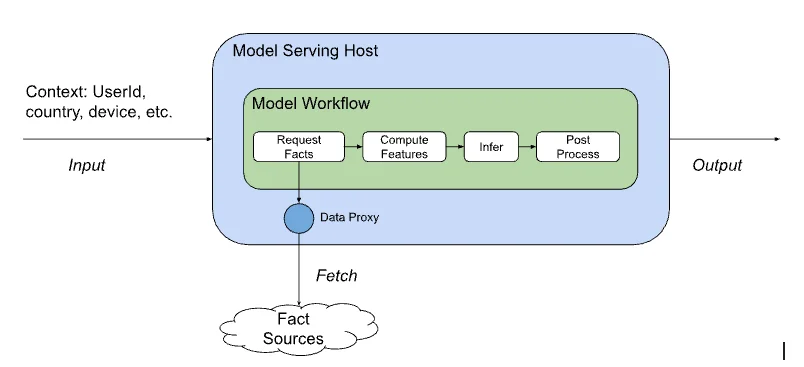
이 블로그 게시물은 Netflix의 ML 모델 서빙 인프라가 다양한 도메인에 걸쳐 대규모 개인화된 경험을 어떻게 지원하는지에 대한 기술적인 통찰력을 논의합니다. 중앙 ML 모델 서빙 플랫폼은 모델 추론을 위해 여러 도메인별 마이크로서비스에 도메인 독립적인 API 추상화 및 트래픽 라우팅 기능을 제공합니다. 이 단일 API는 기존 ML 경험의 최신 버전을 반복하는 혁신 속도를 높이고 ML을 통한 새로운 제품 경험을 가능하게 했습니다. ML 모델 서빙 인프라의 성공은 연구자들이 새로운 가설을 신속하게 실험하고 모델을 프로덕션에 안전하게 출시할 수 있도록 하는 데 달려 있습니다. 이 플랫폼은 수백 가지의 모델 유형과 버전을 처리하며 초당 100만 건의 요청을 처리하고, 개별 채점 함수뿐만 아니라 워크플로 수준에서 작동합니다.
모델 정의에는 기능을 계산하는 데 필요한 사실 목록이 포함되어 있으며, 서빙 시점에 여러 다른 마이크로서비스를 호출하여 이러한 사실을 제공하도록 모델 서빙 플랫폼에 의존합니다. 호출하는 서비스는 표준 요청 컨텍스트와 관련 도메인 컨텍스트만 제공하면 되며, 모델 자체는 실행 흐름의 일부로 기능을 계산하고 추론을 수행할 수 있습니다. 이 플랫폼은 신속한 ML 혁신의 촉진자 역할을 하며 클라이언트 앱에 대한 ML 모델 반복의 노출을 제한합니다. 플랫폼의 핵심 원칙에는 클라이언트 앱과 독립적인 모델 혁신, 클라이언트를 모델 샤딩에서 분리, 유연한 트래픽 라우팅 규칙이 포함됩니다.
이 플랫폼은 Switchboard라는 사용자 정의 서비스를 사용하며, 이는 초당 100만 건 이상의 요청을 처리하면서 높은 가용성과 신뢰성을 유지하는 모든 트래픽에 대한 유연한 프록시 계층 역할을 합니다. Switchboard는 모든 클라이언트의 모델 요구에 대한 단일 접점을 제공하며 풍부한 컨텍스트 기능 세트를 기반으로 요청을 라우팅할 수 있습니다. 이 플랫폼은 또한 "Objective"라는 개념을 도입하는데, 이는 서빙 플랫폼에서 정의한 열거형으로 시스템에 대한 모든 요청이 제공해야 합니다. Objective는 클라이언트를 구체적인 모델에서 분리하고 플랫폼의 라우팅 및 모델 선택 결정을 안내합니다.
Switchboard Rules는 연구자들이 클라이언트 코드를 변경하지 않고도 Objective에 모델 변형, 실험 및 트래픽 분할을 연결할 수 있도록 하는 JavaScript 구성입니다. 규칙은 주어진 Objective에 대한 기본 모델, 일련의 Objective에 대한 A/B 실험 구성, 새 모델로 트래픽을 점진적으로 전환하기 위한 사용자 정의를 지시합니다. 규칙은 Switchboard와 Model Serving 클러스터 모두에서 사용되며, 서빙 플랫폼 구성 요소는 이러한 규칙을 기반으로 다양한 작업을 수행할 수 있습니다. 전반적으로 이 플랫폼은 Netflix에서 ML 모델을 서빙하기 위한 확장 가능하고 유연한 솔루션을 제공하여 클라이언트 앱에 대한 영향을 최소화하면서 신속한 혁신과 실험을 가능하게 합니다.
Netflix는 전 세계 프로덕션의 미디어 워크플로우를 간소화하기 위해 Media Production Suite(MPS)를 구축했으며, 효율성과 일관성을 목표로 합니다. MPS의 핵심은 이미지 처리를 위해 FilmLight의 API(FLAPI)를 활용하며, 이는 모든 것을 처음부터 구축하는 것을 피하는 협업입니다. MPS는 파일 관리 및 일관되지 않은 미디어 처리와 같은 문제를 해결하고, 작업을 자동화하며 오류를 최소화합니다. FLAPI는 카메라 파일 메타데이터를 검사하고, 이를 정규화하며, 검색 가능하게 만들어 일관성을 보장합니다. FLAPI는 또한 정확한 색상 관리 및 디베이어링을 통해 VFX 플레이트와 결과물을 생성합니다. MPS는 Cosmos를 사용하여 클라우드에 통합되며, Docker화된 환경에서 CPU 전용 인스턴스를 사용할 수 있어 효율성을 극대화합니다. 프로덕션 워크로드는 필요에 따라 확장 가능하도록 탄력적으로 처리되어 빠른 처리 시간을 보장합니다. MPS는 숙련된 팀과 안내가 필요한 팀 모두를 위해 설계되었으며, FLAPI가 복잡성을 처리합니다. 이 파트너십은 개방적인 소통, 공동 검증을 가능하게 하며 표준화 생태계에 이점을 제공합니다. 전반적인 영향은 지연 감소, 처리 시간 단축, 그리고 보다 효율적인 프로덕션 프로세스입니다.
인프라의 인간적인 면모: 넷플릭스가 어떻게 라이브 서비스를 위한 대규모 운영 레이어를 구축했는가
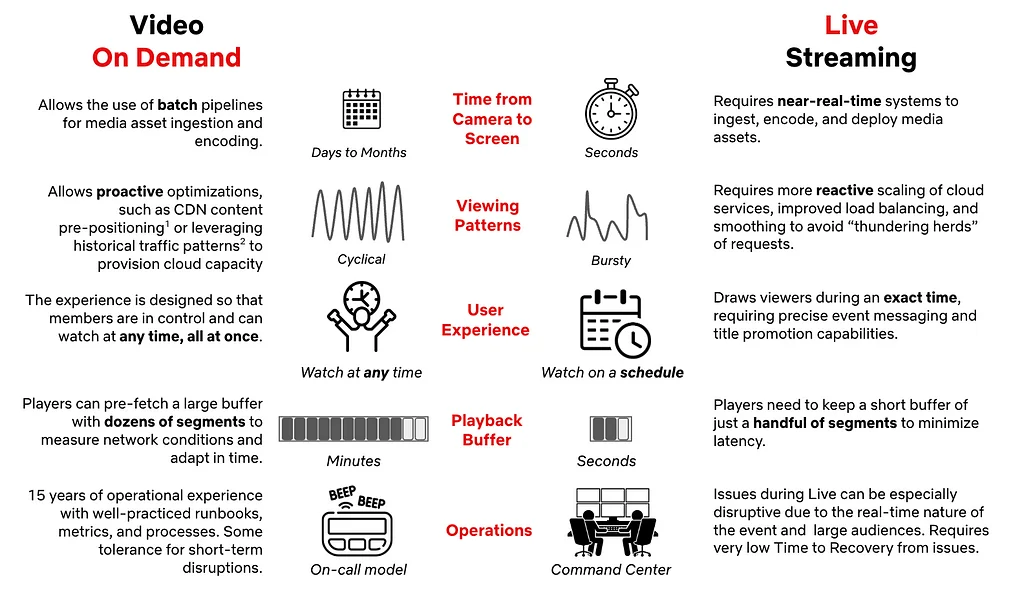
넷플릭스의 라이브 스트리밍 운영은 첫 라이브 쇼 이후 급속도로 확장되어 현재 매일 여러 이벤트를 스트리밍하고 있습니다. 초기 라이브 쇼는 엔지니어와 즉흥적인 설비에 의존했으며, 전담 운영팀이 부족했습니다. 이러한 발전은 라이브 방송 프로세스를 관리하기 위한 전담 방송 운영 센터(BOC) 구축을 필요로 했습니다. 신호 안정성을 보장하기 위해 넷플릭스는 행사장에서 제공되는 비디오 및 오디오 피드에 대해 엄격한 사양을 적용합니다. 넷플릭스의 운영 모델은 엔지니어링 주도 운영에서 전문 엔지니어링 팀으로 여러 단계를 거쳐 발전했습니다. 전송 운영 센터(TOC) 모델은 효율성을 개선하고 많은 양의 이벤트를 동시에 관리하기 위해 개발되었습니다. TOC 모델 내에서 전송, 스트리밍, 방송 제어 운영자와 같은 역할이 중요합니다. 주요 이벤트의 경우, 전문적인 "빅 베팅" 모델이 전담 리소스를 제공합니다. 라이브 커맨드 센터(LCC)는 전체 라이브 스트리밍 파이프라인을 모니터링하여 운영자에게 실시간 데이터를 제공합니다. LCC는 대량의 데이터를 관리하고 문제에 신속하게 대응하기 위해 맞춤형 관찰 스택을 사용합니다. LCC 운영 리드 및 기술 런칭 매니저는 사고 대응을 담당합니다.
넷플릭스는 방대한 콘텐츠 라이브러리의 시놉시스 선정 프로세스를 개선하고자 합니다.
수천 개의 타이틀은 사용자의 선택을 복잡하게 만들며, 시놉시스는 의사 결정에 중요한 역할을 합니다.
고품질 시놉시스는 사용자 참여를 높이는 반면, 저품질 시놉시스는 좌절감과 이탈로 이어집니다.
과제는 수십만 개의 시놉시스에 걸쳐 품질 검증을 확장하는 데 있습니다.
넷플릭스는 네 가지 핵심 차원에서 시놉시스 품질을 평가하기 위해 LLM 기반 접근 방식을 개발했습니다.
이 시스템은 창작 작가들과 85% 이상의 일치율을 달성하여 전문가 주도의 품질 표준을 보장합니다.
시놉시스 품질은 작가들이 정의한 창의적 품질과 스트리밍 지표를 통한 회원들의 암묵적 피드백을 통해 평가됩니다.
LLM-as-a-Judge 시스템은 정확도를 최적화하기 위해 계층적 근거, 합의 점수, 사실성 에이전트와 같은 기술을 사용합니다.
이러한 LLM에서 파생된 품질 점수는 취득률 및 이탈률과 같은 주요 스트리밍 지표와 상관 관계가 있습니다.
이를 통해 넷플릭스는 시놉시스 문제를 사전에 파악하고 수정하여 회원 경험과 콘텐츠 검색을 개선할 수 있습니다.
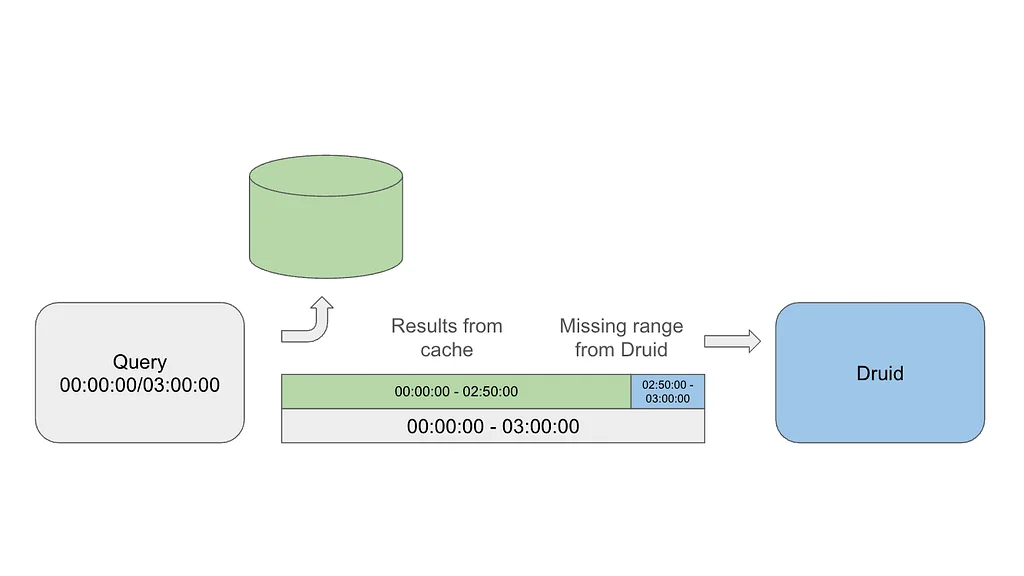
넷플릭스는 대규모 환경에서 Druid 쿼리 성능을 향상시키기 위해 실험적인 캐싱 레이어를 구현했습니다. 이 캐싱 시스템은 특히 대규모 이벤트 발생 시 대시보드에서 발생하는 중복 쿼리 문제를 해결합니다. 핵심 아이디어는 결과의 일부를 캐싱하고, 가장 최신 데이터에 대해서만 Druid에 쿼리하여 약간의 오래된 데이터(staleness)를 감수하는 것입니다. 지수 시간-생존(TTL) 값을 사용하여, 늦게 도착하는 이벤트를 처리하기 위해 오래된 데이터는 더 오래 캐싱됩니다. 캐싱 시스템은 캐시된 데이터의 효율적인 범위 스캔을 위해 맵-오브-맵 구조를 사용합니다. 캐시는 Druid 라우터에서 요청을 가로채 필요에 따라 결과를 제공하거나 Druid에 쿼리합니다. 이 솔루션은 캐시된 데이터와 최신 데이터를 결합하여 완전한 결과를 반환하고, 최신 데이터를 비동기적으로 캐싱합니다. 빈 버킷에 대한 부정 캐싱(negative caching)이 사용되며, 후행 빈 버킷을 캐싱하는 것에 대한 예방 조치가 취해집니다. 이 시스템은 넷플릭스의 키-값 데이터 추상화 계층(KVDAL)을 사용하며, Cassandra를 기반으로 하여 각 데이터 포인트에 대해 독립적인 TTL을 제공합니다. 캐싱 레이어는 Druid 쿼리 부하를 크게 줄이고 쿼리 시간을 개선했으며, 특히 대량의 이벤트 발생 시 효과가 컸습니다. 이 캐싱 시스템은 아직 실험 단계에 있으며, 향후 목표는 Druid 자체에 통합하는 것입니다.
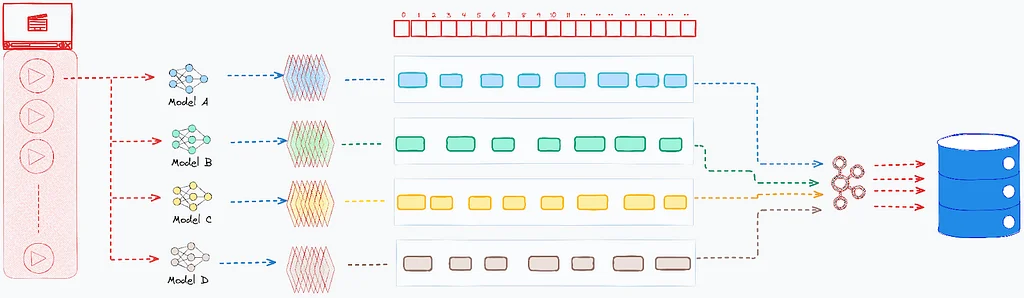
이 기사는 고급 비디오 검색 엔진 구축에 대한 과제와 해결책을 논의합니다. 핵심 문제는 방대한 양의 비디오 영상과 관련 순간을 추출하는 어려움입니다. 해결책은 다양한 AI 모델을 통합하여 비디오 콘텐츠의 여러 측면을 분석하는 다중 모드 접근 방식입니다. 이 접근 방식은 전문 모델에서 얻은 다양한 데이터를 일관된 실시간 인텔리전스 시스템으로 통합해야 합니다. 시스템 아키텍처는 대규모 처리에 중점을 두고 있으며, 수십억 개의 데이터 포인트를 효율적으로 처리합니다. 트랜잭션 지속성, 오프라인 데이터 융합, 실시간 검색을 위한 인덱싱을 포함하는 3단계 프로세스는 데이터 무결성과 응답성을 보장합니다. 이 프로세스는 데이터 수집 과정에서 병목 현상을 방지하기 위해 분리된 파이프라인을 사용합니다. 검색 서비스는 쿼리 전처리, 의미 검색 미세 조정, 정확한 결과를 위한 고급 텍스트 분석과 같은 기능을 제공합니다. 또한 검색 정확도를 향상시키기 위해 구문 일치, N-gram 분석, 퍼지 일치를 포함합니다. 시스템은 보다 미묘한 검색을 가능하게 하기 위해 집계 및 유연한 그룹화를 제공합니다. 전반적으로 목표는 관련 비디오 콘텐츠를 발견할 수 있는 강력한 도구를 제공하여 영화 제작자를 지원하는 것입니다.
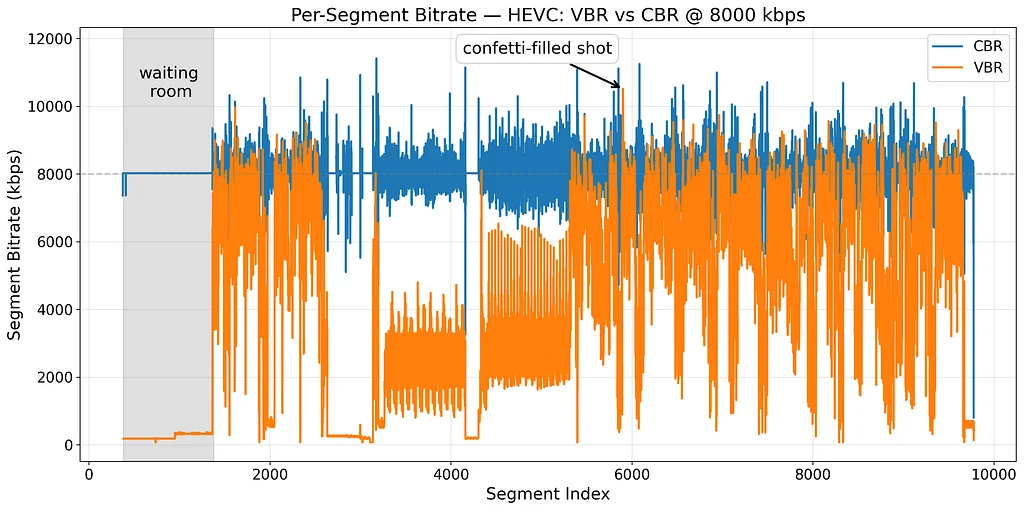
넷플릭스는 효율성 향상을 위해 라이브 이벤트를 고정 비트 전송률(CBR)에서 가변 비트 전송률(VBR) 인코딩으로 전환했습니다. VBR은 장면의 복잡성에 따라 비트 전송률을 동적으로 조정하여 평균 트래픽을 줄이고 사용자 경험의 품질을 향상시킵니다. VBR의 주요 과제는 트래픽의 예측 불가능성으로, 이는 큰 비트 전송률 변동으로 인해 서버 과부하 및 불안정성을 초래할 수 있습니다. 이를 해결하기 위해 넷플릭스는 공칭 비트 전송률을 기반으로 하는 새로운 용량 예약 시스템을 구현하여 VBR의 가변적인 특성과 관련된 위험을 완화했습니다. 또한 VMAF를 지표로 사용하여 CBR 스트림의 품질에 맞춰 스트리밍 계층 전반의 공칭 비트 전송률을 조정했습니다. VBR로의 전환은 버퍼링 감소 및 초기 시작 지연 감소와 같은 효율성 향상을 가능하게 했습니다. 넷플릭스는 현재 VBR을 더욱 최적화하기 위해 적응형 비트 전송률 알고리즘과 용량 예약을 개선하기 위해 노력하고 있습니다. VBR의 구현은 여러 팀과 기여자가 참여한 회사 전체의 프로젝트였습니다.
"3년 전, 넷플릭스는 텔레비전만큼이나 오래된 형식인 라이브 스트리밍을 통해 전 세계를 어떻게 즐겁게 할 수 있는지 물었습니다. 이 질문은 코미디 쇼, 스포츠, WWE 이벤트를 포함한 수백 개의 라이브 이벤트 개발로 이어졌습니다. "Behind the Streams"라는 시리즈에서 넷플릭스는 라이브 스트리밍 기능을 구축하는 기술적 여정을 공유할 예정입니다. 라이브 스트리밍은 아키텍처 및 기술 선택에 대한 새로운 고려 사항을 도입했으며, 넷플릭스에서 잘 작동하도록 만들기 위해 상당한 구축이 필요했습니다. 넷플릭스의 라이브 아키텍처의 핵심 기둥에는 전용 방송 시설, 클라우드 기반의 중복 트랜스코딩 및 패키징 파이프라인, 라이브 콘텐츠 전달 확장, 라이브 재생 최적화, 클라우드에서 검색 및 재생 제어 서비스 실행이 포함됩니다. 넷플릭스는 또한 전문 도구와 시설을 사용하여 클라우드에서 실시간 메트릭을 중앙 집중화했습니다. 라이브 기능을 구축하는 것은 새로운 도전과 학습 기회를 가져왔으며, 넷플릭스는 여전히 라이브 이벤트를 더 효과적으로 제공하는 방법을 매일 배우고 있습니다. 지금까지의 주요 학습 내용은 광범위한 테스트, 정기적인 연습, 시청률 예측, 우아한 성능 저하 및 재시도 폭풍의 중요성입니다. 넷플릭스는 견고한 라이브 스트리밍 시스템 구축에 상당한 진전을 이루었지만, 여전히 배우고 개선해야 할 점이 많이 남아 있습니다."
Tudum.com는 넷플릭스의 공식 팬 대상지로, 매월 2000만 명 이상의 회원에게 독점 콘텐츠, 비하인드 스토리, 상호작용 경험을 제공합니다. 이 플랫폼의 아키텍처는 유지 가능, 확장 가능, 유연성을 위해 설계되었으며, Command Query Responsibility Segregation (CQRS)에 유사한 서버 주도 UI 접근 방식을 사용합니다. Tudum의 에디터리얼 팀은 콘텐츠를 생성하고, 이를 쓰기 데이터베이스에 저장한 후, 사용자들이 소비하는 읽기 최적화 형식으로 변환합니다. 초기 아키텍처는 Kafka를 사용하여 쓰기 및 읽기 데이터베이스를 분리하여 독립적인 확장 및 최종 일관성을 허용했습니다. 그러나 이 접근 방식은 콘텐츠 편집과 웹 사이트 반영 사이에 지연을 초래했습니다. 팀은 페이지 데이터 서비스의 근 캐시를 사용하여 페이지 구축을 가속화하는 데 사용되는 지연의 원인을 확인했습니다. 이 문제를 해결하기 위해 넷플릭스는 RAW Hollow, 즉 메모리 내, 공동위치, 압축 객체 데이터베이스를 개발했습니다. 이는 강한 읽기-쓰기 일관성 및 낮은 지연을 제공합니다. Tudum은 RAW Hollow를 테스트하는 완벽한 후보였으며, 이는 I/O를 크게 줄이고 O(1) 시간에 동기식 데이터 액세스를 가능하게 했습니다. 업데이트된 아키텍처는 Kafka 인프라의 필요성을 제거하고 데이터 전파 시간을 줄였으며, 작가 및 에디터가 초 단위로 변경을 미리 볼 수 있게 되었습니다. 마이그레이션은 또한 요청 시간을 줄였으며, 홈페이지 구축 시간이 1.4초에서 0.4초로 줄었습니다.
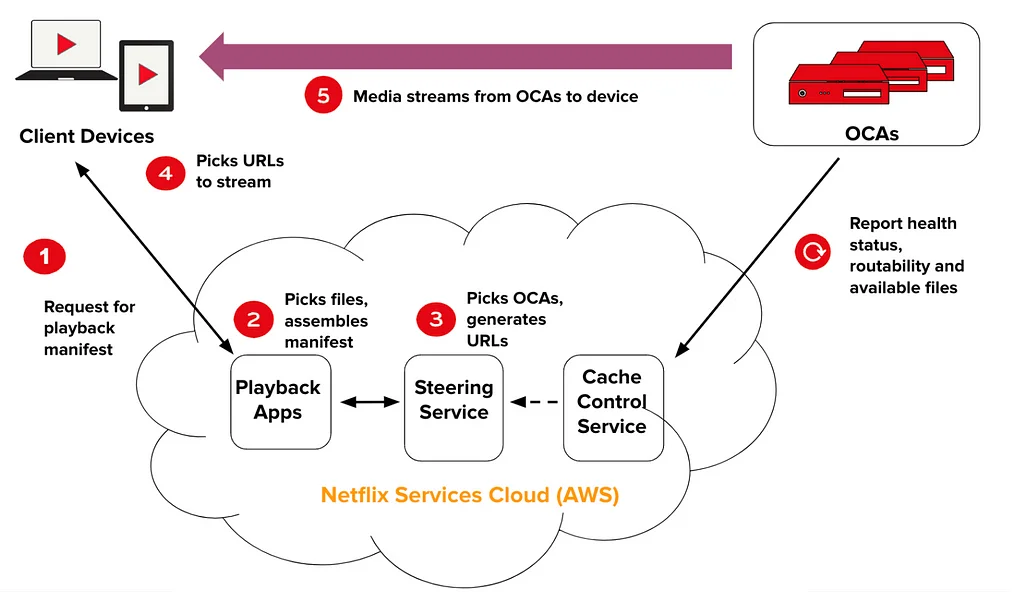
넷플릭스의 오픈 커넥트 프로그램은 인터넷 서비스 공급자(ISP)와의 파트너쉽을 통해 콘텐츠 전달을 지역화하여 회원들에게 최상의 경험(QoE)을 제공하는 콘텐츠 전달 네트워크(CDN)입니다. 이 프로그램은 효율성과 비용 효율성을 위해 특별히 설계된 서버인 오픈 커넥트 어플라이언스(OCAs)를 사용합니다. 오픈 커넥트의 효율성을 평가하기 위해 넷플릭스는 캐시 미스, 즉 클라이언트에게 가장 적절한 OCA에서 바이트가 제공되지 않는 경우를 식별하는 프레임워크를 사용합니다. 캐시 미스는 세 가지 카테고리로 분류됩니다. 콘텐츠 미스는 로컬 사이트의 OCA에 파일이 없는 경우, 헬스 미스는 로컬 사이트의 OCA 하드웨어 리소스가 포화된 경우, 기타 미스는 기타 경우입니다. 넷플릭스는 캐시 미스를 계산하기 위해 두 가지 중요한 데이터 컴포넌트를 로깅합니다. 스티어링 플레이백 매니페스트 로그와 OCA 서버 로그입니다. 이러한 로그는 다양한 집계 수준에서 캐시 미스 메트릭스를 계산하는 데 사용됩니다. 캐시 미스를 계산하는 시스템 아키텍처는 로그 발송, 로그 통합, 로그 강화, 스트리밍 창 기반 조인으로 구성됩니다. 캐시 미스를 평가하는 데이터 모델은 오프라인 및 시뮬레이션에서 변수 매개변수와 함께 논리를 재생할 수 있도록 허용하여 프로덕션 트래픽에 영향을 주지 않고 새로운 조건 및 기능을 테스트할 수 있습니다.
넷플릭스는 데이터 효율성을 최적화하면서도 영화적 질감의 예술적 무결성을 보존하는 AV1 필름 그레인 합성(FGS) 스트림을 도입했습니다. 필름 그레인은 스토리텔링의 핵심 요소로서 영화에 깊이와 사실감을 더하지만, 기존 알고리즘으로는 압축하기 어렵습니다. AV1 FGS 도구는 필름 그레인 패턴과 필름 그레인 강도라는 두 가지 구성 요소를 통해 필름 그레인을 모델링합니다. 필름 그레인 패턴은 자기 회귀 모델을 사용하여 복제되고, 필름 그레인 강도는 스케일링 함수에 의해 제어됩니다. 인코딩 과정에서는 비디오에서 필름 그레인을 제거하고 압축한 다음, 그레인의 패턴과 강도를 압축된 비디오 데이터와 함께 전송합니다. 재생 중에는 블록 기반 방법을 사용하여 필름 그레인을 다시 생성하여 비디오에 다시 통합합니다. AV1 FGS를 활성화하면 비트 전송률이 크게 줄어들어 더 적은 데이터로 고품질 비디오 스트리밍이 가능해졌습니다. 또한 합성된 노이즈가 압축 아티팩트를 효과적으로 가려 시각적 품질도 향상되었습니다. 넷플릭스는 플랫폼 전반에 걸쳐 FGS를 출시했으며, 이제 지원되는 장치에서 FGS 지원 스트림을 즐길 수 있습니다. 이 출시로 인해 넷플릭스 회원들은 더 낮은 비트 전송률, 감소된 재생 오류 및 향상된 재생 안정성을 통해 더 부드럽고 안정적인 품질의 경험을 누릴 수 있게 되었습니다.
Netflix의 서비스가 성장함에 따라 이를 지원하는 시스템의 복잡성도 증가하여 중복되고 일관되지 않은 모델, 일관되지 않은 용어, 데이터 품질 문제 및 데이터 간의 일관되지 않은 관계로 이어집니다. 이러한 문제를 해결하려면 모델을 한 번 정의한 후 해당 정의를 모든 곳에서 재사용하고, 개념을 실제 시스템에 연결하고 이러한 정의를 외부로 프로젝션하고, 스키마를 생성하고, 시스템 전반에 걸쳐 일관성을 적용할 수 있는 새로운 기반이 필요합니다. 이는 UDA(Unified Data Architecture)의 개발로 이어졌으며, 이 UDA는 도메인을 한 번 모델링하고 시스템 전반에 걸쳐 일관되게 표현하여 자동화, 검색 가능성 및 의미론적 상호 운용성을 강화합니다. UDA를 통해 사용자와 시스템은 도메인 모델을 등록 및 연결하고, 도메인 모델을 데이터 컨테이너에 카탈로그 및 매핑하고, 도메인 모델을 스키마 정의 언어로 변환하고, 데이터 컨테이너 간에 데이터를 충실하게 이동하고, 도메인 개념을 검색 및 탐색하고, 프로그래밍 방식으로 지식 그래프를 검사할 수 있습니다. UDA는 비즈니스 개념을 스키마 및 데이터 컨테이너에 연결하는 지식 그래프로, UDA에서 도메인 모델링을 위한 언어를 정의하는 Upper라는 사내 메타모델을 기반으로 합니다. Upper는 도메인과 그 개념을 공식적으로 설명하는 언어이며 데이터 컨테이너 표현 및 매핑을 모델링하는 데 사용됩니다. UDA는 명명된 그래프 우선 정보 모델을 채택하여 전체 그래프에서 해상도, 모듈성 및 거버넌스를 보장합니다.
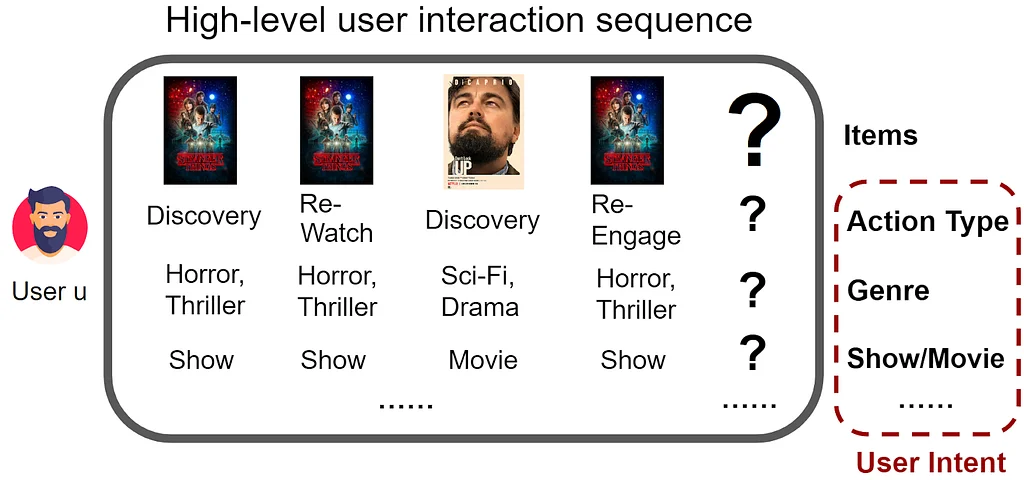
추천 시스템은 전자 상거래, 스트리밍 미디어, 소셜 네트워크의 필수 구성 요소로 제품 및 비즈니스에 큰 영향을 미칩니다. 넷플릭스에서는 이러한 시스템이 적절한 콘텐츠를 회원에게 적시에 제공합니다. 추천 기초 모델은 사용자 선호도를 이해하는 데 상당한 진전을 이루었습니다. 그러나 사용자 세션의 이해를 넘어 다음 항목 예측을 넘어선 사용자 의도 예측을 통합하여 모델의 기능을 추가로 향상시킬 수 있습니다. 최근 연구에서는 온라인 플랫폼에서 사용자 의도를 이해하는 것이 더 정확하고 개인화된 추천을 이끌어내는 데 중요하다는 것을 강조했습니다. FM-Intent는 새로운 추천 모델로, 사용자의 짧은 기간 및 장기적인 신호를 대리하여 잠재적인 사용자 의도를 포착하고, 이를 다음 항목 추천을 개선하는 데 사용합니다. 이 모델은 의도 예측과 다음 항목 추천 간에 계층적 관계를 설정하여 더 일관되고 효과적인 추천 파이프라인을 생성합니다. FM-Intent는 세 가지 주요 기여를 합니다. 새로운 추천 모델, 계층적 다중 작업 학습 접근 방식, 그리고 최첨단 모델보다 유의미한 개선 사항을 보여주는 포괄적인 실험 검증입니다. FM-Intent는 넷플릭스의 추천 생태계에 성공적으로 통합되어 있으며, 개인화된 UI 최적화, 분석 및 향상된 추천 신호와 같은 다양한 다운스트림 애플리케이션에 활용할 수 있습니다.
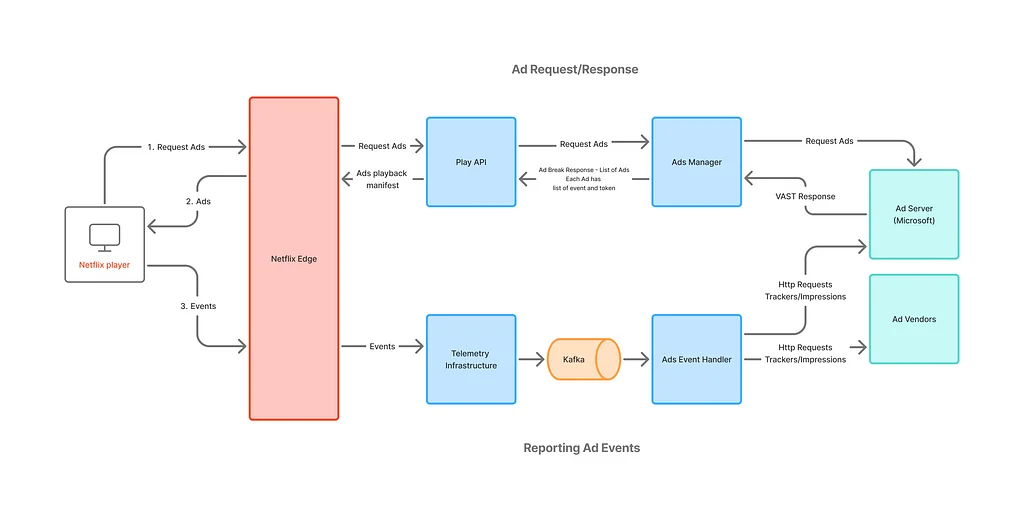
넷플릭스는 광고 캠페인을 모니터링, 측정 및 최적화하기 위해 강력한 이벤트 처리 플랫폼을 구축했습니다. 광고 서빙 시스템은 의사결정, 빈도 제한, 페이싱 및 개인화를 조정하기 위해 꾸준한 광고 이벤트 스트림에 의존합니다. 초기 광고 이벤트 처리 시스템은 마이크로소프트 광고 서버, 넷플릭스 광고 관리자 및 광고 이벤트 핸들러라는 세 가지 주요 구성 요소로 구성되었습니다. 이 시스템은 노출 수, 빈도 제한 및 수익 창출 프로세스에 대한 통찰력을 제공하여 피드백 루프가 효과적으로 작동하도록 설계되었습니다. 사업이 확장됨에 따라 데이터 볼륨 증가 및 타사 추적 URL과 같은 과제를 해결하기 위해 키-값 추상화를 사용하는 새로운 지속성 계층이 도입되었습니다. 이벤트 처리 파이프라인은 빈도 제한, 가격 정보 및 강력한 보고 시스템과 같은 기능을 통합하여 자체 광고 기술을 지원하도록 더욱 발전했습니다. 소비자에게 단일 통합 데이터 계약을 제공하고 상위 시스템과 소비자 간의 우려 사항을 분리하는 중앙 집중식 광고 이벤트 수집 시스템이 계획되었습니다. 새로운 파이프라인은 측정, 재무/청구, 보고, 빈도 제한 및 광고 서버로의 필수 피드백 루프 유지와 같은 다양한 기능을 지원했습니다. 광고 이벤트 처리 시스템의 개발은 다양한 팀 간의 팀워크, 계획 및 조정을 보여주는 신중하게 조율된 여정이었습니다. 새로운 시스템은 프로그래매틱 구매 기능 지원, 옵트아웃 신호 공유 및 정확한 보고 및 측정 보장을 통해 비즈니스를 위한 새로운 기능을 출시하는 능력을 크게 향상시켰습니다.
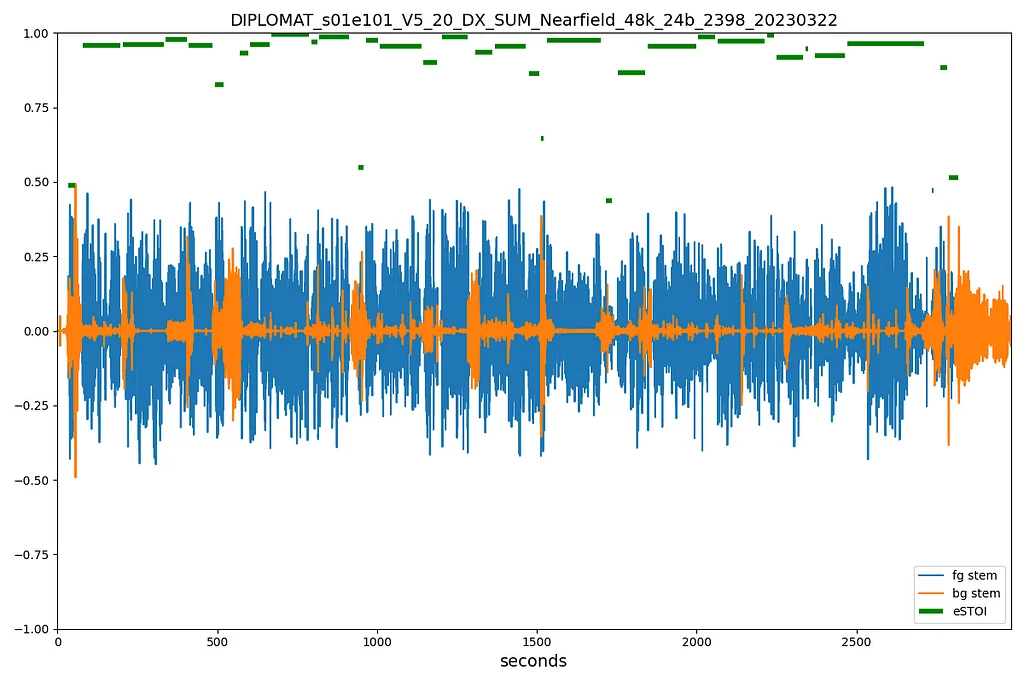
넷플릭스는 기술 파트너와의 협력을 통해 도구와 워크플로우를 개선함으로써 회원 경험 향상에 우선순위를 둡니다. 이 협력은 제작 과정 전반에 걸쳐 대화 명료성을 향상시키는 데 초점을 맞추고 있으며, 촬영 현장에서 스크린에 이르기까지 발생하는 문제를 해결합니다. 주요 이니셔티브는 대화 무결성 파이프라인(Dialogue Integrity Pipeline)으로, 시끄러운 환경 및 오디오 믹싱과 같이 명료성에 영향을 미치는 요인을 식별하고 완화합니다. 넷플릭스는 업계 표준 음량 측정기를 사용하고, 대화 명료성을 분석하기 위해 eSTOI 기반 측정 시스템을 개발했습니다. 사전 전달 최적화를 개선하기 위해 넷플릭스는 Fraunhofer IDMT 및 Nugen Audio와 파트너십을 맺고 DialogCheck 플러그인을 개발했습니다. 이 플러그인은 디지털 오디오 워크스테이션(DAW)에 통합되어 사운드 엔지니어에게 실시간 피드백을 제공합니다. 이 협력은 Fraunhofer의 머신러닝 기반 음성 명료성 솔루션과 Nugen Audio의 오디오 플러그인 전문 지식을 활용합니다. DialogCheck 플러그인을 통해 대화 명료성 문제를 조기에 감지하고 해결하여 예술적 의도가 훼손되지 않도록 보장합니다. 궁극적인 목표는 청취 환경에 관계없이 모든 시청자에게 몰입적이고 접근성 높은 스토리텔링을 제공하는 것입니다. 이러한 협력적 접근 방식은 넷플릭스의 오디오 우수성 및 스토리텔링 혁신에 대한 헌신을 강조합니다.
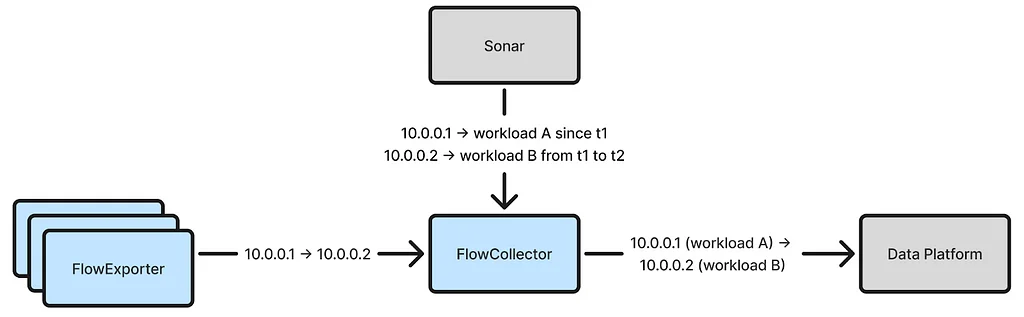
넷플릭스는 확장된 네트워크 통찰력을 위해 eBPF를 사용하여 대규모로 TCP 플로우 로그를 수집하지만, 플로우 IP 주소를 워크로드 ID에 정확하게 연결하는 것은 상당한 과제였습니다. 초기 연결 방식은 내부 IP 주소 추적 서비스인 Sonar에 의존했지만, 분산 시스템의 지연 및 장애로 인해 잘못된 연결이 발생했습니다. 잘못된 연결로 인해 플로우 데이터의 신뢰성이 떨어져 의사결정에 활용할 수 없었으며, 연결하기 전에 수신된 플로우를 15분 동안 보류하는 해결 방법으로도 문제가 해결되지 않았습니다. 이 문제를 해결하기 위해 넷플릭스는 로컬 워크로드 ID를 환경에서 판별하여 로컬 IP 주소를 연결하는 새로운 연결 방식을 개발했습니다. 컨테이너 워크로드의 경우, 넷플릭스는 컨테이너 IP 주소 할당 서비스인 IPMan을 활용하여 로컬 IP 주소를 연결했습니다. 로컬 IP 주소가 연결되면, 각 워크로드가 특정 IP 주소를 소유하는 시간 범위를 학습하여 원격 IP 주소를 연결할 수 있습니다. FlowCollector는 이러한 정보를 나타내는 인메모리 해시맵을 유지하고, Kafka를 사용하여 학습된 시간 범위를 다른 노드와 공유합니다. 이 새로운 방식은 정확한 연결을 달성하고 일시적인 문제를 효과적으로 처리하며, 단순성과 인메모리 조회 덕분에 비용 효율적입니다. 이 방식은 해당 지역의 노드로 플로우를 전달하여 지역 간 IP 주소 연결로 확장되었습니다. 마지막으로, 넷플릭스의 콘텐츠 전송 네트워크에 속한 것과 같은 비워크로드 IP 주소 연결로도 확장되었습니다.
영화 산업이 클라우드 기반 워크플로우로 전환하는 데는 전 세계적인 구현에 어려움이 따릅니다. 넷플릭스는 영화 제작자를 위해 설계된 Media Production Suite (MPS)를 통해 이러한 문제점을 해결하고자 합니다. MPS는 미디어 관리를 간소화하여 지루한 작업을 없애고 창의적인 집중력을 높여줍니다. 물리적 테이프를 사용하는 기존 워크플로우는 느리고 번거로워 협업을 방해합니다. 디지털 워크플로우 또한 배포 및 표준화에 어려움을 겪습니다. 클라우드는 이러한 문제에 대한 해결책을 제시하지만 운영 및 기술적 장애물을 극복해야 합니다. 넷플릭스는 사람과 애플리케이션을 미디어에 가져오는 방식으로 이 문제를 해결합니다. 즉, 그 반대가 아닌 것이죠. MPS는 다양한 시장의 요구를 고려하여 기술 및 표준화의 글로벌 격차를 해소합니다. 이 스위트는 업계 표준을 사용하여 색상 관리 및 프레임 작업과 같은 프로세스를 자동화합니다. 인프라는 사용자 성능에 최적화된 클라우드 및 물리적 기능을 결합합니다. MPS에는 섭취(ingest), 미디어 라이브러리, 데일리, 원격 워크스테이션 등을 위한 도구가 포함되어 있습니다. 350개 이상의 작품이 MPS 도구를 활용했으며, 다양한 글로벌 지역에서 피드백을 받았습니다. 브라질 시리즈 "Senna"는 MPS를 채택하여 지리적 장벽을 극복하는 능력을 보여주었습니다.
넷플릭스는 회원 선호 학습을 중앙 집중화하고 다양한 추천 모델 전반의 효율성을 향상시키기 위해 추천을 위한 파운데이션 모델을 개발하고 있습니다. 현재 시스템은 유지 관리에 비용이 많이 들고 혁신을 공유하는 데 어려움을 겪는 특화된 모델을 가지고 있습니다. 파운데이션 모델은 광범위한 사용자 상호작용 기록과 콘텐츠 데이터를 학습하여 이러한 학습 내용을 다른 모델에 배포하는 것을 목표로 합니다. 대규모 언어 모델에서 영감을 얻어, 이 접근 방식은 반지도 학습을 사용하여 데이터 중심 전략으로 전환합니다. 넷플릭스는 사용자 상호작용을 토큰화하여 데이터 세분성과 시퀀스 압축의 균형을 맞춰 긴 상호작용 기록을 처리합니다. 희소 어텐션 메커니즘과 슬라이딩 윈도우 샘플링을 사용하여 훈련 중에 계산 효율성을 관리합니다. 각 토큰에는 액션 및 콘텐츠에 대한 풍부하고 이질적인 정보가 포함되어 있으며, 요청 시점 및 액션 후 기능을 활용합니다. 이 모델은 GPT와 유사하게 자기 회귀적 다음 토큰 예측 목표를 사용하지만, 다양한 상호작용 중요성을 고려하도록 수정되었습니다. 모델은 여러 토큰을 예측하고 보조 예측 목표를 사용하여 장기적인 종속성을 포착하고 정확도를 향상시킵니다. 엔티티 콜드 스타팅 문제를 해결하기 위해, 이 모델은 증분 훈련을 통해 구축되었으며, 엔티티와 입력의 메타데이터 정보를 사용하여 보이지 않는 엔티티로 추론할 수 있습니다.
넷플릭스가 AV1 지원 기기에서 HDR10+ 콘텐츠 스트리밍을 시작하여 인증된 HDR10+ 기기에서 더욱 향상된 시청 경험을 제공합니다. 이는 정적 메타데이터만 사용했던 기존 HDR10 콘텐츠를 개선한 것입니다. HDR10+의 동적 메타데이터는 화질과 정확도를 향상시킵니다. 넷플릭스는 HDR 기술 도입의 선구자였으며, 지난 5년간 HDR 스트리밍은 300% 이상 증가했습니다. 현재 넷플릭스는 11,000시간 이상의 HDR 콘텐츠를 제공하고 있습니다.
넷플릭스는 가장 효율적인 코덱 중 하나인 AV1 비디오 코덱을 사용하여 HDR10+를 활성화했습니다. AV1은 이미 넷플릭스에서 두 번째로 많이 스트리밍되는 코덱이며, HDR10+ 스트림이 추가됨에 따라 곧 가장 많이 스트리밍되는 코덱이 될 것으로 예상됩니다. 넷플릭스는 새로운 출시작과 기존 인기 HDR 콘텐츠 모두에 HDR10+ 스트림을 추가하고 있으며, 연말까지 모든 HDR 콘텐츠에 HDR10+ 경험을 제공하는 것을 목표로 하고 있습니다.
HDR10+는 돌비 비전, HDR10과 함께 널리 사용되는 세 가지 HDR 포맷 중 하나입니다. HDR10+와 돌비 비전은 프레임 단위로 콘텐츠 이미지 통계를 제공하는 동적 메타데이터를 사용하여 각 장면에 최적화된 톤 매핑 조정을 가능하게 합니다. 이를 통해 원본에 대한 더 높은 인지적 충실도를 달성하여 창작자의 의도를 보존합니다. HDR10+를 시청하려면 넷플릭스 프리미엄 요금제에 가입되어 있어야 하며, 해당 콘텐츠가 HDR10+ 포맷으로 제공되어야 하고, 회원 기기가 AV1과 HDR10+를 지원해야 합니다.
HDR10+ 출시에는 넷플릭스의 여러 팀이 협력했으며, 이 아이디어를 현실로 만드는 데 기여한 모든 분들께 감사드립니다. 혁신과 품질에 대한 헌신은 모든 회원에게 몰입감 있고 진정한 시청 경험을 제공하려는 넷플릭스의 노력을 강조합니다.
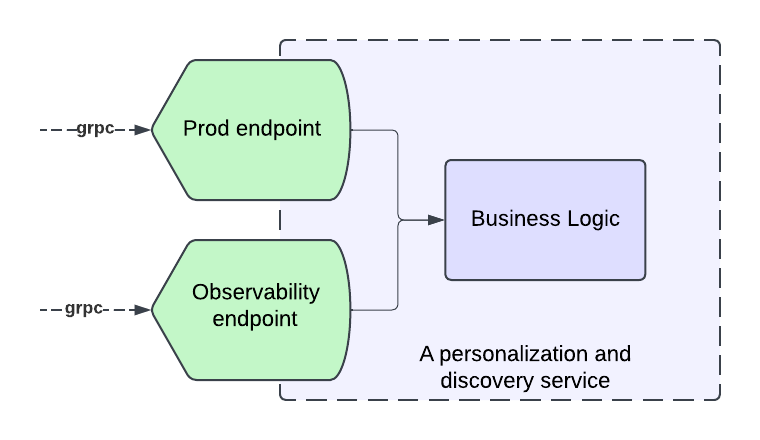
넷플릭스는 포괄적인 타이틀 관찰성을 달성하기 위해 개인화 및 발견 스택 내 모든 서비스에 관찰성 엔드포인트를 도입했습니다. 스택에 포함된 각 마이크로서비스는 실제 동작을 정확하게 반영하고, 표준화하며, 인사이트 삼각형(Insight Triad)에 답하는 새로운 "타이틀 상태(Title Health)" 엔드포인트를 도입해야 했습니다. 인사이트 삼각형은 엔드포인트가 타이틀이 홍보에 적합한지 여부, 적합하지 않은 이유, 문제 해결 방법을 답해야 함을 의미합니다.
관찰성 서비스와 개인화 스택의 관찰성 엔드포인트 간 통신을 표준화하기 위해 안정적인 프로토콜 요청/응답 형식이 개발되었습니다. 이 솔루션의 상위 아키텍처는 관찰성 엔드포인트 구축, 사전 예방적 모니터링, 실시간 타이틀 노출 추적, 최적화된 데이터 저장소에 데이터 저장, 대시보드를 위한 쉽게 통합 가능한 API 제공을 포함합니다.
타이틀 상태 마이크로서비스는 30분마다 예약된 수집 작업을 실행하여 할당된 로우 서비스에서 관련 타이틀 상태 정보를 가져옵니다. 실시간 타이틀 노출 데이터는 Kafka 큐에서 처리되며, 2분마다 큐를 폴링하여 노출 데이터를 가져옵니다. 그런 다음 데이터가 집계되어 이해관계자에게 추가적인 상태 표시기로 표시됩니다.
데이터는 각 수집기마다 전용 Hollow 피드에 저장됩니다. 이를 통해 고성능 읽기 전용 액세스가 가능하고 전반적인 상태 모니터링과 타이틀 기록 추적이 가능합니다. 관찰성 대시보드는 타이틀 상태 서비스를 사용하여 이해관계자에게 타이틀 상태를 표시하며, 시스템에는 문제가 회원에게 영향을 미치기 전에 문제를 파악하고 해결하기 위해 트래픽을 미리 시뮬레이션하는 "타임 트래블(Time Travel)" 기능도 있습니다.
이 시스템의 아키텍처와 전략을 통해 넷플릭스는 타이틀 출시 관찰성을 향상시켜 흥미진진한 시청 경험을 보장하고 콘텐츠 제작자 및 파트너와의 신뢰를 구축했습니다. 또한 이 솔루션은 미래 혁신을 위한 기반을 마련하여 모든 스토리가 의도된 대상에게 도달하고 모든 회원이 넷플릭스에서 좋아하는 타이틀을 즐길 수 있도록 합니다.
넷플릭스에서 플랫폼의 이미지들은 "노출"이라고 불리며 사용자 경험을 개인화하는 데 중요한 역할을 합니다. 이러한 노출을 캡처하고 처리하는 것은 복잡한 작업으로, 정교한 시스템이 필요합니다. 시스템은 일일로 수십억 개의 노출을 추적하고 처리하며, 각 프로필의 노출에 대한 자세한 기록을 유지합니다. 이 노출 기록은 향상된 개인화, 빈도 제한, 새로운 릴리스 강조, 분석적 통찰력을 얻는 데 필수적입니다. 노출을 관리하는 첫 번째 단계는 Source-of-Truth(SOT) 데이터셋을 생성하는 것입니다. 이는 다양한 다운스트림 워크플로우를 지원하고 여러 사용 사례를 가능하게 합니다. 원시 노출 이벤트는 클라이언트 측에서 수집되어 사용자 지정 이벤트 추출기, 아파치 카프카, 아파치 아이스버그를 통해 처리됩니다. 그런 다음 데이터는 아파치 플링크를 사용하여 필터링, 풍부화, 구조화되어 넷플릭스의 노출 데이터에 대한 확고한 진실의 근거가 됩니다. 시스템은 자세한 메트릭스를 수집하고 잠재적인 문제가 발생할 경우 팀에 경고를 보내며, 높은 품질의 노출을 보장합니다. 아키텍처는 대량의 노출 이벤트를 실시간으로 처리하는 데 설계되었으며, 확장성, 유연성, 높은 가용성을 중점으로 합니다. 향후 작업에는 비스키마 이벤트를 처리하는 것, 성능 튜닝을 자동화하는 것, 데이터 품질 경고를 개선하는 것이 포함됩니다.
넷플릭스에서 무결한 제목 출시와 검색 가능성을 보장하기 위해선, 솔루션에 뛰어들기 전에 더 넓은 맥락을 이해하는 것이 필수적입니다. 이러한 생각 있는 접근 방식은 미래의 탄력성과 확장성을 구축합니다. 첫 번째 단계는 더 큰 그림을 이해하는 것입니다. 즉, 이해 관계자, 현재의 경관, 핵심 문제, 비즈니스 우선순위를 확인하는 것입니다. 주요 이해 관계자는 제목 출시 운영자, 개인화 시스템 엔지니어, 제품 매니저, 크리에이티브 대 diện입니다.
현재의 경관을 매핑하는 과정에서 제목 출시 관찰 가능성에 대한 확립된 솔루션이 없었음을 알게 되었습니다. 이는 cả 도전과 기회를 제시합니다. 핵심 문제는 개인화 스택에서 모든 제목이 공정하게 대우받는 것을 보장하는 것이었습니다. 이를 해결하기 위해 "제목 건강"이라는 공유된 이해를 도입했습니다. 이는 검색 가능성 및 회원 참여 측면에서 제목의 성과를 반영하는 다양한 지표와 지표를 포함합니다.
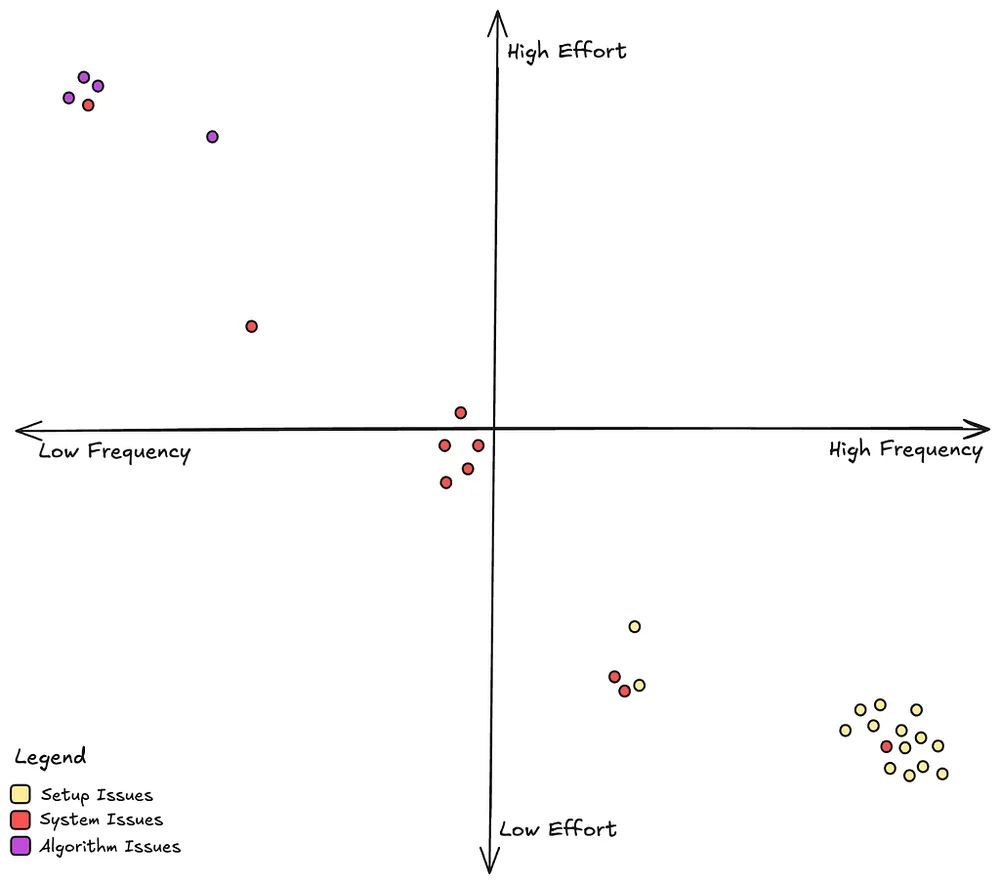
제목 건강은 각 제목의 수명 주기 모니터링 및 최적화를 허용하여 파트너와 원칙 및 요구 사항에 대한 조정을 가능하게 했습니다. 제목 출시 관찰 가능성을 위한 강력한 계획을 구축하기 위해 문제를 세 가지 주요 영역으로 분류했습니다. 즉, 제목 설정, 개인화 시스템, 알고리즘입니다. 문제를 분류하면 도전을 체계적으로 해결할 수 있고, 모든 제목에 대한 신뢰할 수 있는 개인화 경험을 제공할 수 있습니다.
문제 분석 결과, 설정 문제가 가장 일반적이나 가장 쉽게 해결할 수 있는 반면, 알고리즘 문제는 드물지만 해결하기 어려운 것으로 나타났습니다. 옵션 평가 결과, 첫 번째로 proactice 문제 감지에 초점을 두기로 결정했습니다. 즉, 출시 전에 문제를 잡아 더 매끄러운 출시, 더 나은 회원 경험, 더 강한 시스템 신뢰성을 보장하는 것입니다. 이러한 결정은 플랫폼의 복잡성이 증가하는 것에 따라 성장할 수 있는 확장 가능하고 강력한 시스템의 기초를 마련했습니다.
이 기사는 넷플릭스에서 분석 엔지니어링에 대한 다중 부품 시리즈를 마무리하며 기술적인 기술에 중점을 둔다. 사용자 요구 사항을 이해하고 기존 패턴을 활용하는 것의 중요성을 강조하면서 대시보드 디자인 팁에 대해 논의한다. 또한 사용자 정신 모델과 일치하도록 애플리케이션을 구조화하는 방법, 페이지 레이아웃, 상호 작용 차트 및 온보딩에 대한 지침을 제공한다. 또한 넷플릭스에서 분석 API를 배포하면서 얻은 교훈을 공유하며, 영향과 실시간 결과의 필요성 측정, 모든 사용 가능한 솔루션 탐색, 성능 기대치 조정 및 철저한 테스트 및 협력의 중요성을 강조한다.
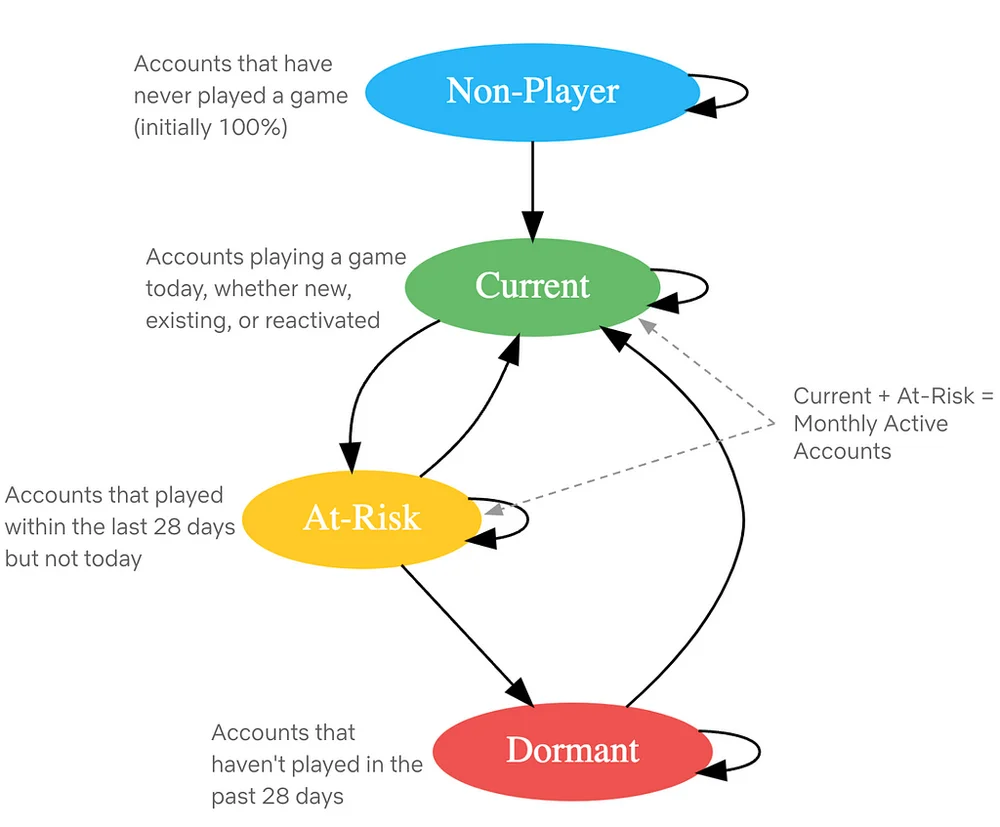
넷플릭스 분석 엔지니어링팀은 여러 프로젝트를 진행 중입니다. 넷플릭스 게임의 사용자 확보 캠페인 효과 측정을 위한 게임 분석이 대표적입니다. 합성 통제 프레임워크를 이용하여 캠페인의 반실험적 시나리오를 추정하고, 증분 결과에 대한 통찰력을 제공하는 대화형 도구를 개발했습니다. 또한, 향후 캠페인 설계 및 예산 편성을 위한 증분 투자수익률(ROI) 모델을 개발 중입니다. 넷플릭스 게임의 증분 가입자 수 측정 및 검증에도 힘쓰고 있으며, 증분 계정 수명 가치 평가와 같은 다른 프레임워크를 활용한 접근 방식을 사용합니다. 넷플릭스 게임의 플레이어 여정은 상태 머신을 이용하여 모델링되어 있으며, 매일 계정 상태 전환 확률을 보여줍니다. 이 모델은 참여 목표 달성 상황 평가 및 월간 활성 계정 증대 방안 모색에 도움이 됩니다. 콘텐츠 현금 모델링 또한 진행 중이며, '미정' 슬롯에 대한 현금 수요를 타이틀 출시 전후 일별 현금 지출 모델링을 통해 예측합니다. 마지막으로, 보조 음성 인식 기술을 이용한 더빙 작업 과정의 전사 효율 개선과 그 성능 평가를 위한 다층적 측정 프레임워크를 개발하고 있습니다.
메타플로우(Metaflow)는 넷플릭스(Netflix) 팀이 효율적으로 머신러닝/인공지능 프로젝트를 개발하고 관리할 수 있도록 합니다. 메타플로우의 새로운 기능인 Configs는 사용자가 흐름 매개변수, 리소스 요구 사항 및 애플리케이션별 설정을 사람이 읽을 수 있는 구성 파일에서 정의할 수 있게 해서 구성 가능한 흐름을 가능하게 합니다. Configs는 기존의 메타플로우 아티팩트와 매개변수를 확장하여 더 큰 유연성과 사용자 지정 옵션을 제공합니다. 또한, 원격 실행 또는 프로덕션 배포를 사용할 때에도 동적으로 로드되고 수정될 수 있습니다. Configs는 고정 배포와 런타임 구성 가능성의 혼합, 구성 유효성 검사, 구성 파일의 계층 구조 관리, 구성의 동적 생성과 같은 고급 사용 사례를 가능하게 합니다. Hydra와 같은 구성 관리자와 결합하여 Configs는 여러 구성에 대한 실험의 오케스트레이션과 매개변수 공간에 대한 스위핑을 가능하게 합니다. 넷플릭스의 내부 도구인 메타부스트(Metaboost)는 실제 적용 사례로, 다양한 플랫폼에서 머신러닝 프로젝트를 관리하고 프로젝트 일관성을 향상하며 위험을 줄이는 데 Configs를 사용합니다.
Netflix의 분석 엔지니어링팀은 회사 내에서 효율적으로 고품질의 실천 가능한 통찰력을 생산하고 효과적으로 제공할 수 있는 방안을 모색합니다. 최근에 그들은 연례 내부 분석 엔지니어링 컨퍼런스를 개최했는데, 여기에서는 데이터정션, LORE, 클라우드 효율성 분석 활용을 위한 기반 플랫폼 데이터 활용과 같은 다양한 주제가 다루어졌습니다. 데이터정션은 지표 정의를 표준화하고 액세스할 수 있게 해주는 오픈 소스 솔루션인 반면 LORE는 최종 사용자에게 실제 통찰력을 제공하기 위해 LLM을 사용하는 채팅봇입니다. 또한 이 팀은 분석을 민주화하는 데 집중하는데, 여기에는 넷플릭스 분석가가 효율적으로 고품질의 통찰력을 생산하고 효과적으로 제공할 수 있도록 지원하는 분석 활성화와 같은 이니셔티브가 포함됩니다. 이 팀의 목표는 엔지니어링 조직이 넷플릭스가 스트리밍 서비스로 기능하도록 하는 서비스를 구축하고 유지할 때 효율성을 염두에 둔 의사 결정을 내릴 수 있도록 하는 것입니다.
Netflix는 컴퓨팅, 스토리지, 네트워킹을 포함한 클라우드 인프라 필요 사항에 Amazon Web Services(AWS)를 사용합니다. 이 회사의 다양한 기술 환경은 다양한 인프라 엔티티로부터 광범위한 데이터를 생성하며, 데이터 엔지니어와 분석가는 이 데이터를 사용하여 엔지니어링 조직에 실행 가능한 통찰력을 제공합니다. 데이터 및 인사이트 조직은 엔지니어링 팀과 협력하여 핵심 효율성 지표를 공유하고, 이해 관계자가 정보에 입각한 사업 결정을 내릴 수 있도록 합니다. 플랫폼 DSE 팀은 기반 플랫폼 데이터(FPD)와 클라우드 효율성 분석(CEA)의 2가지 구성 요소 솔루션을 개발했습니다. FPD는 모든 플랫폼 데이터에 대한 중앙화된 데이터 계층을 제공하며, 일관된 데이터 모델과 표준화된 데이터 처리 방법론을 특징으로 합니다. CEA는 다양한 비즈니스 사용 사례 전반에 걸친 시간 시리즈 효율성 지표를 제공하는 분석 데이터 계층을 제공합니다. 이 팀은 다가오는 해에 거의 완전한 비용 통찰력 보급을 위해 FPD와 CEA에 플랫폼을 계속 온보딩하는 것을 목표로 합니다. 또한 보안 및 가용성과 같은 다른 사업 분야에 FPD를 확장하고, 예측 분석과 ML을 통한 사용 최적화 및 비용 이상 탐지를 통해 선제적 접근 방식으로 전환할 계획입니다.
넷플릭스는 매달 1,000개가 넘는 글로벌 콘텐츠 출시를 관리하는 것이 최우선 과제이며, 이를 위해서는 포괄적인 가시성을 제공하는 강력한 시스템이 필요합니다. 넷플릭스는 모든 콘텐츠를 적절한 시청자와 연결하는 것을 목표로 하지만, 오류율이나 CPU 사용률과 같은 기존 시스템 지표는 콘텐츠 성공의 뉘앙스를 포착하지 못합니다. 이러한 간극을 해소하기 위해 넷플릭스는 이러한 뉘앙스를 인식하고 모든 콘텐츠가 빛날 수 있도록 지원하는 시스템을 설계해야 했습니다.
넷플릭스 오리지널 초기에는 출시팀이 수동으로 콘텐츠 배치를 확인했지만, 이러한 방식은 회사의 글로벌 확장과 함께 확장될 수 없었습니다. 그 결과 넷플릭스는 콘텐츠 성과 및 검색 가능성에 대한 복잡한 질문에 정확하고 시의적절한 답변을 제공하는 데 운영상의 어려움을 겪었습니다. 넷플릭스는 모든 콘텐츠가 메타데이터 및 자산이 정확하게 구성되고, 데이터가 원활하게 흐르며, 알고리즘이 의도대로 작동하도록 완벽하게 출시될 수 있도록 확장 가능한 솔루션이 필요했습니다.
이러한 과제를 해결하기 위해 넷플릭스는 로그 처리와 개인화 시스템의 가시성 엔드포인트라는 두 가지 옵션을 고려했습니다. 로그 처리는 콘텐츠 출시 모니터링 및 분석을 위한 간단한 솔루션을 제공하지만, 문제를 미리 감지하고 정확성을 보장하는 데는 한계가 있습니다. 반면 가시성 엔드포인트는 실시간 모니터링, 사전 문제 감지 및 향상된 정확성을 제공하지만 상당한 초기 투자와 동기화 작업이 필요합니다.
넷플릭스는 궁극적으로 실시간 모니터링, 사전 문제 감지 및 진실 출처 조정을 포함하는 포괄적인 가시성 전략을 채택했습니다. 이러한 접근 방식은 플랫폼 전반에서 콘텐츠의 성공적인 출시와 검색 가능성을 보장하는 회사의 역량을 크게 향상시켰습니다. 시리즈의 다음 부분에서는 넷플릭스가 이를 어떻게 달성했는지에 대한 주요 기술적 통찰력과 세부 정보를 공유할 것입니다.
넷플릭스의 분산 카운터 추상화는 저밀리초 지연으로 대용량의 시간적 이벤트 데이터를 저장하고 쿼리하는 서비스입니다. 이 서비스는 두 가지 주요 사용 사례 카테고리를 지원합니다. 최선의 노력 카운터는 EVCache를 사용하여 단일 지역 내에서 고 처리량과 저 지연을 제공하지만, 지역 간 복제 및 일관성 보장이 없습니다. 최종적으로 일관된 카운터는 Apache Kafka와 같은 지구적인 큐잉 시스템을 사용하여 정확하고 지구적인 카운트를 제공하지만, 파티션 재균형 맞추기에 지연이 발생하고 어려움이 있습니다. 넷플릭스의 접근 방식은 카운팅 활동을 이벤트로 로깅하고 이러한 이벤트를 지속적으로 집계하여 감사 및 재계산 요구 사항을 충족합니다.
사용자가 워크벤치에서 특정 노트북을 실행할 때 JupyterLab UI가 느려지고 반응이 없다고 보고했습니다. 느려짐을 정량화하기 위해 사용자의 노트북을 실행하면서 15초 동안 키를 누른 후 1초에서 10초 사이의 지연이 발생했으며 평균 지연은 7.4초였습니다. CPU 과부하 및 네트워크 문제를 잠재적인 원인으로 배제했습니다. py-spy를 사용하여 jupyter-lab 프로세스에서 많은 CPU 시간이 __parse_smaps_rollup 함수에 소비되는 것을 발견했습니다. 이 함수는 jupyter_resource_usage 확장의 일부로 리소스 사용 정보를 가져올 때 사용됩니다. 이 함수는 UI에서 주기적으로 호출되는 API 엔드포인트에 의해 트리거됩니다. 코드는 JupyterLab 프로세스의 모든 자식 프로세스를 재귀적으로 가져옵니다. 이는 노트북 프로세스와 노트북에서 생성된 모든 프로세스를 포함합니다. 이 함수의 비용은 모든 자식 프로세스의 수에 선형적으로 비례합니다. 재현 코드에서는 96개의 프로세스를 생성하는데, 이는 컨테이너에 할당된 64개의 CPU보다 많습니다. 이러한 불일치가 부모 프로세스를 느리게 만듭니다.
넷플릭스는 대용량의 시간 이벤트 데이터를 효율적으로 저장하고 조회할 수 있는 TimeSeries Abstraction을 개발했습니다. 이 시스템은 높은 처리량의 쓰기, 대용량 데이터의 효율적인 조회, 글로벌 읽기 및 쓰기, 설정 가능한 구성, 비용 효율성을 지원하도록 설계되었습니다. TimeSeries Abstraction은 분할된 데이터, 유연한 저장소, 구성 가능성, 확장성 및 샤딩된 인프라스트럭처를 포함한 핵심 설계 원칙을 중심으로 구축되었습니다.
데이터 모델은 이벤트 항목, 이벤트, 시간 시리즈 ID 및 네임스페이스로 구성됩니다. 이벤트 항목은 키-값 쌍으로 이벤트 데이터를 저장하며, 이벤트는 하나 이상의 이벤트 항목으로 구성된 구조화된 컬렉션입니다. 시간 시리즈 ID는 데이터셋의 보존 기간 동안의 이벤트 컬렉션이며, 네임스페이스는 시간 시리즈 ID 및 이벤트 데이터의 컬렉션입니다.
TimeSeries Abstraction은 이벤트 데이터와 상호 작용하기 위한 API를 제공합니다. 여기에는 WriteEventRecordsSync, WriteEventRecords, ReadEventRecords, SearchEventRecords 및 AggregateEventRecords가 포함됩니다. 저장소 계층은 기본 데이터 저장소와 선택적 인덱스 데이터 저장소로 구성되며, Apache Cassandra와 Elasticsearch가 각각 데이터 저장소 및 인덱싱에 대한 선호되는 선택입니다.
기본 데이터 저장소는 시간 간격에 따라 데이터를 관리 가능한 청크로 나누는 시간 분할 방식을 사용하여 특정 시간 범위의 효율적인 조회 및 저장소 및 조회 성능 최적화를 허용합니다. 데이터는 또한 시간 버킷 및 이벤트 버킷으로 나누어져 효과적인 범위 스캔 및 높은 처리량의 쓰기 작업을 관리할 수 있습니다.
TimeSeries Abstraction은 대규모 시간 이벤트 데이터의 저장 및 조회에 대한 도전을 해결하도록 설계되었습니다. 여기에는 높은 처리량, 효율적인 조회, 글로벌 읽기 및 쓰기, 설정 가능한 구성 및 비용 효율성이 포함됩니다. 고유한 이벤트 데이터 모델 및 확장 가능한 저장소 계층을 사용하여 TimeSeries Abstraction은 시간 데이터를 관리하기 위한 유연하고 비용 효율적인 솔루션을 제공합니다.
넷플릭스의 키-값 데이터 추상화 계층 (KV DAL)은 데이터 접근을 단순화하고 인프라의 신뢰성을 향상시키는 기본적인 추상화 서비스입니다. 이는 개발자에게 일관된 인터페이스를 제공하며, 이는 데이터베이스의 종류에 관계없이 동일합니다.
KV 추상화는 두 단계의 맵 아키텍처를 사용하여 단순하고 복잡한 데이터 모델을 모두 지원합니다. 다양한 사용 사례에 맞게 4개의 기본 CRUD API (PutItems, GetItems, DeleteItems)와 복잡한 MutateItems 및 ScanItems API를 제공합니다.
네임스페이스는 데이터가 저장되는 위치와 방법을 정의하며, 논리적 및 물리적 분리를 제공합니다. 이는 다양한 성능, 내구성 및 일관성 요구에 따라 다른 사용 사례를 가장 적합한 저장 시스템으로 라우팅할 수 있도록 합니다.
PutItems 및 DeleteItems API는 데이터 무결성을 보장하고 작업 순서를 올바르게 유지하기 위해 멱등성 토큰을 사용합니다. 클라이언트에서 생성한 단조 증가 토큰이 신뢰성을 위해 선호됩니다.
대용량 blob을 처리하기 위해 KV 추상화는 청킹을 사용합니다. 이 기술은 대용량 데이터를 작은 청크로 나누어 적절한 메타데이터와 함께 스테이징 및 커밋합니다.
페이징은 대용량 데이터 세트를 관리하는 데 중요한 기능입니다. GetItems API는 다음 페이지 토큰을 사용하여 페이징을 지원하여 여러 요청에 걸쳐 효율적인 데이터 검색을 보장합니다.
삭제된 데이터를 나타내는 투명석은 성능에 영향을 미칠 수 있습니다. KV는 레코드 및 범위 삭제를 최적화하여 단일 투명석을 생성하여 부하 피크를 줄이고 일관된 성능을 유지합니다.
아이템 수준 삭제는 TTL 기반 삭제와 지터를 사용하여 처리됩니다. 이 기술은 저장 엔진의 복잡성을 숨기고 삭제가 읽기 페이징에 미치는 영향을 최소화합니다.
멱등성과 청킹은 꼬리 지연 시간을 처리하고 예측 가능한 저지연 성능을 보장하는 데 필수적입니다. 이러한 설계 철학은 넷플릭스의 글로벌 운영에 필요한 신뢰성과 성능에 기여합니다.
푸시(Pushy)는 넷플릭스의 웹소켓 서버로, 넷플릭스 앱을 실행하는 장치와 지속적인 연결을 유지합니다. 푸시는 메시지 전달 서비스에서 넷플릭스 생태계의 중요한 부분으로 발전했습니다. 푸시는 수백만 개의 동시 웹소켓 연결을 처리하며, 초당 수십만 개의 메시지를 전달하며, 99.999%의 메시지 전달 신뢰성율을 달성합니다. 초기에 파이어티브이(FireTVs)용으로 개발되었지만, 푸시의 범위는 모바일 장치 및 제한된 기능을 가진 오래된 장치 등 거의 10억 개의 장치로 확장되었습니다. 이러한 성장을 처리하기 위해, 푸시는 여러 가지 개선이 이루어졌습니다. 메시지 프로세서를 넷플릭스 파베드 패스(paved-path) 컴포넌트로 다시 작성하고, 키-값(KeyValue)으로 푸시 레지스트리를 마이그레이션하여 성능과 확장성을 개선하고, 연결 수에 따라 지수적 확장 정책을 구현했습니다. 이러한 개선 사항으로 푸시는 더 신뢰할 수 있고 안정적이며 효율적인 시스템이 되었습니다. 이는 장치의 증가하는 수를 지원하고 새로운 기능의 요구를 충족할 수 있도록 합니다.
넷플릭스는 eBPF를 사용하여 지속적으로 런 큐 지연 시간을 모니터링합니다. 런 큐 지연 시간은 성능이 저하되는 인접 컨테이너에서 서버 리소스를 과도하게 사용하는 '시끄러운 이웃' (noisy neighbors) 컨테이너의 지표입니다.
eBPF 훅 (sched_wakeup, sched_wakeup_new, sched_switch)은 런 큐 지연 시간을 캡처하고, cgroup ID와 관련시킵니다. kfuncs (커널 함수)를 사용하여 안전한 RCU 보호 데이터 액세스를 제공합니다.
eBPF의 속도 제한기는 사용자 공간으로 전송되는 데이터 포인트를 제한하여 관찰 가능성과 성능을 균형을 맞춥니다.
사용자 공간 프로세스는 eBPF 링 버퍼에서 이벤트를 처리하고, 런 큐 지연 시간 (runq.latency)과 선점 카운트 (sched.switch.out)를 포함한 메트릭을 Atlas에 전송합니다. 이러한 메트릭은 cgroup ID로 식별됩니다.
런 큐 지연 시간과 선점 카운트 메트릭은 모두 시끄러운 이웃을 식별하는 데 필요합니다. 런 큐 지연 시간만으로는 CPU 제한에 도달한 컨테이너에서 오류가 발생할 수 있기 때문입니다.
사례 연구에서는 새로운 컨테이너가 호스트 CPU를 완전히 사용하여 런 큐 지연 시간과 선점이 급증하는 시끄러운 이웃 문제를 보여줍니다.
시스템 프로세스는 선점 카운트 메트릭을 사용하여 시끄러운 이웃으로 식별되었습니다.
eBPF 코드 최적화, BPF_MAP_TYPE_HASH 사용, 직접 태스크 구조 멤버 액세스 및 커널 태스크 무시를 통해 오버헤드를 최소화했습니다.
커널 통계 계산을 개선하기 위해 리눅스 커널 패치가 제출되어 승인되었습니다.
BPFtop, 오픈 소스 eBPF 프로세스 모니터링 도구를 사용하여 eBPF 코드의 오버헤드를 측정했습니다.
넷플릭스는 회원의 만족도를 향상시키기 위해 개인화 알고리즘을 사용하여 콘텐츠 추천을 제공합니다. 추천은 회원의 피드백과 콘텍스트를 고려하는 컨텍스트 밴딧 문제로 간주됩니다. 전통적인 추천 시스템은 클릭수와 같은 단기 지표를 최적화하는 데 초점을 맞추고 있지만, 이는 장기 만족도를 완전히 포착하지 못할 수 있습니다. 단순히 유지율을 최적화하는 것만으로는 제약이 있으므로 넷플릭스는 장기 회원 만족도와 일치하는 프록시 보상 함수를 사용합니다. 클릭률은 간단한 프록시 보상이지만 넷플릭스는 회원의 다양한 행동과 그 행동이 만족도에 미치는 영향을 고려하여 그 너머로 확장합니다. 보상 공학은 프록시 보상 함수를 장기 회원 만족도와 일치하도록 개선하는 반복적인 과정입니다. 이는 가설 형성, 보상 정의, 밴딧 정책 훈련 및 A/B 테스트를 포함합니다. 넷플릭스는 지연된 피드백의 문제를 예측하여 모든 피드백을 프록시 보상 함수에 사용할 수 있도록 해결합니다. 오프라인 모델 개선에도 불구하고 온라인-오프라인 지표 차이가 발생할 수 있습니다. 넷플릭스는 프록시 보상 정의를 추가로 개선하여 이를 해결합니다. 여전히 풀어야 할 질문들도 있습니다. 예를 들어 프록시 보상 함수 학습을 자동화하는 방법, 지연된 피드백을 기다리는 최적의 시간을 결정하는 방법, 강화 학습을 통해 장기 만족도와의 일치를 향상시키는 방법 등입니다.
넷플릭스에서 연구자들은 역사적인 실험을 통해 짧은 기간의 프록시 지표와 장기적인 북극성 지표 간의 관계를 설정하는 방법을 제시합니다. 이러한 관계를 이해하는 데 있어 직관적인 접근 방식은 혼란 요소와 상관된 측정 오류로 인해 오해의 소지가 있습니다. Total Covariance (TC) 추정치는 처리 효과 추정치의 공분산에서 측정 오류 공분산을 뺀 후 OLS 기울기를 계산합니다. Jackknife Instrumental Variables Estimation (JIVE)은 각 관측치의 데이터를 해당 관측치의 대리치 계산에서 제외하여 상관된 측정 오류를 제거합니다. 제한된 정보 최대 가능도 추정치 (LIML)는 처리와 북극성 지표 간에 직접적인 효과가 없다는 가정 하에서 통계적으로 효율적입니다. 이러한 방법은 처리 효과의 선형 구조 모델을 제공하여 쉽게 해석할 수 있고 북극성 지표에 대한 조정 및 정렬을 촉진합니다. 또한 지표 교환 관리, 지표 혁신 및 독립적인 팀 작업을 가능하게 합니다. 현재의 데이터 아키텍처 도전 과제에도 불구하고 이러한 방법은 넷플릭스에서 성공적으로 구현되어 있으며 프록시 지표 개발에 적극적으로 사용되고 있습니다. 연구자들은 이러한 방법의 적용을 간소화하기 위해 더 유연한 데이터 아키텍처가 필요하다고 인정하고 오픈 직업 공고를 통해 잠재적인 기여자들을 환영합니다.
넷플릭스는 아마존 AWS에서 여러 지역에 걸쳐 광대한 클라우드 인프라를 운영하여 원활한 콘텐츠 전달을 지원합니다. 특정 애플리케이션이 지역 간 데이터 동기화 문제를 경험할 때, 초기 의심은 네트워크에 집중되었고, 타임아웃으로 인해 문제가 발생하는 것으로 추측되었습니다.
네트워크 엔지니어가 조사했을 때, 클라이언트에서 기인하는 TCP RST 패킷을 발견하여 클라이언트가 연결을 예상치 못하게 종료하고 있음을 확인할 수 있었습니다.
패킷 캡처는 서버가 지속적으로 데이터를 전송하고 있지만 클라이언트가 30초 후에 갑자기 연결을 종료하고 있음을 보여주었습니다.
애플리케이션을 살펴보면 서버에서 초기 데이터를 받는 데 30초의 타임아웃이 설정되어 있었고, 이 시간 내에 데이터를 받지 못하면 연결을 종료하고 있었습니다.
애플리케이션 또는 서버에 최근 변경이 없었음에도 불구하고, 이 문제는 리눅스 커널 업그레이드(버전 6.5.13에서 6.6.10으로)와 함께 발생했습니다.
시스템적인 커널 바이섹션을 통해 문제를 일으키는 커밋을 확인할 수 있었고, 이 커밋은 TCP 수신 창 크기 계산에 새로운 메커니즘을 도입했습니다.
원래의 계산은 50%의 오버헤드를 가정했지만, 새로운 메커니즘은 실제 데이터 특성에 기반하여 오버헤드를 동적으로 계산하여 더 작은 수신 창 크기를 생성했습니다.
이렇게 작아진 창 크기 때문에 애플리케이션은 30초 내에 데이터를 충분히 빠르게 받을 수 없었고, 이로 인해 연결이 종료되었습니다.
근본적인 원인은 sysctl_tcp_adv_win_scale 매개변수가 더 정확한 크기 비율로 수신 창 크기를 계산하는 scaling_ratio로 대체된 것과 관련이 있었습니다.
커널 업그레이드를 되돌려 애플리케이션의 정상 작동을 복원하는 데 성공했으며, 커널 변경이 문제의 근본적인 원인임을 보여주었습니다.
Java를 광범위하게 사용하는 것으로 유명한 넷플릭스는 성능 이점을 위해 가상 스레드를 도입하는 데 열광했습니다. 그러나 Java 21로 마이그레이션하는 동안 엔지니어들은 SpringBoot 3 및 임베디드 Tomcat과 함께 가상 스레드를 사용하는 애플리케이션에서 간헐적인 시간 초과와 응답하지 않는 인스턴스를 경험했습니다. 조사 결과, 애플리케이션이 연결을 닫지 못하는 closeWait 상태에 갇힌 소켓이 급증한 것으로 나타났습니다. 처음에는 스레드 덤프에 유휴 JVM이 표시되었지만, 특정 명령을 사용한 추가 분석 결과 생성되었지만 아직 실행되지 않은 스레드인 "빈" 가상 스레드가 다수 발견되었습니다. 이는 가상 스레드 실행에 문제가 있음을 의미하며, Tomcat이 들어오는 각 요청에 대해 새 가상 스레드를 생성하고 있지만 기본 운영 체제 스레드가 모두 사용 중이라는 것을 의미했습니다. 스레드 덤프에 대한 심층 분석 결과, 이러한 운영 체제 스레드는 코드의 동기화된 블록 내에서 잠금을 획득하기 위해 대기 중인 가상 스레드에 고정되어 있는 것으로 나타났습니다. 원인은 대기 작업을 완료한 후 잠금을 다시 획득할 수 없는 일반 플랫폼 스레드가 보유한 잠금이었습니다. 이 교착 상태로 인해 새로운 가상 스레드가 예약되지 않아 성능 문제가 관찰되었습니다.
Maestro, Netflix의 오픈 소스 워크플로우 오케스트레이터는 대규모 데이터 파이프라인 및 머신 러닝 워크플로우를 위해 설계되었습니다. 이는 acyclic 및 cyclic 워크플로우를 지원하며, foreach 루프, 하위 워크플로우 및 조건부 분기와 같은 재사용 가능한 패턴을 포함합니다. Maestro는 단일 워크플로우 내에서 대규모 워크플로우 및 잡을 관리하는 데 필요한 수평 확장성을 제공합니다. 사용자 제공 필드와 Maestro가 관리하는 필드를 결합하는 유연한 워크플로우 정의 형식인 JSON을 제공합니다. Maestro의 워크플로우 실행 전략에는 순차적, 엄격한 순차적, 첫 번째만, 마지막만, 병렬 실행(동시 실행 제한 옵션 포함) 등이 있습니다. Maestro의 매개변수 및 표현 언어 지원은 동적 매개변수, 코드 주입 및 워크플로우 및 단계 간 상태 공유를 허용합니다. 또한 호출 가능 단계 실행을 위한 출력 매개변수 및 유연성 및 관리 용이성을 위한 매개변수화된 워크플로우를 제공합니다. Maestro는 데이터플로우 및 기타 워크플로우 패턴을 쉽게 정의할 수 있도록 일반적인 빌딩 블록, 즉 foreach 지원, 하위 워크플로우 및 조건부 분기를 포함합니다.
넷플릭스는 사용자 경험과 시스템 복원력을 향상시키기 위해 서비스 수준의 부하 제거 기법을 구현했습니다. 이 기법은 동일한 서비스 내에서 비중요한 예측 요청보다 중요한 사용자 시작 요청을 우선순위로 처리합니다. PlayAPI, 중요한 백엔드 서비스에서 동시성 제한자와 파티셔닝을 구현하여 중요한 요청에 100% 처리량을 할당하고, 초과 처리 용량을 비중요한 요청에 사용합니다. 이러한 우선순위는 트래픽_spike 또는 고 지연 기간 동안에도 사용자 시작 요청이 높은 가용성을 유지할 수 있도록 보장합니다. 이러한 접근 방식의 성공은 서비스 우선순위를 정의하는 데 사용할 수 있는 일반적인 라이브러리의 개발로 이어졌습니다. 이 라이브러리는 CPU 사용률을 시스템 부하의 척도로 사용하여, 사용자 경험을 유지하고 자동 확장에 더 많은 시간을 제공하는 낮은 우선순위 트래픽을 점진적으로 제거합니다. 실험 결과, 이 접근 방식은 극한 부하 조건에서 비중요한 및 중요한 트래픽을 효과적으로 제거하여 합리적인 지연과 안정적인 처리량을 유지하는 것으로 나타났습니다. 넷플릭스는 사용자 경험을 저하하거나 시스템 불안정을 초래할 수 있는 반패턴, 즉 제거하지 않거나 과부하 실패를 피하는 것이 중요하다고 강조합니다.
2024년에 열린 넷플릭스의 데이터 엔지니어링 오픈 포럼은 데이터 엔지니어링 도전 과제에 대한 통찰과 솔루션을 공유하는 전문가들을 한자리에 모았다. 맥스 슈마이저는 데이터 기반 의사 결정에서 데이터 엔지니어링의 중요성을 강조했다. 스테파니 베지치 타마요와 빈빙 후는 넷플릭스의 데이터 플랫폼에서 작업 실패에 대한 ML 기반 자동 복구 시스템을 제시했다. 지데 오군조비는 기업 데이터 모델링 및 아키텍처에 생성적 AI를 사용하는 방법을 논의했다. 투리카 바트는 넷플릭스가 실시간 적응 추천을 위해 일일 18억 개의 인상을 관리하는 방법을 공유했다. 제시카 라슨은 GDPR 이후 시대에 데이터 플랫폼을 생성하는 고려 사항을 논의했다. 제이슨 리드는 데이터 웨어하우스 번들링 및 언번들링의 장점과 단점을 탐구했다. 클라크 라이트는 에어비앤비의 데이터 품질 접근 방식을 통해 데이터 품질 점수를 공유했다. 야로슬라프 제이그먼은 데이터 파이프라인 관리에 SQLMesh의 이점을 강조했다. 이 행사는 크리스 콜번, 신란 와이벨, 자이 발라니, 라시미 샴프라사드, 패트리샤 호가 주관했다.
비디오 주석자(VA)는 비디오 분류기 훈련에서 직면하는 도전을 해결하는 프레임워크입니다. 비전-언어 모델과 적극적 학습을 활용하여 효율적인 주석을 가능하게 하여, 도메인 전문가가 프로세스를 지시할 수 있습니다.
VA는 세 단계의 프로세스를 따릅니다. 텍스트-비디오 검색을 사용하여 초기 예제를 찾고, 인간-루프 시스템을 통해 적극적으로 학습하고 주석을 정제합니다. 그리고 반복적으로 주석을 검토하고 정제합니다.
VA는 샘플 효율을 개선하고 비용을 줄이며 모델 품질을 향상시킵니다. 도메인 전문가가 주석에 직접 참여할 수 있도록 하여 신뢰와 소유감을 증진시킵니다.
VA의 적극적 학습은 사용자가 점점 더 어려운 예제에 집중할 수 있도록 허용하여 주석 시간을 줄이고 모델 성능을 개선합니다.
VA는 지속적인 주석을 지원하여 빠른 배포, 모니터링 및 엣지 케이스 수정을 가능하게 합니다. 사용자가 데이터 과학자 또는 제3자 주석자에 의존하지 않고 모델을 개선하고 반복할 수 있습니다.
실험 결과 VA가 기준 방법보다 더 높은 품질의 비디오 분류기를 생성하는 것으로 나타났습니다.
VA는 다양한 비디오 이해 작업의 효율적인 주석을 가능하게 합니다. 도메인 전문가와 기계 학습 엔지니어 간의 협력을 촉진합니다.
저자는 VA를 사용하여 주석된 56개의 작업에 걸쳐 153k 개의 라벨이 포함된 데이터 세트를 제공하고, 복제 코드를 출시합니다.
VA는 전통적인 분류기 훈련 기법의 도전을 해결하여 비디오 주석의 효율성, 품질 및 사용자 참여를 향상시킵니다.
이는 시스템에 대한 소유감과 신뢰를 촉진하여 정확한 비디오 분류기의 빠른 배포와 반복적인 개선을 가능하게 합니다.
넷플릭스에서 인과 추론은 의사 결정 및 회원 경험 개선에 있어 필수적입니다. 연례 인과 추론 및 실험 정상은 전문가들이 방법론적 개발 및 혁신적인 적용을 공유하는 자리입니다.
한 발표에서는 A/B 테스트에서 연간화된 영향을 추정하는 더 빠른 자동화된 접근 방식을 개발하는 것에 초점을 두었습니다. 이는 관찰되지 않는 청구 기간 및 가입 코호트와 같은 도전 과제를 해결하는 데 있습니다.
또 다른 발표에서는 게임 이벤트를 평가하는 체계적인 프레임워크를 제시했습니다. 이 프레임워크는 제한된 데이터 및 A/B 테스트가 실용적이지 않은 개입 시나리오에서 합성 제어 모델을 사용합니다.
이중 머신 러닝은 A/B 테스트에서 다양한 지표의 중요도를 비교하는 데 적용되었습니다. 이 방법은 처리 효과가 이질적일 때 발생할 수 있는 편향을 처리합니다.
설문 AB 테스트에서 이질적인 비응답 편향을 분석하는 데 조건부 평균 처리 효과, 추정 점수 및 반복적 비례 맞춤을 사용하여 회원 의견의 정확한 표현을 보장합니다.
디자인은 넷플릭스에서 인과 추론의 필수적인 부분으로 강조되었습니다. 사용자 인터페이스 및 데이터 표현을 최적화하여 실험을 통해 의사 결정하는 데 초점을 두었습니다.
넷플릭스의 새로운 비디오 처리 플랫폼인 코스모스(Cosmos)는 마이크로서비스를 사용하여 미디어 처리 파이프라인을 현대화합니다. 비디오 인코딩 서비스(VES)는 미들레인 콘텐츠를 스트리밍 또는 스튜디오용 비디오 스트림으로 인코딩하는 핵심 마이크로서비스입니다.
VES는 여러 코덱, 해상도 및 품질 수준을 지원하며, 낮은 지연 시간을 위한 청크 인코딩을 사용합니다. Optimus라는 API 계층은 외부 사용자에게 안정적인 인터페이스를 제공합니다.
워크플로우 계층인 플라톤(Plato)은 방향성 비순환 그래프(DAG)와 맵리듀스 병렬성을 사용하여 인코딩 단계를 조율합니다. 컴퓨팅 집약적인 작업은 스트라툼(Stratum)이라는 컴퓨팅 계층에 위임되며, 스트라툼 함수(Stratum Functions)가 도커 이미지에 패키징되어 있습니다.
VES는 독립적인 릴리스 및 인코더 업그레이드를 가능하게 하기 위해 다양한 코덱 형식에 대한 여러 스트라툼 함수를 사용합니다. 플랫폼은 미디어 액세스 패턴에 대한 추상화를 제공하여 스트라툼 함수 코드를 단순화합니다.
리소스 요구 사항은 벤치마킹을 통해 결정되며, "컨테이너 모양"은 코덱 형식 및 해상도에 따라 리소스를 할당합니다. 자동화된 릴리스 파이프라인 및 광범위한 테스트를 통해 지속적인 릴리스가 가능합니다.
생산 메트릭 및 로그는 모니터링 및 경고에 사용되며, 메트릭이 크게 벗어나면 자동 서비스 롤백이 포함됩니다. VES를 구축하는 과정에서 얻은 교훈은 팀의 마이크로서비스 개발에서 이후 설계 선택을 안내했습니다.
넷플릭스의 그래프 검색, 이전에는 스튜디오 검색으로 알려졌었습니다. 이제 콘텐츠 엔지니어링을 넘어선 엔지니어링 조직 전체에서 사용됩니다. 100개 이상의 애플리케이션과 50개의 인덱스를 지원합니다. 영화의 상태가 변경될 때 누가 통보를 받을지 알 수 있는 문제를 해결하기 위해 그래프 검색은 Elasticsearch의 퍼콜레이터 필드를 사용하여 역방향 검색을 구현했습니다.
역방향 검색은 기존 인덱스에 대한 "SavedSearches"를 생성할 수 있습니다. 이러한 필터는 Elasticsearch 쿼리로 번역되어 퍼콜레이터 필드에 인덱싱됩니다. 문서가 제출되면 기존 쿼리와 일치하는지 확인하여 이를 반환하는 쿼리를 확인합니다.
이 기능은 변경 이벤트에 대한 통보를 정확하게 제공하여 분산 그래프에 미치는 영향을 줄입니다. 역방향 검색을 지원하기 위해 그래프 검색의 인덱싱 파이프라인은 저장된 검색을 인덱싱하는 별도의 파이프라인을 포함하도록 수정되었습니다. 인덱스 템플릿을 사용하여 매핑을 맞출 수 있습니다.
퍼콜레이터 인덱싱 파이프라인은 Data Mesh CDC 이벤트와 그래프 검색 DGS 변이를 사용하여 저장된 검색을 번역하고 인덱싱합니다. 버전 관리는 새로운 인덱스 버전과 파이프라인을 생성하여 기존 파이프라인을 중단하지 않고 매핑 변경을 처리할 수 있습니다.
역방향 검색은 통보 이외에도 동적 기준 매쳐를 생성하는 데 사용할 수 있습니다. 영화 매칭 서비스는 역방향 검색을 사용하여 매칭 기준에 따라 영화를 분류합니다. 이 패턴은 그래프 검색의 모든 인덱스에 확장할 수 있습니다.
게다가 역방향 검색은 더 반응적인 UI를 가능하게 하여 인덱스 변경에 따라 결과를 업데이트하는 구독을 생성할 수 있습니다. 저장된 쿼리와 일치합니다.