AI и ML Новости на русском Подписаться
"AI & ML News" - это коллекция технологических заметок, посвященных искусственному интеллекту и машинному обучению. Здесь собраны актуальные новости и обзоры последних разработок в области ИИ и МО.
Лента охватывает широкий спектр тем, включая новые алгоритмы, приложения и исследования. Освещаются тенденции в индустрии и влияние ИИ и МО на различные сектора экономики.
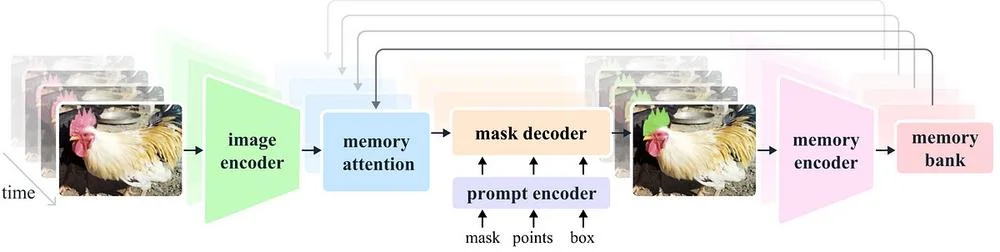
Материалы затрагивают такие области, как нейронные сети, глубокое обучение и обработка естественного языка. Рассматриваются примеры применения ИИ в здравоохранении, финансах и других отраслях.
Публикации будут интересны как специалистам - разработчикам и аналитикам данных, так и всем, кто интересуется развитием технологий ИИ. Затрагиваются вопросы этики ИИ и конфиденциальности данных.
Лента знакомит читателей с ключевыми игроками рынка ИИ - от крупных компаний до многообещающих стартапов. Представлена информация об инструментах и платформах для разработки ИИ-систем.
"AI & ML News" стремится предоставлять объективную и актуальную информацию о развитии искусственного интеллекта и машинного обучения.