RSS Google AI Blog
Follow
Achieving 10,000x training data reduction with high-fidelity labels
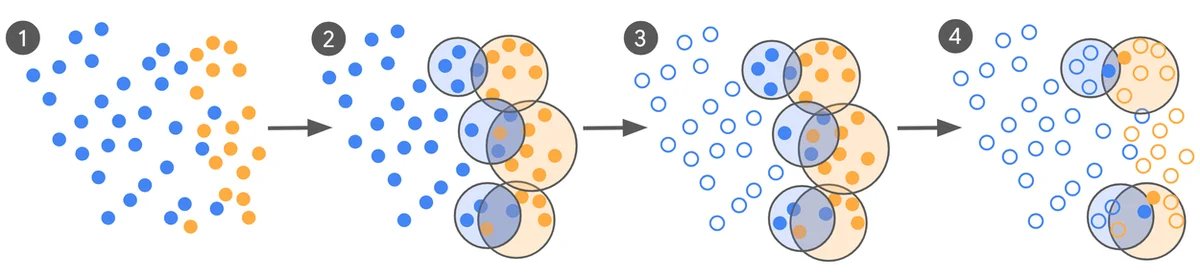
Classifying unsafe ad content is a complex task that large language models (LLMs) are well-suited for due to their contextual understanding. However, fine-tuning LLMs for such tasks requires high-quality, large-scale training data, which is expensive and time-consuming to curate. Concept drift, where safety policies change, necessitates frequent retraining, increasing costs. To address this, a new active learning curation process dramatically reduces the amount of training data needed while improving model alignment with human experts. This process identifies the most valuable examples for annotation, significantly reducing data requirements. Experiments showed a reduction in training data from 100,000 to under 500 examples, with model alignment improving by up to 65%. The curation process begins with a zero-shot LLM labeling data, followed by clustering to identify confusable examples. These informative and diverse examples are then sent to human experts for labeling. Expert labels are used to both evaluate and fine-tune the models iteratively. The process relies on Cohen's Kappa to measure alignment, as ground truth labels are often ambiguous. Baseline models fine-tuned on large crowdsourced datasets performed less effectively compared to curated models. The new method demonstrates that carefully curating fewer, more informative examples can lead to significant performance gains with drastically less data. This approach is particularly beneficial for domains like ad safety with rapidly evolving content.