RSS Google AI Blog
Follow
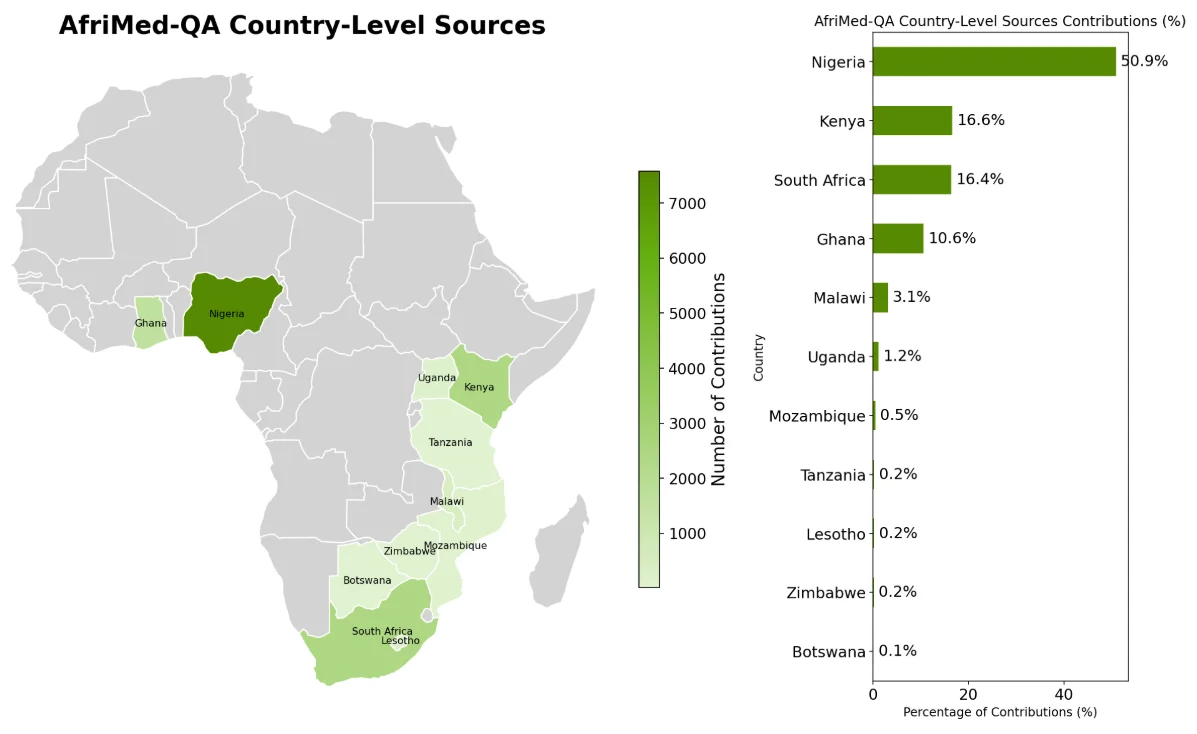
AfriMed-QA: Benchmarking large language models for global health
This paper introduces AfriMed-QA, a novel benchmark dataset for evaluating large language models (LLMs) in the context of African healthcare. The dataset compiles medical questions and answers in English from 16 African countries and 60 medical schools. AfriMed-QA includes multiple-choice questions, short answer questions, and consumer queries across various medical specialties. The authors evaluated various LLMs, finding larger models performed better on this dataset. Human evaluations of LLM responses showed promising results, particularly for consumer queries. A leaderboard was created to facilitate model comparison and track progress. The team plans to expand the dataset to include multilingual and multimodal data. The study acknowledges limitations, including geographic representation, and highlights the need for culturally relevant evaluations. The research underscores the importance of adapting LLMs for use in diverse healthcare settings. AfriMed-QA aims to foster the development of equitable AI tools for healthcare in Africa and beyond. This project received the Best Social Impact Paper Award at ACL 2025. The AfriMed-QA dataset and evaluation code are openly available.