RSS Google AI Blog
Follow
Beyond billion-parameter burdens: Unlocking data synthesis with a conditional generator
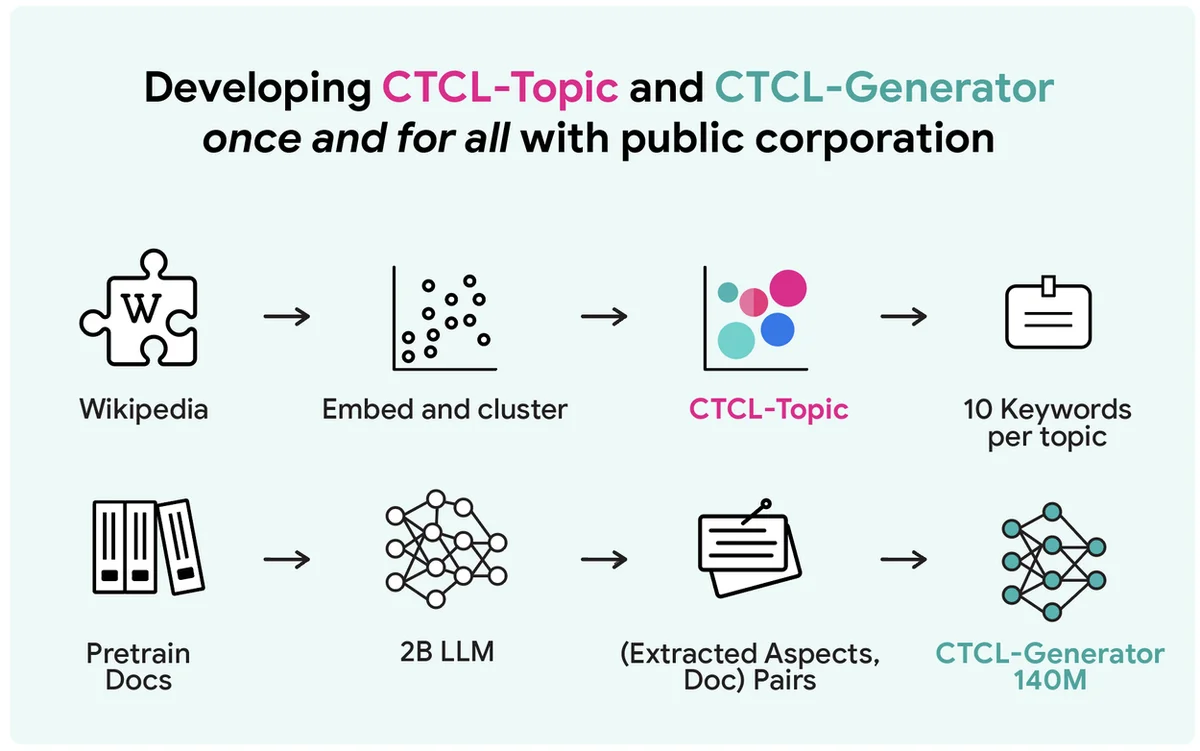
Generating large-scale differentially private synthetic text data faces a privacy-computation-utility trade-off. A common but computationally expensive method involves fine-tuning large language models on private data. Existing API-based approaches like Aug-PE rely on manual prompts and struggle with private information utilization. The proposed CTCL framework generates privacy-preserving synthetic data without fine-tuning massive LLMs or requiring extensive prompt engineering. It utilizes a lightweight 140 million parameter model, making it suitable for resource-constrained environments. CTCL conditions generation on topic information to match private data distributions. Unlike Aug-PE, CTCL can produce unlimited synthetic data samples without additional privacy costs. Experiments show CTCL outperforms baselines, particularly under strong privacy guarantees, demonstrating its effectiveness in capturing useful information. Ablation studies confirm the importance of pre-training and keyword-based conditioning for CTCL's performance and scalability. The core idea of CTCL can be extended to larger models for improved real-world applications.