RSS Google AI Blog
Follow
Learning to clarify: Multi-turn conversations with Action-Based Contrastive Self-Training
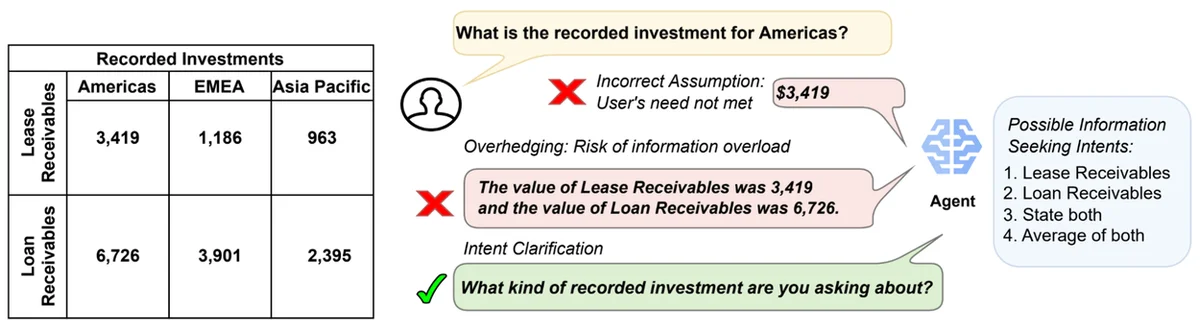
Large language models (LLMs) have become a leading paradigm for developing intelligent conversational agents, but they often lack multi-turn conversational skills such as disambiguation. To address this, the authors propose Action-Based Contrastive Self-Training (ACT), a quasi-online preference optimization algorithm that enables data-efficient dialogue policy learning in multi-turn conversation modeling. ACT demonstrates substantial conversation modeling improvements over standard tuning approaches like supervised fine-tuning and DPO. The authors also introduce AmbigSQL, a novel task for disambiguating information-seeking requests for complex Structured Query Language (SQL) code generation. ACT involves constructing a preference dataset, synthesizing rejected responses, and tuning the policy model using the DPO objective. The authors experiment with ACT using open-weight LLMs on a diverse set of conversational datasets and compare it with various competitive baselines, including supervised fine-tuning, iterative reasoning preference optimization, and prompting Gemini and Claude with in-context learning examples. ACT achieves the best performance across all metrics, with up to a 19.1% relative improvement over supervised fine-tuning when measuring the tuned model's ability to implicitly recognize ambiguity. The authors also conduct ablation studies to understand the benefits of each component of ACT and find that action-based preferences, on-policy sampling, and trajectory simulation are crucial for improved multi-turn goal completion. Overall, ACT is a model-agnostic approach that can improve performance regardless of pre-existing alignment with human feedback.