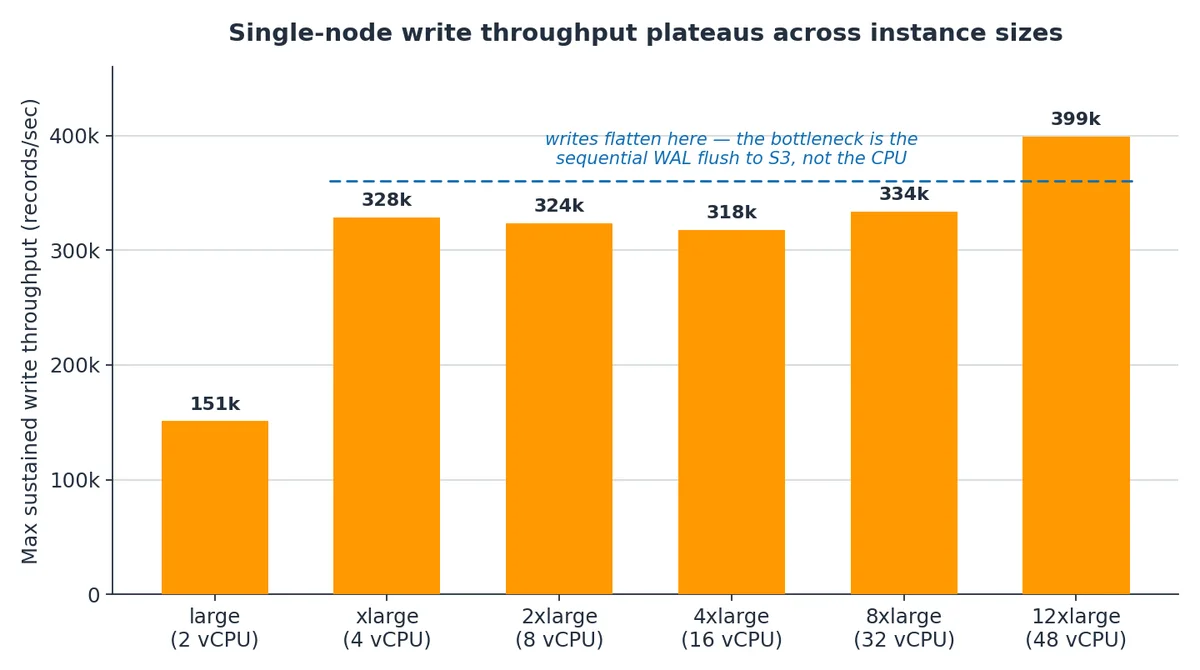
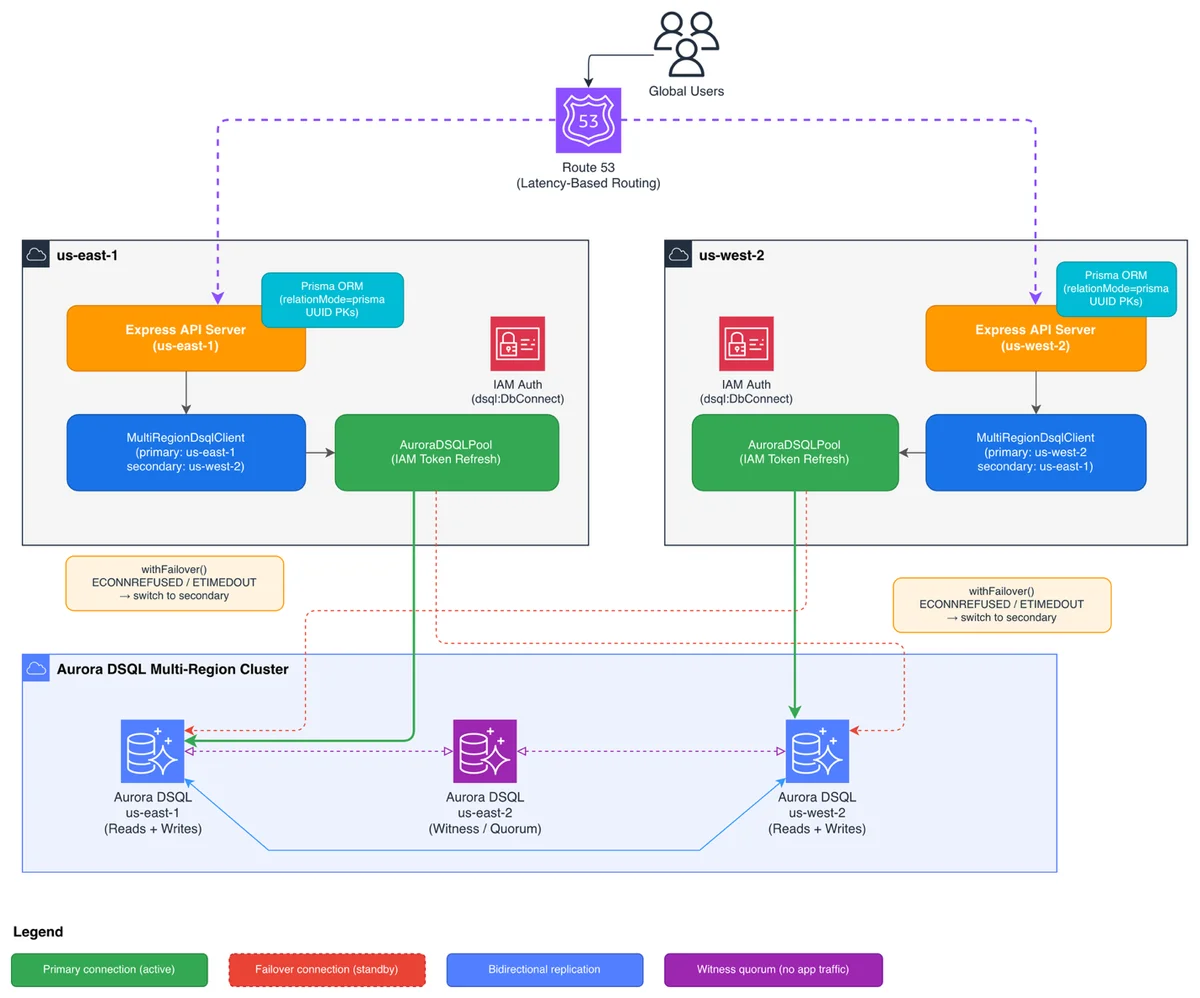
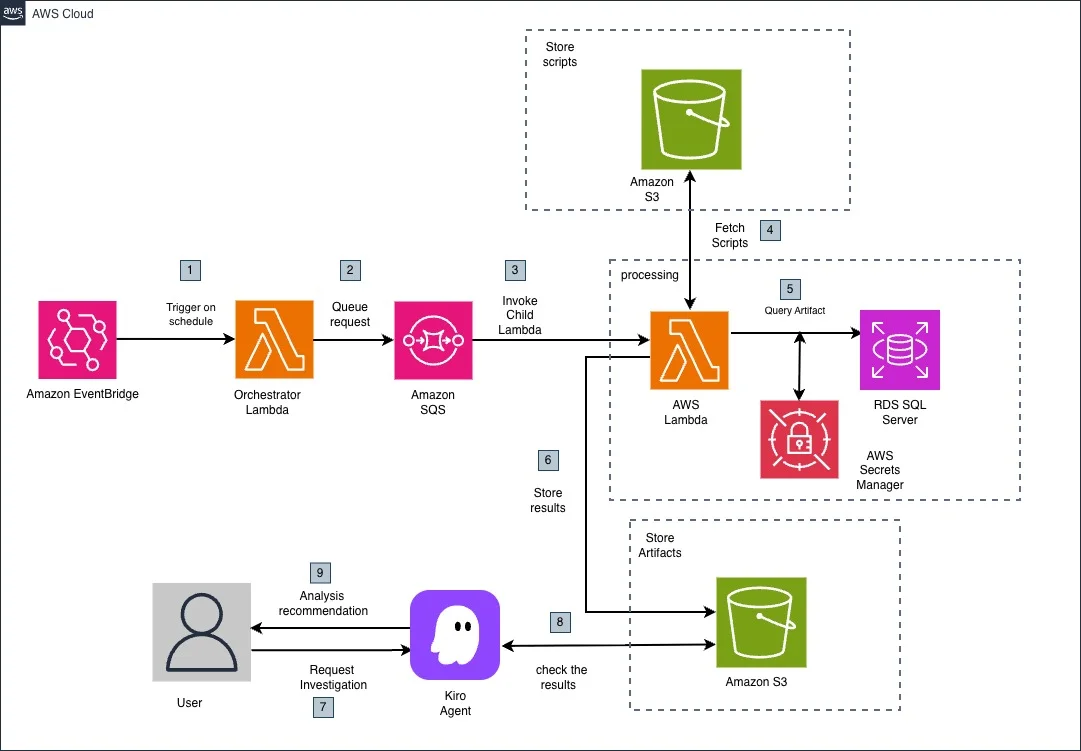
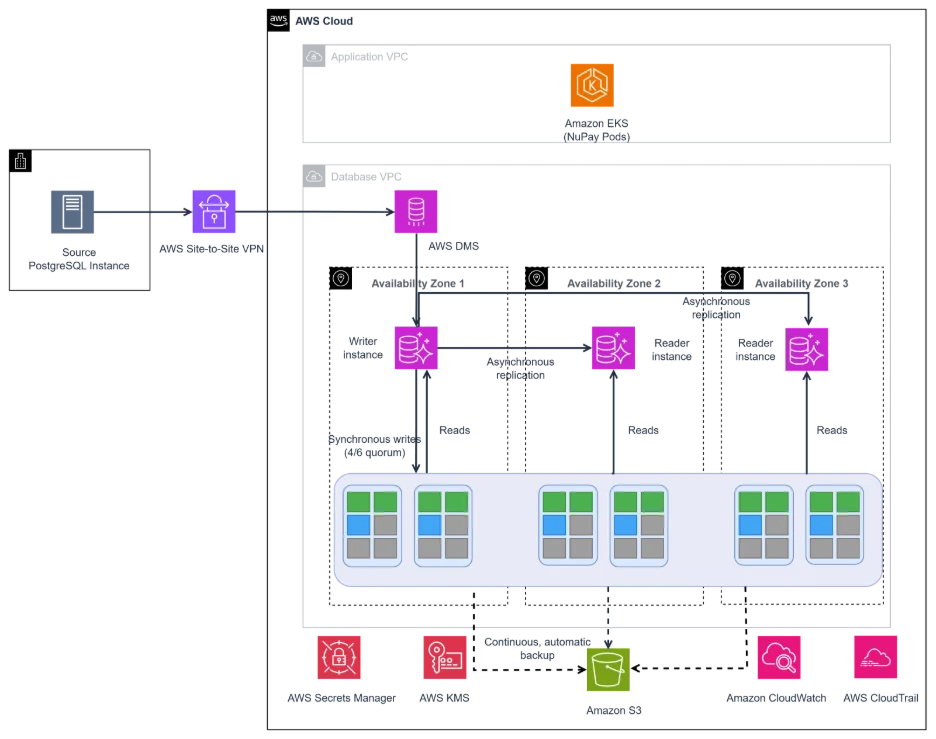
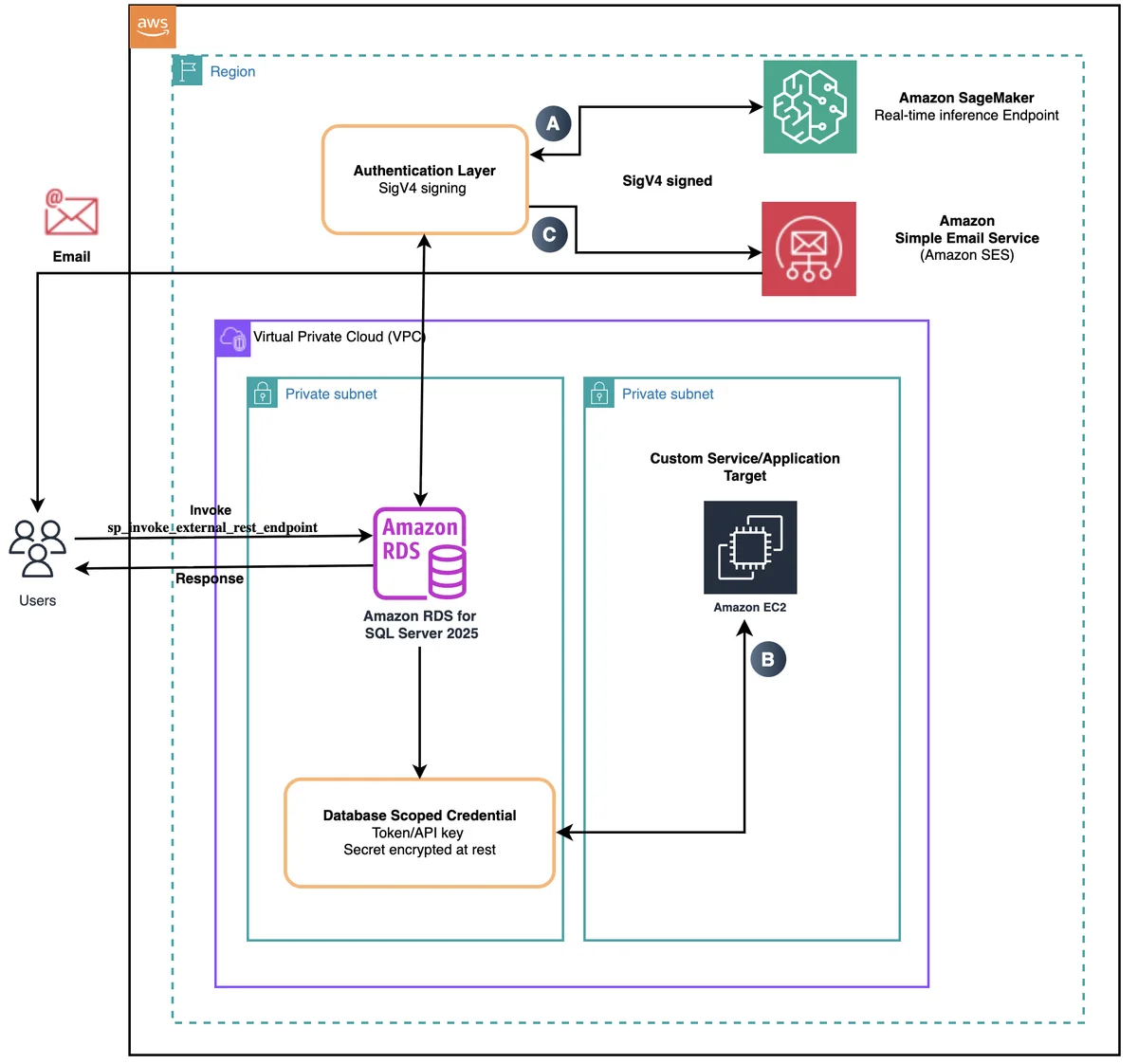
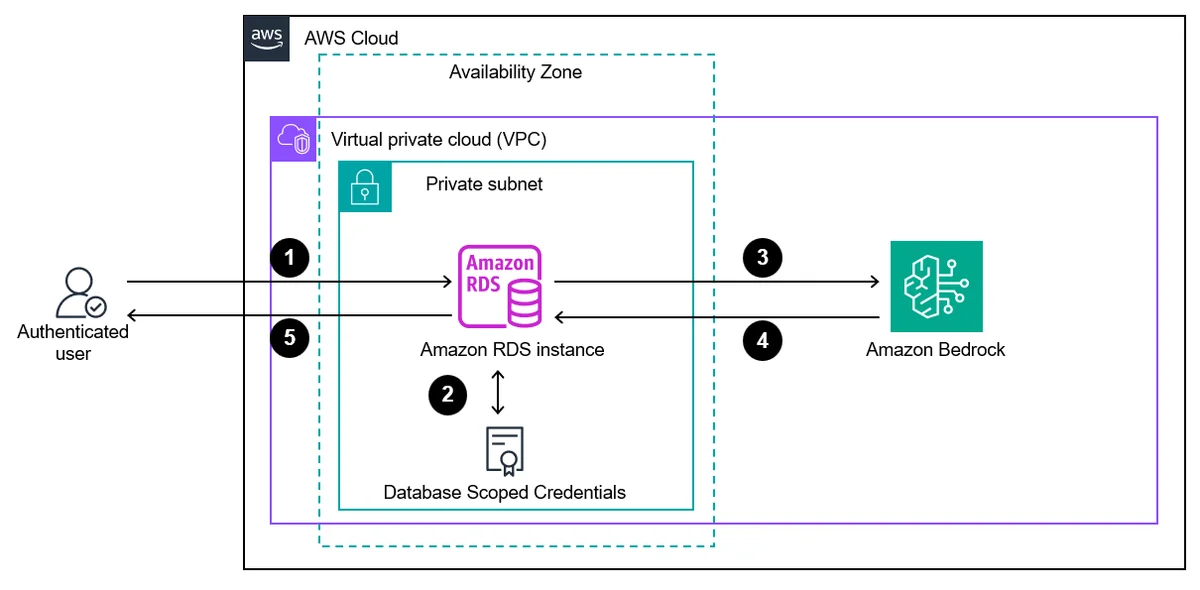
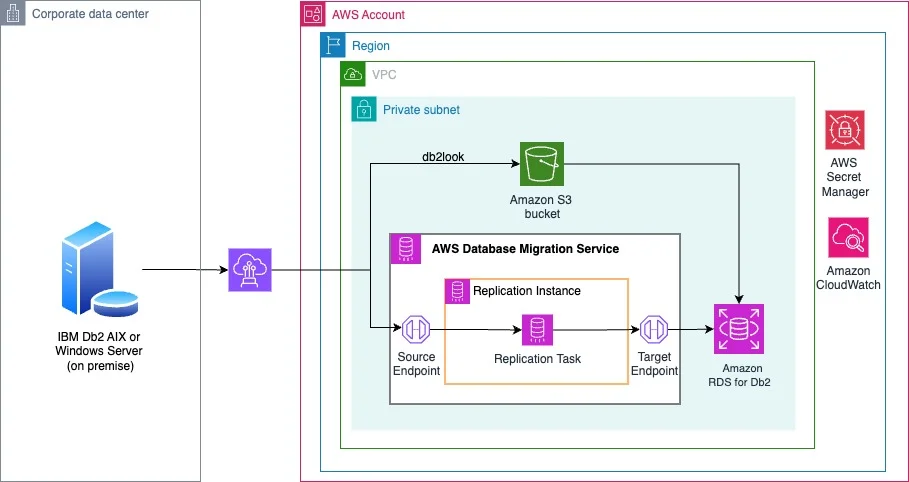
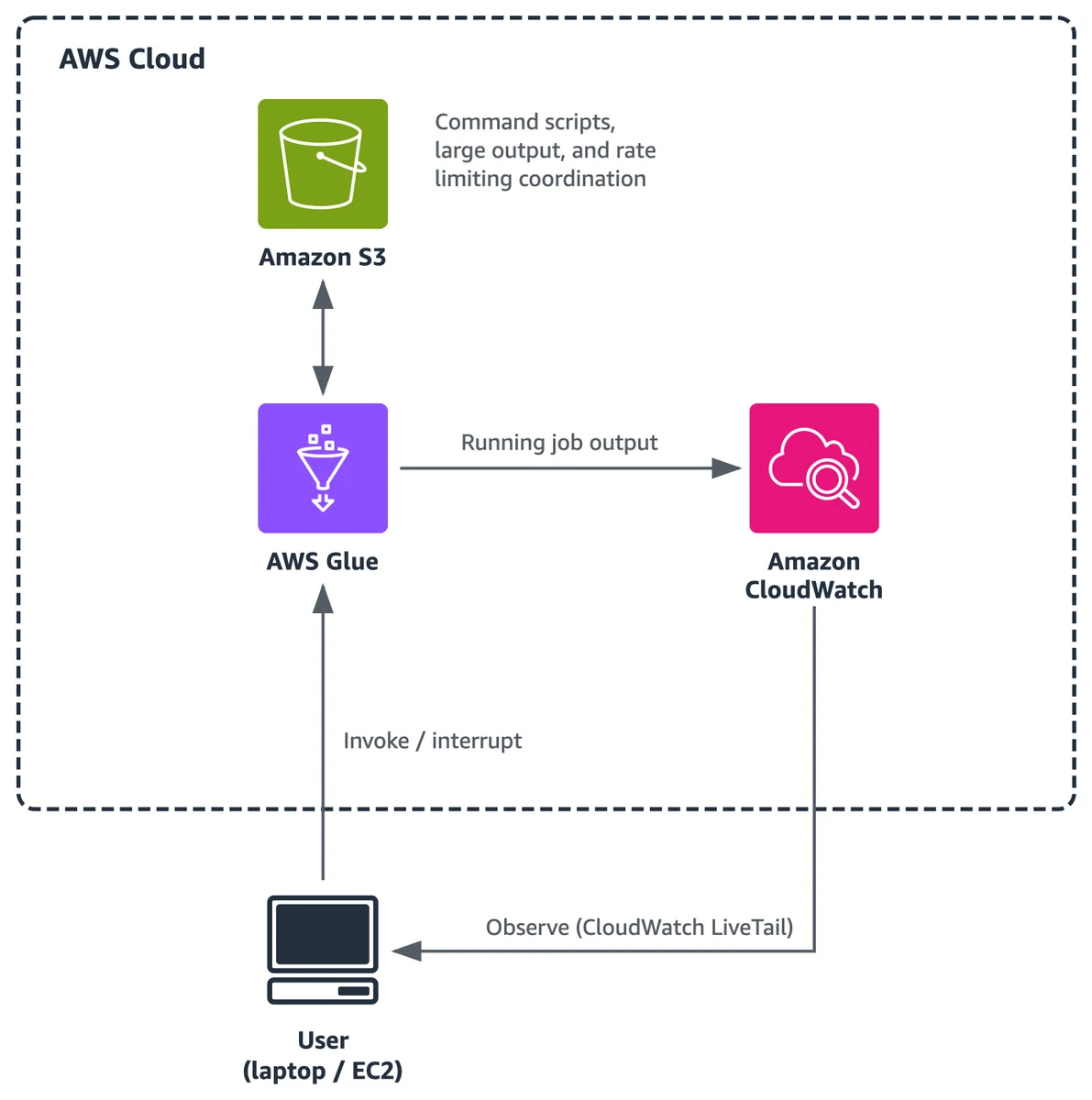
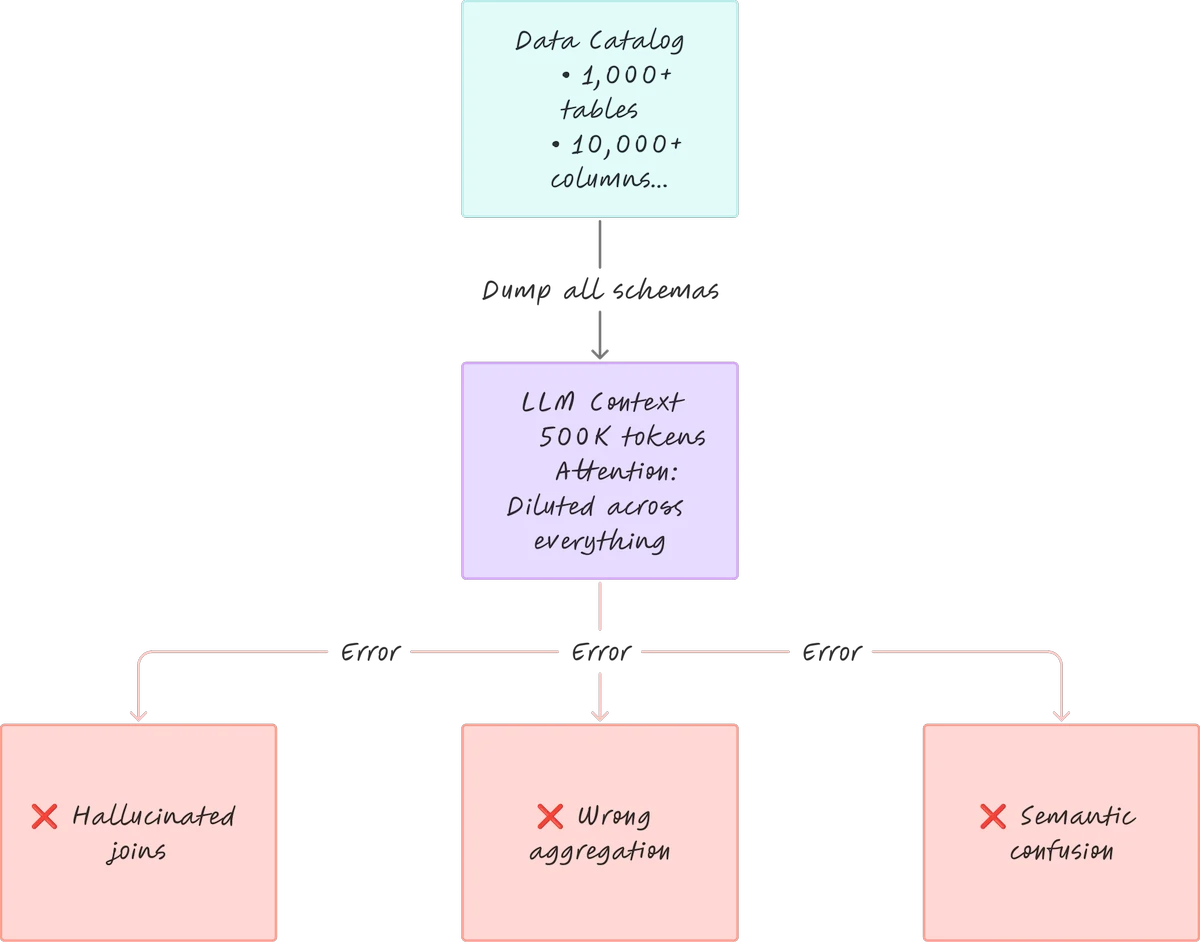
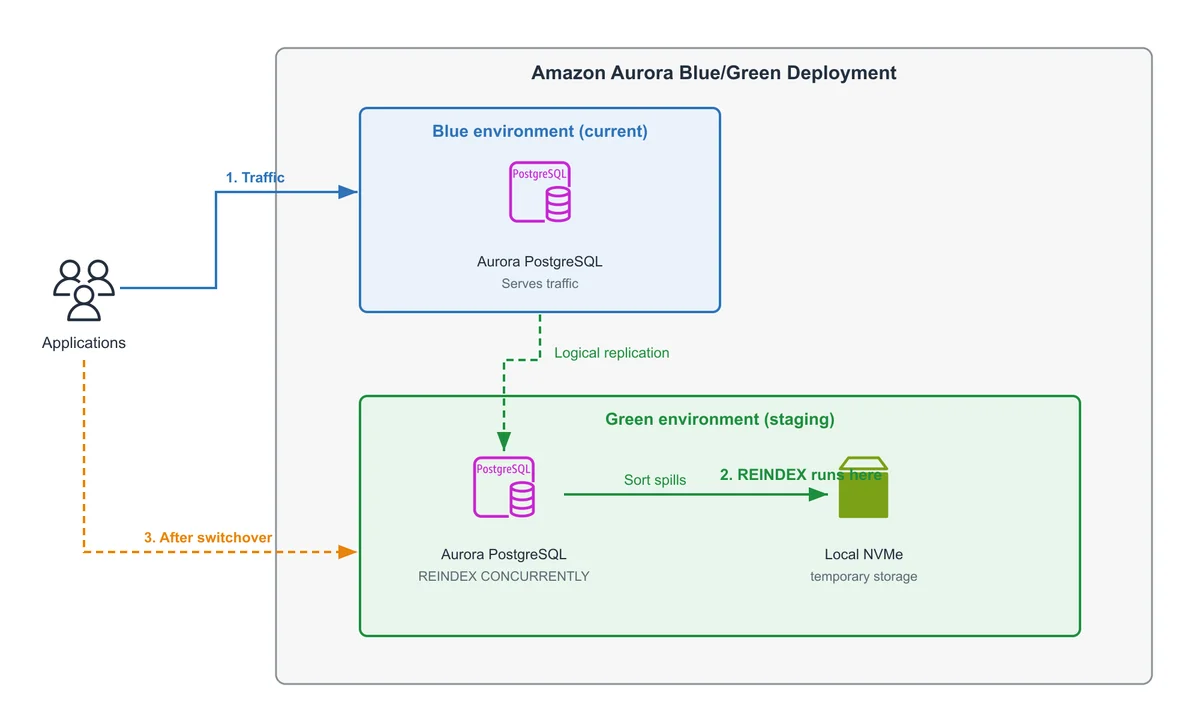
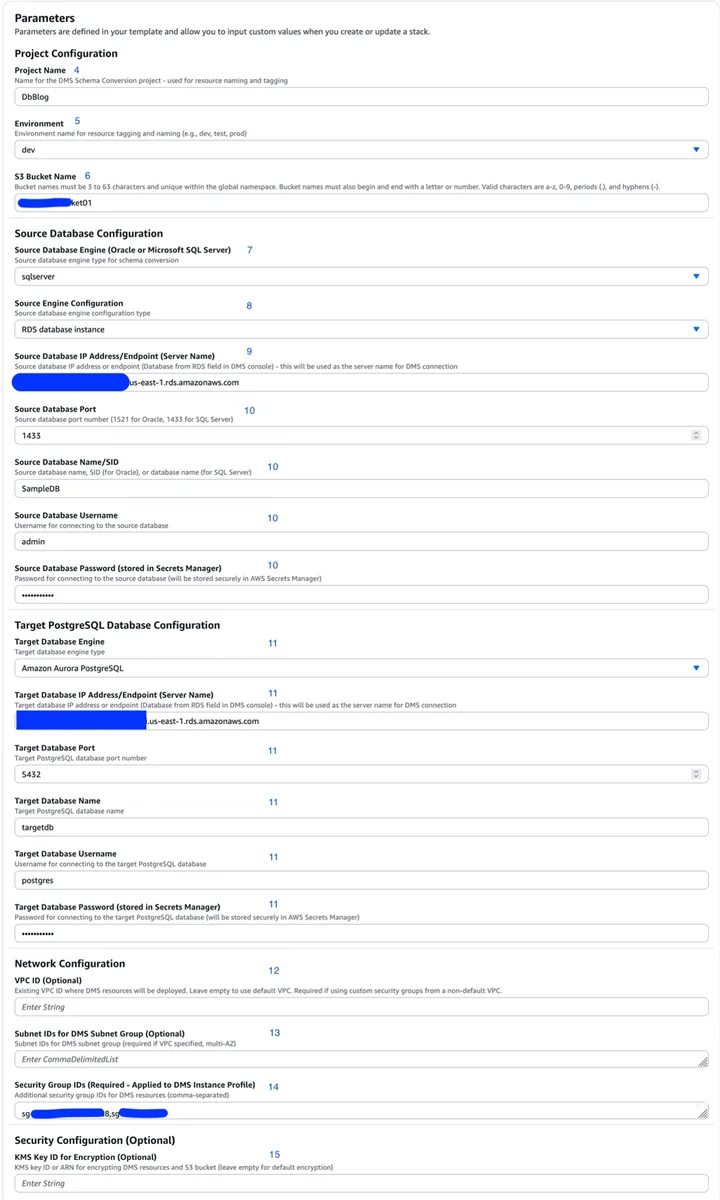
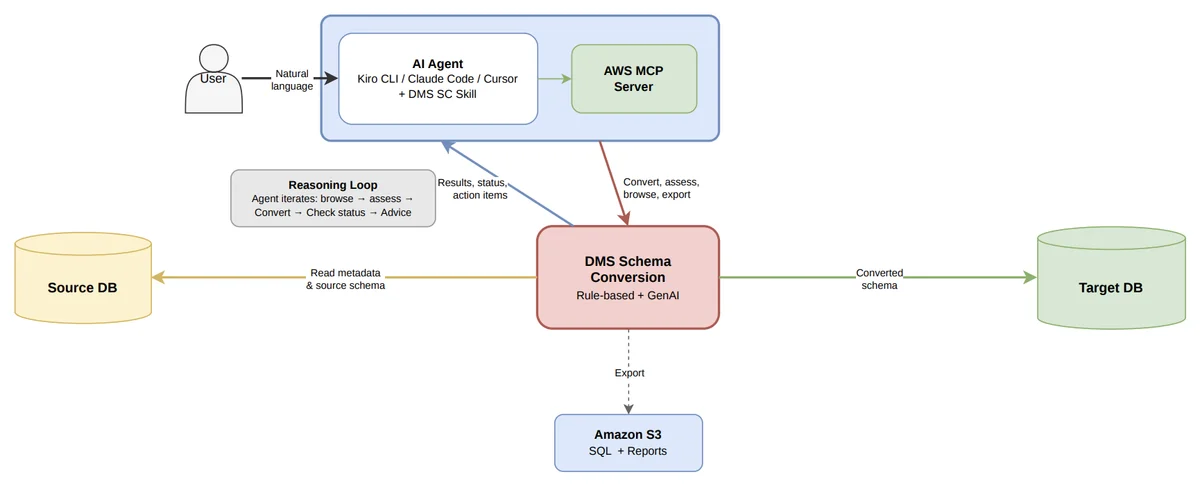
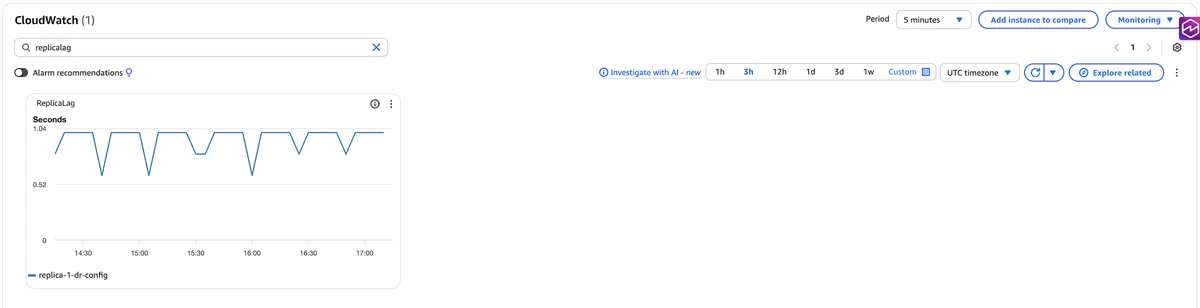
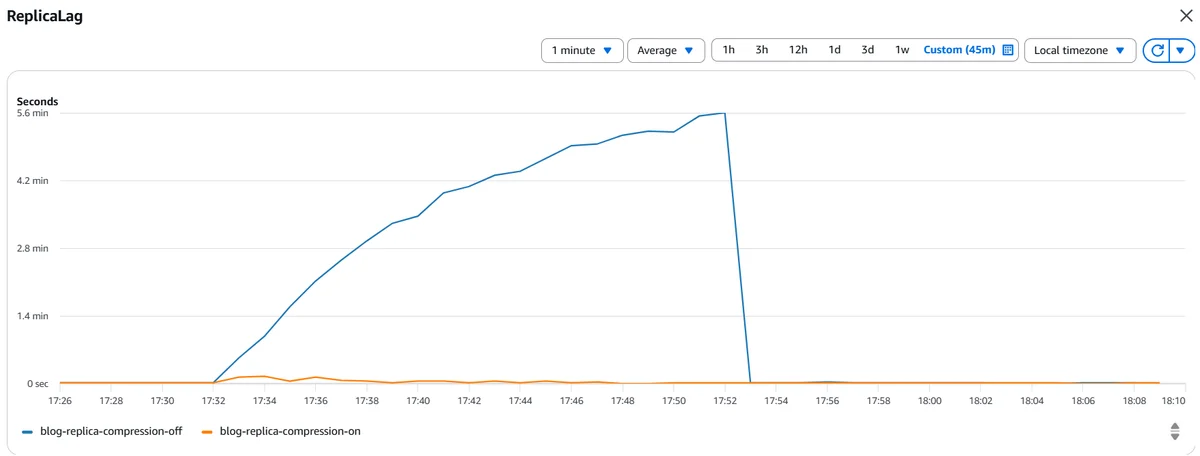
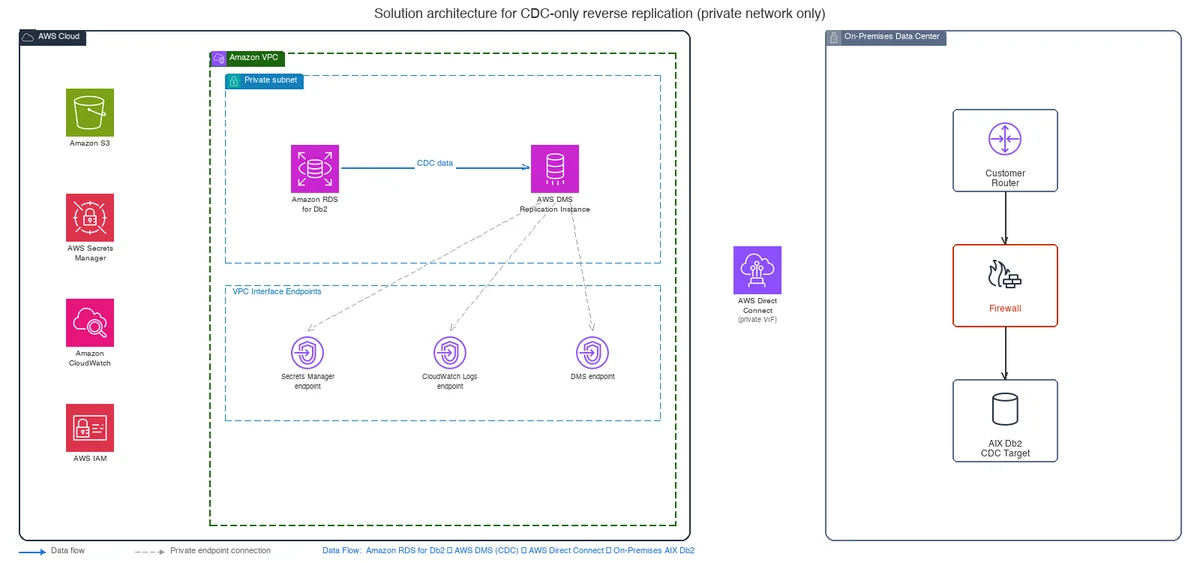
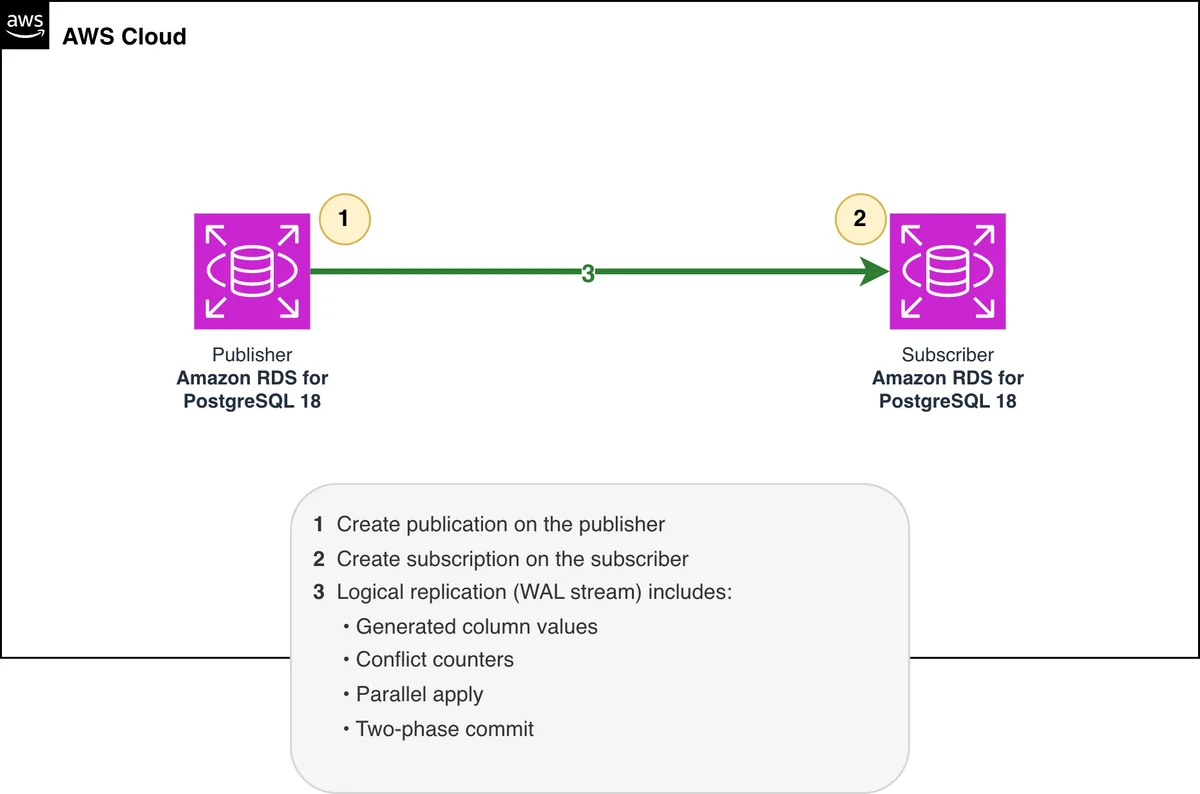
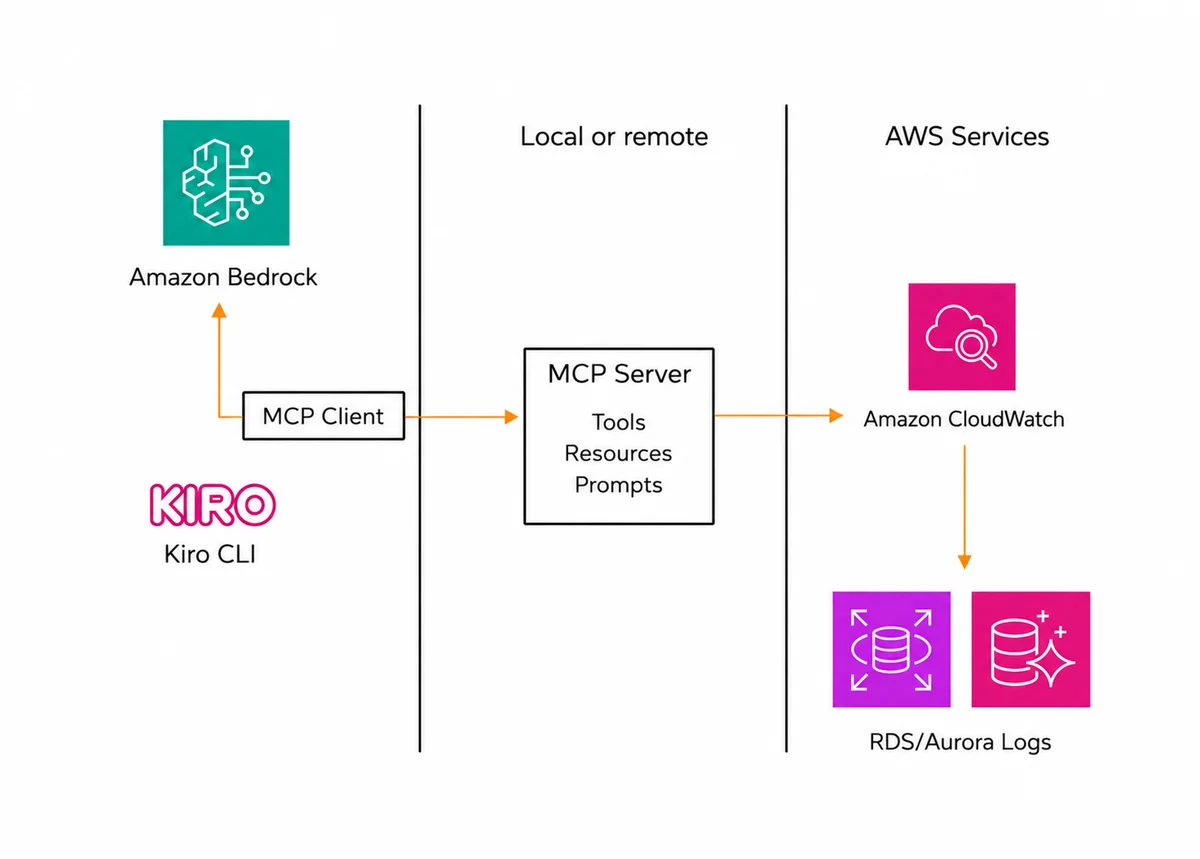
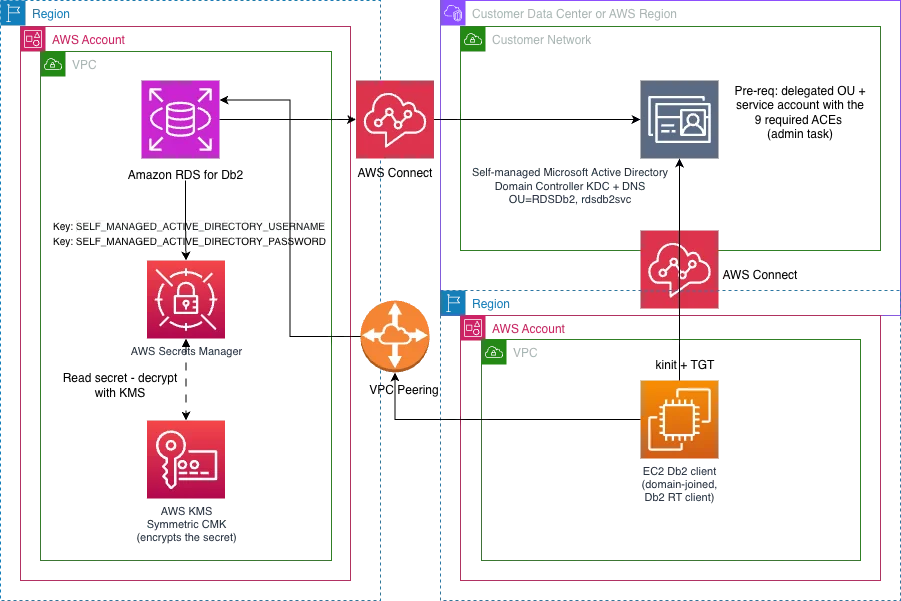
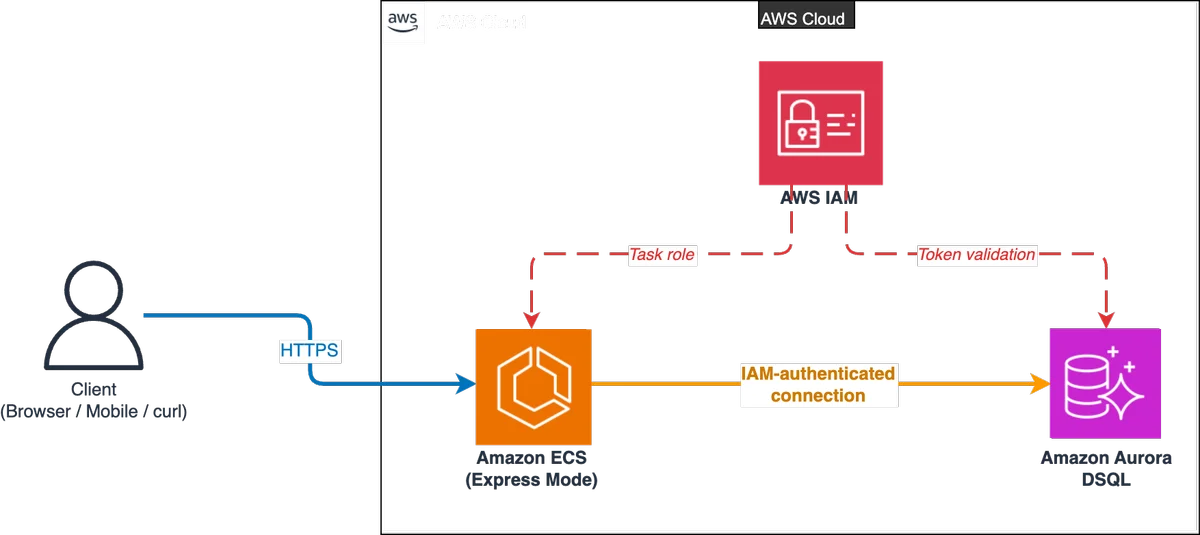
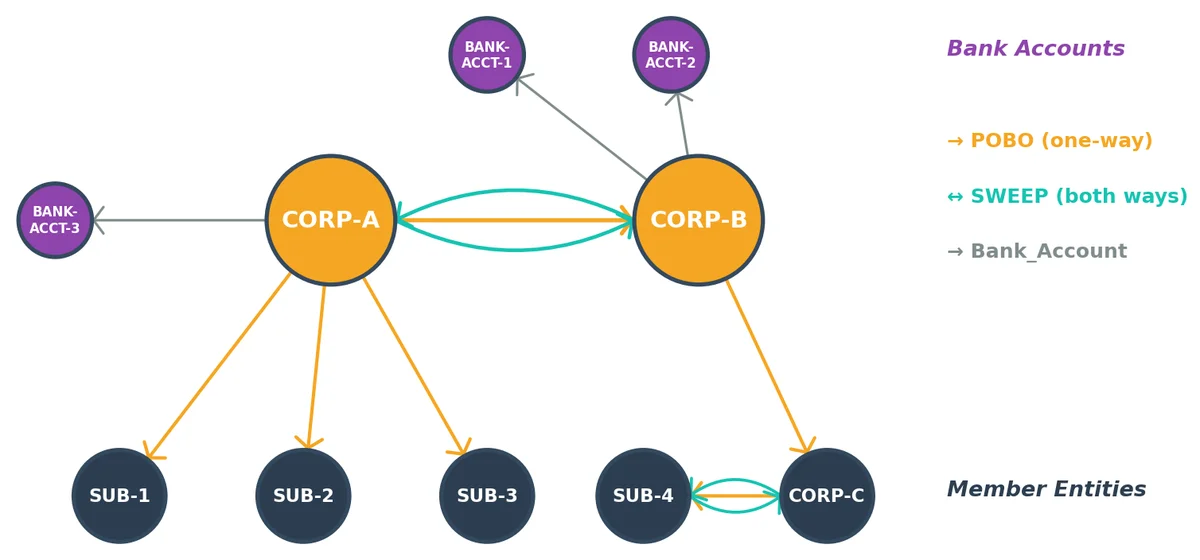
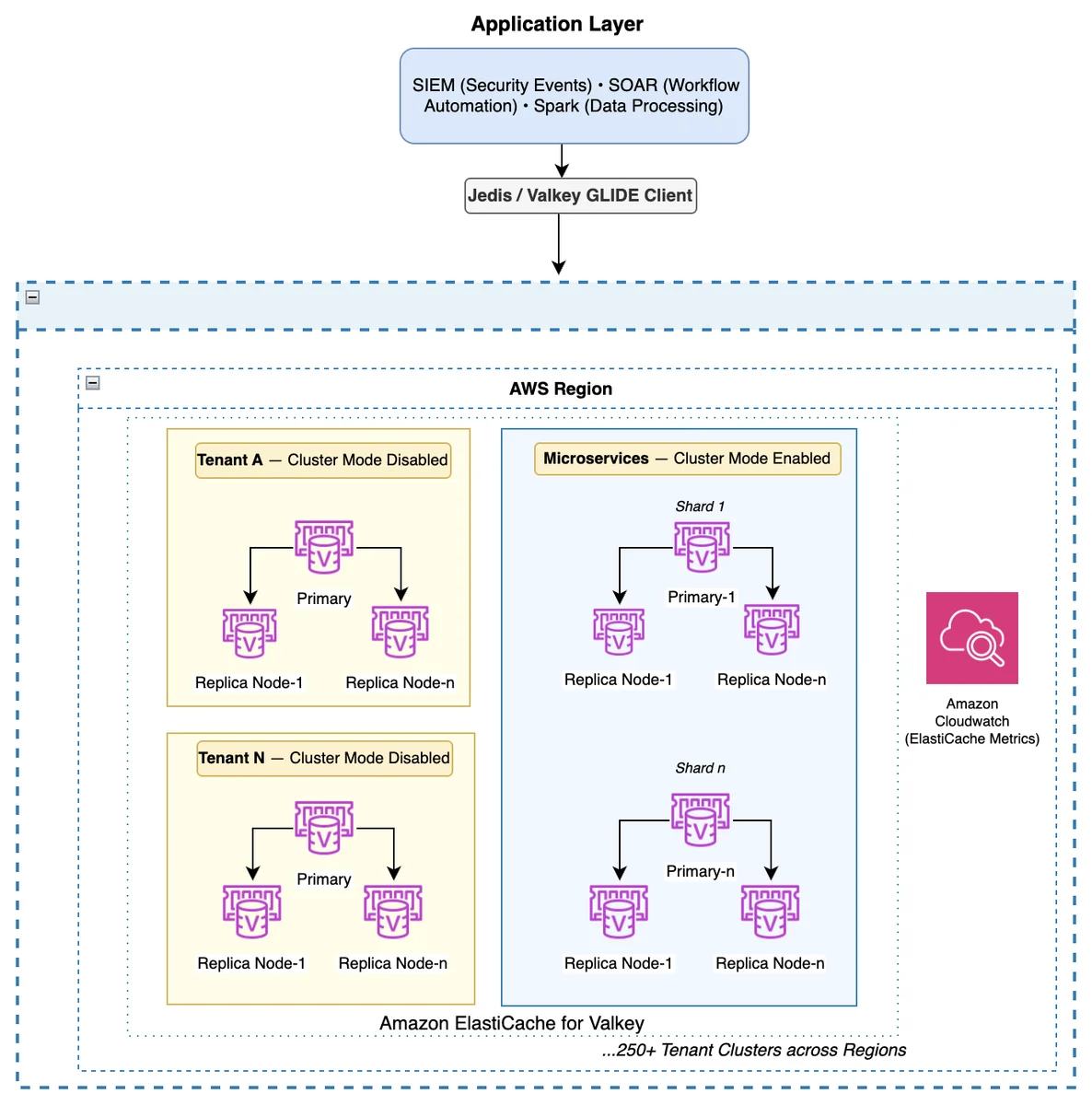
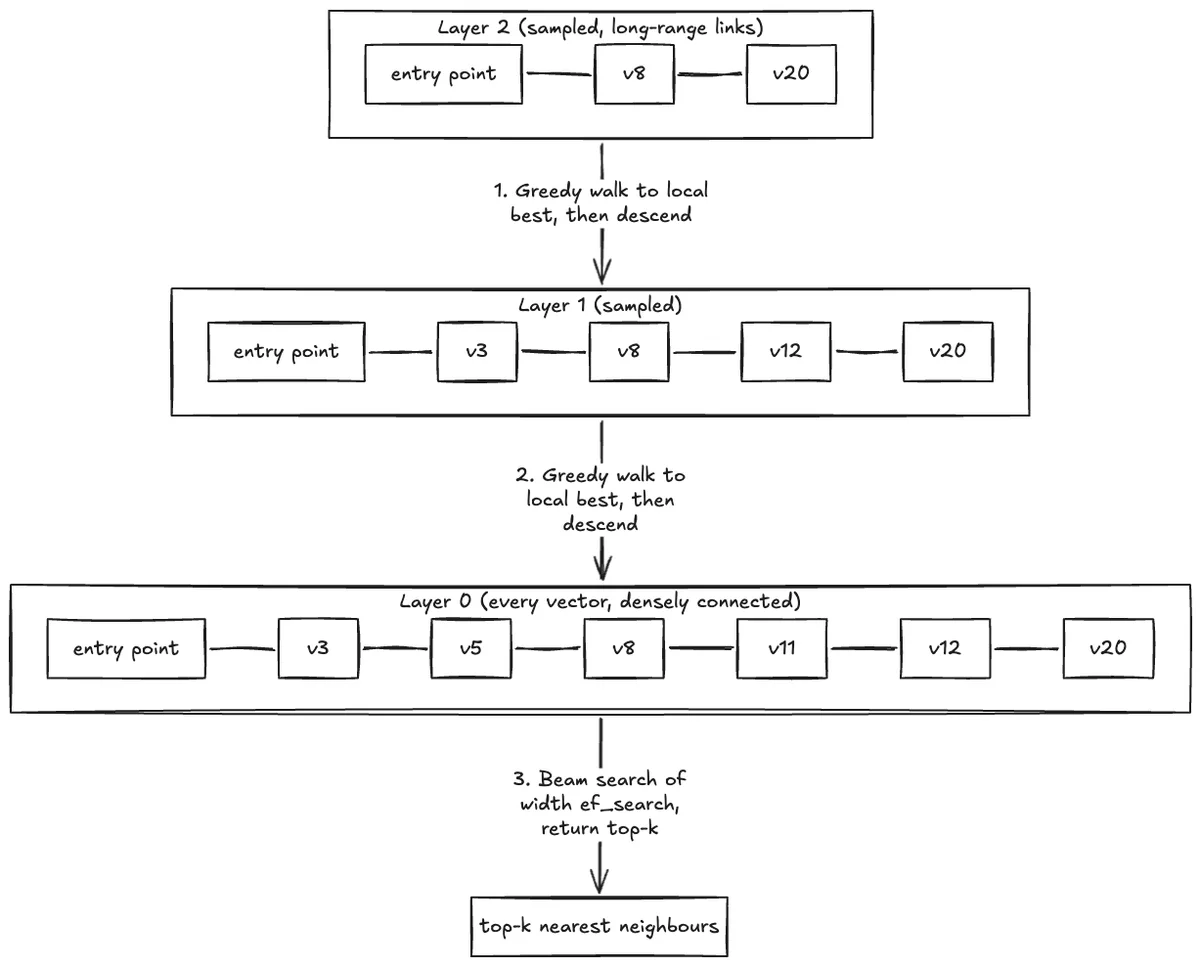
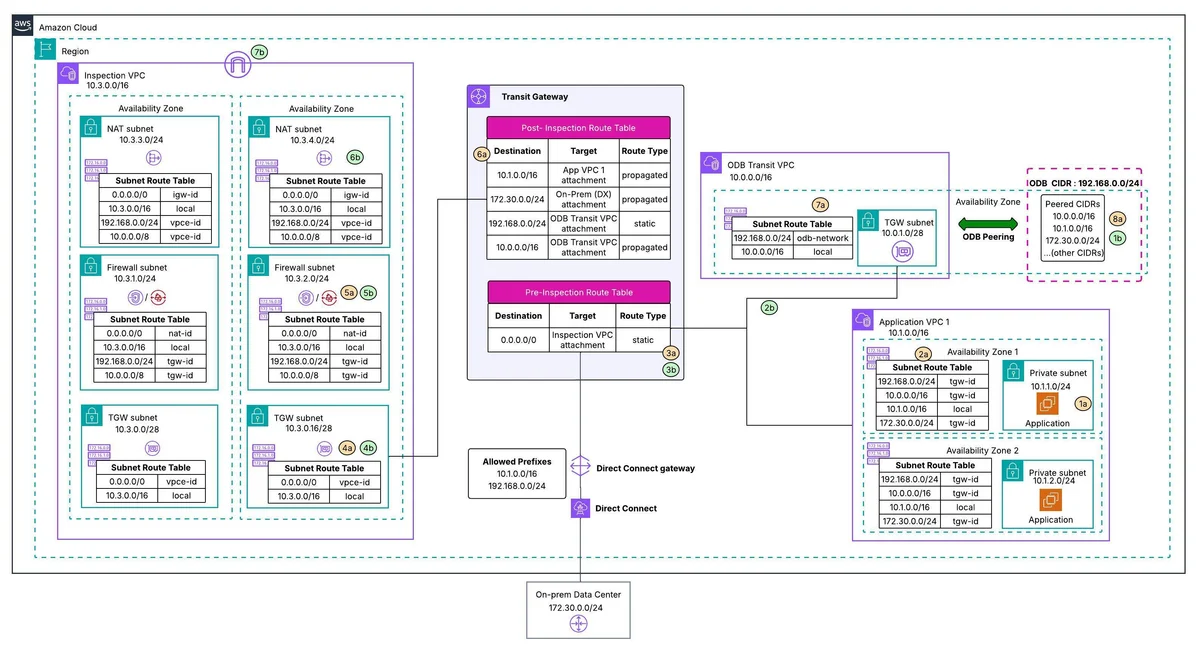
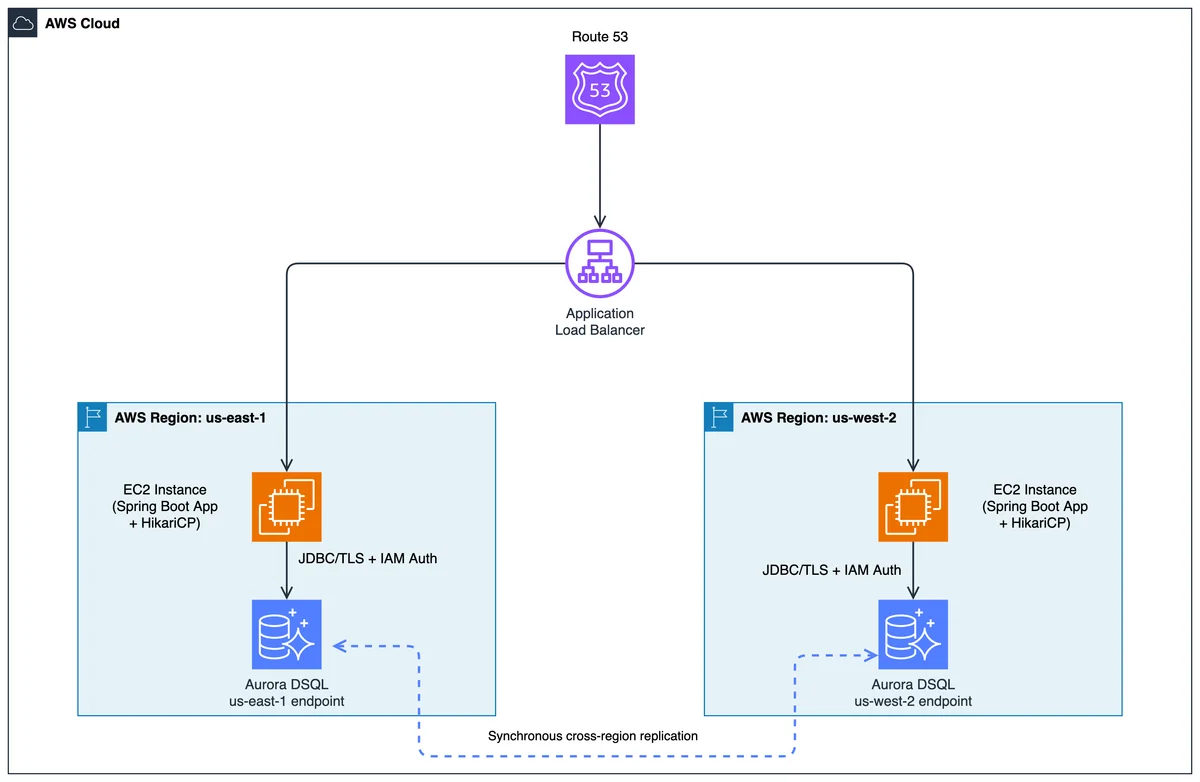
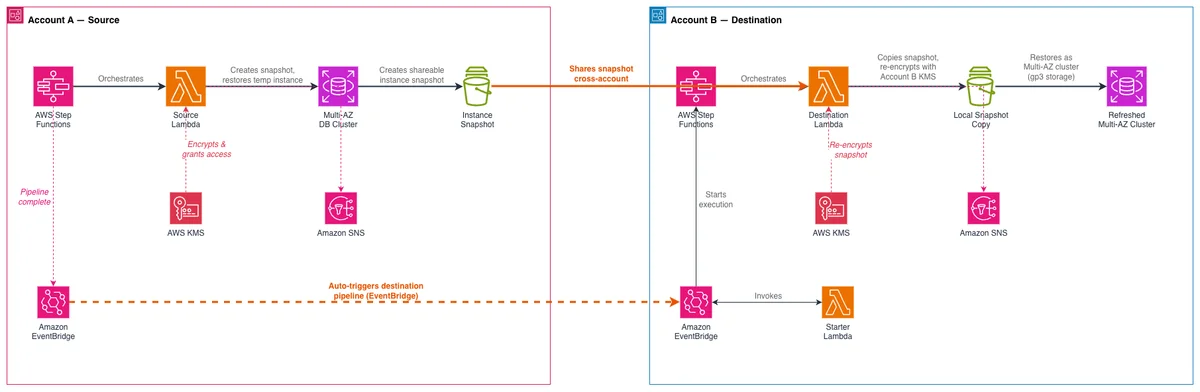
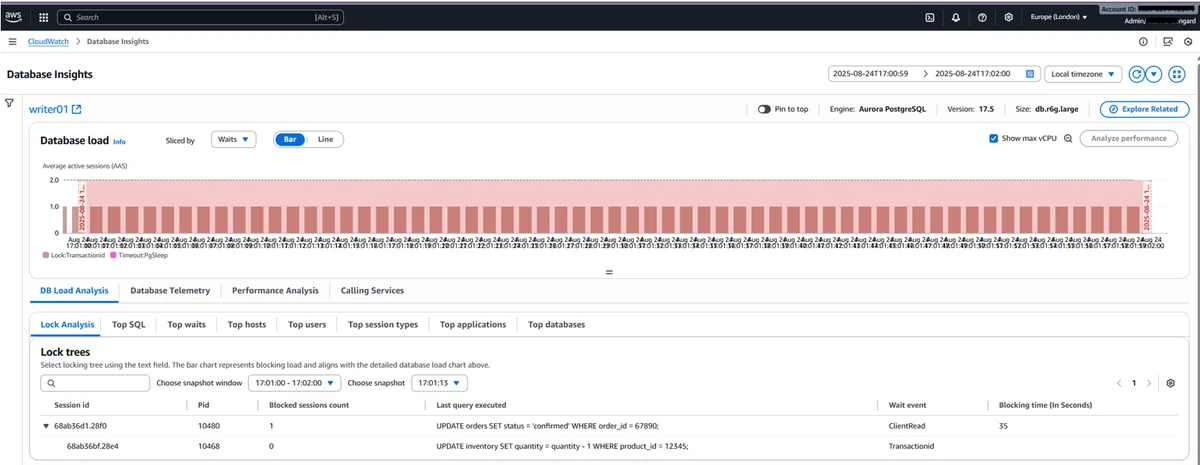
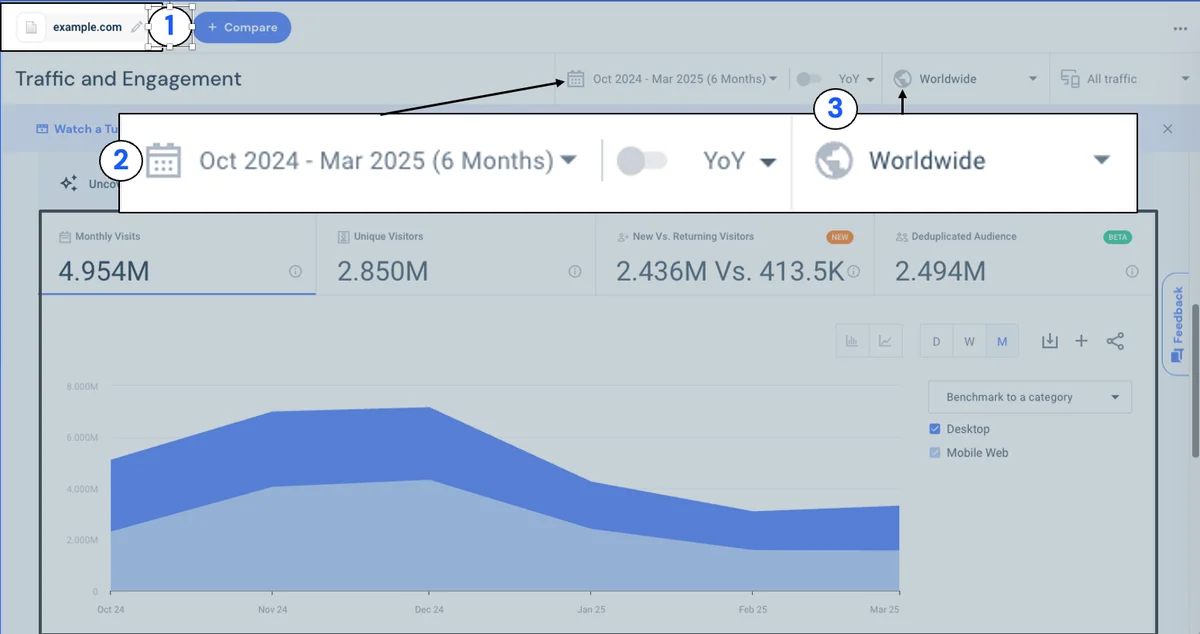
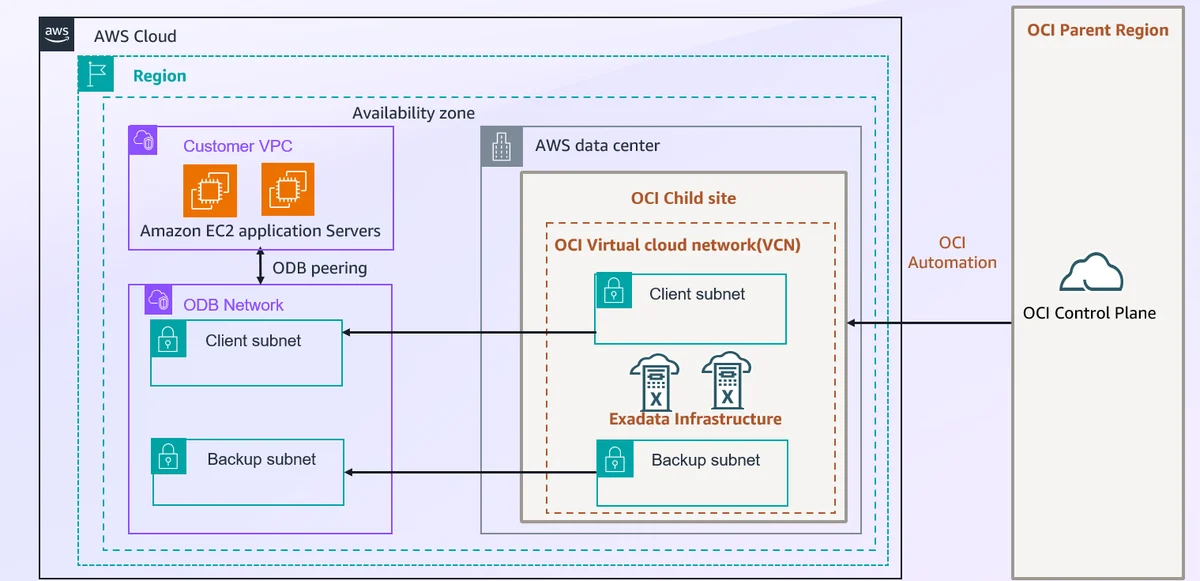
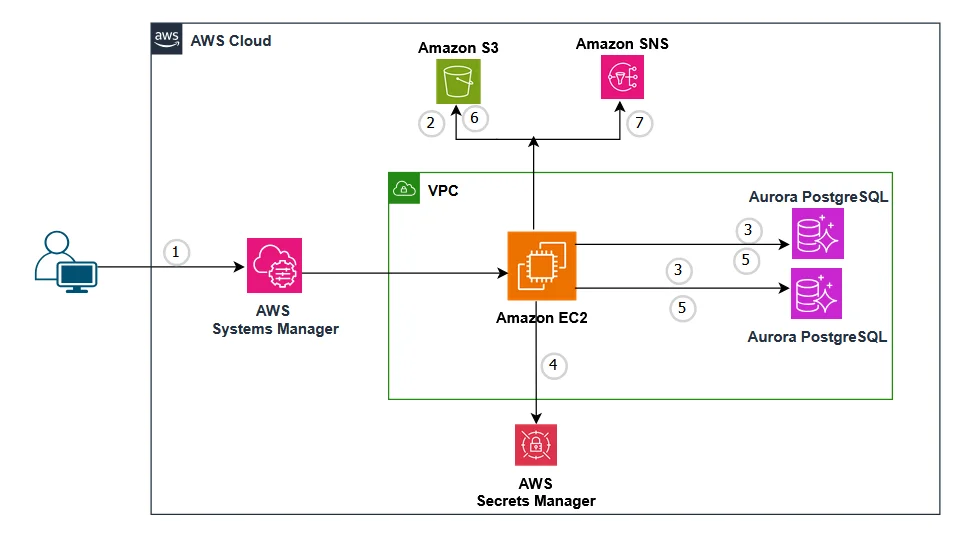
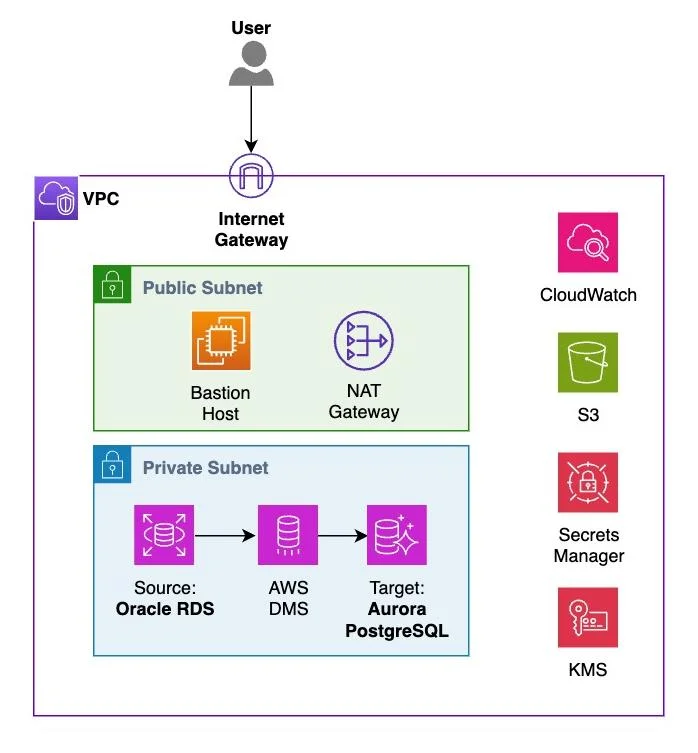
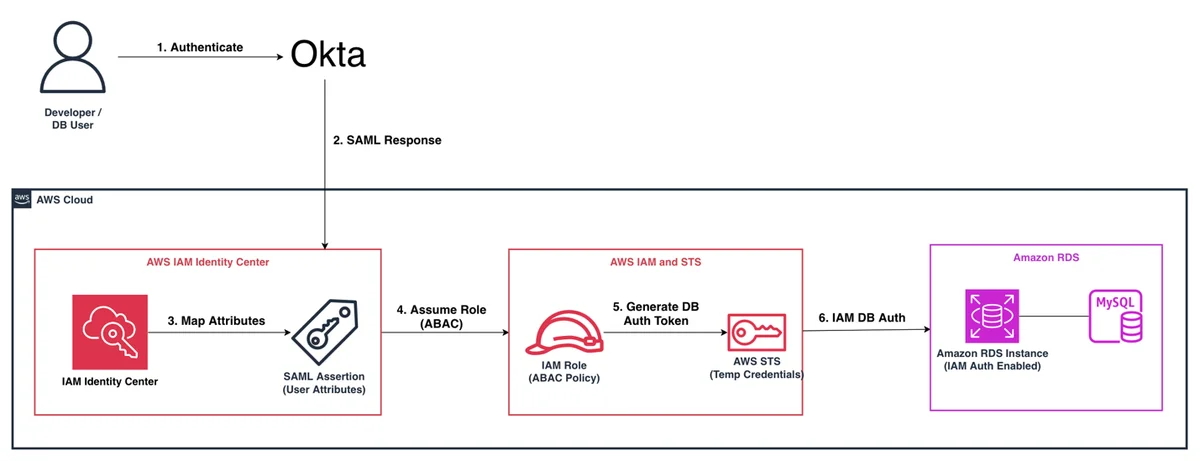
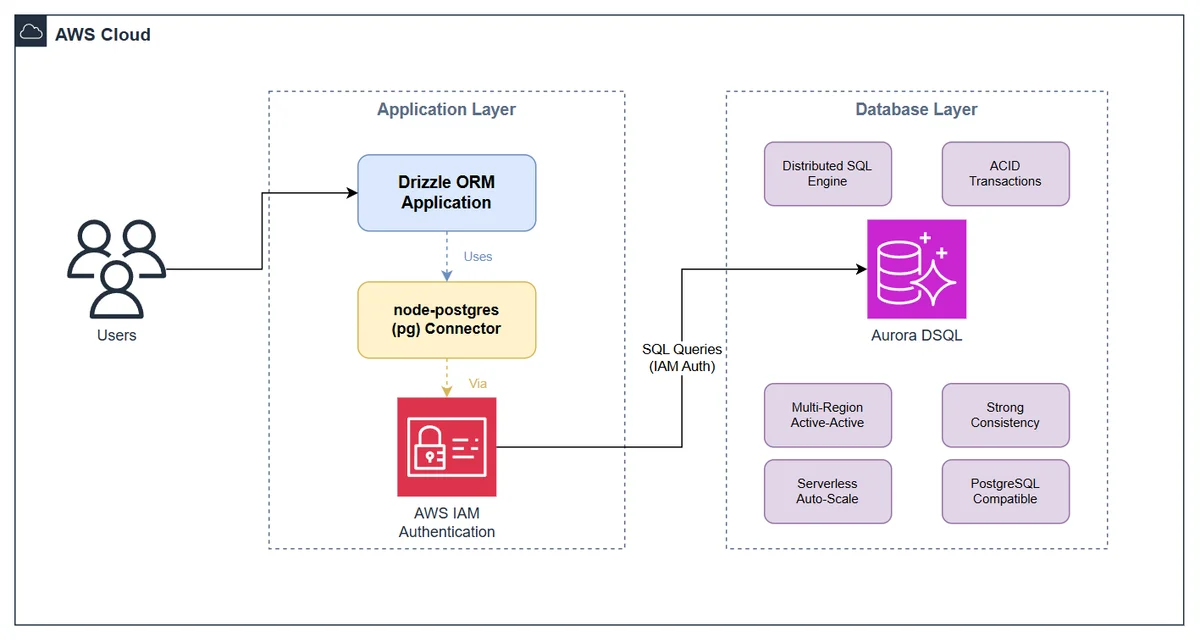
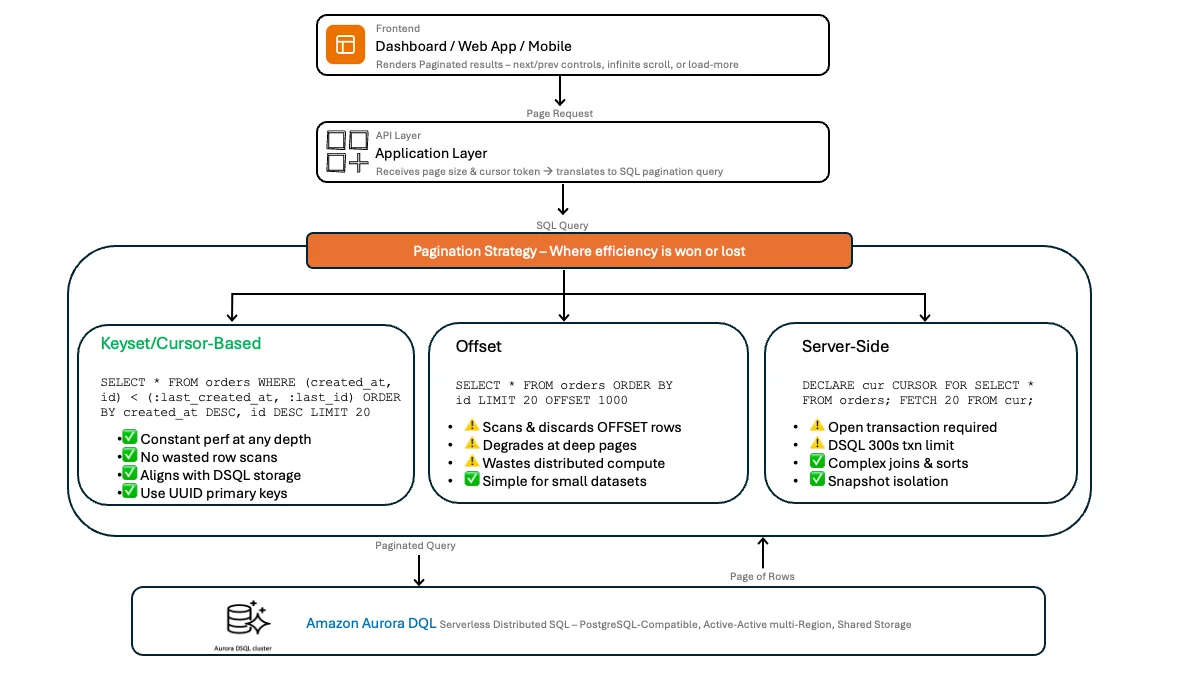
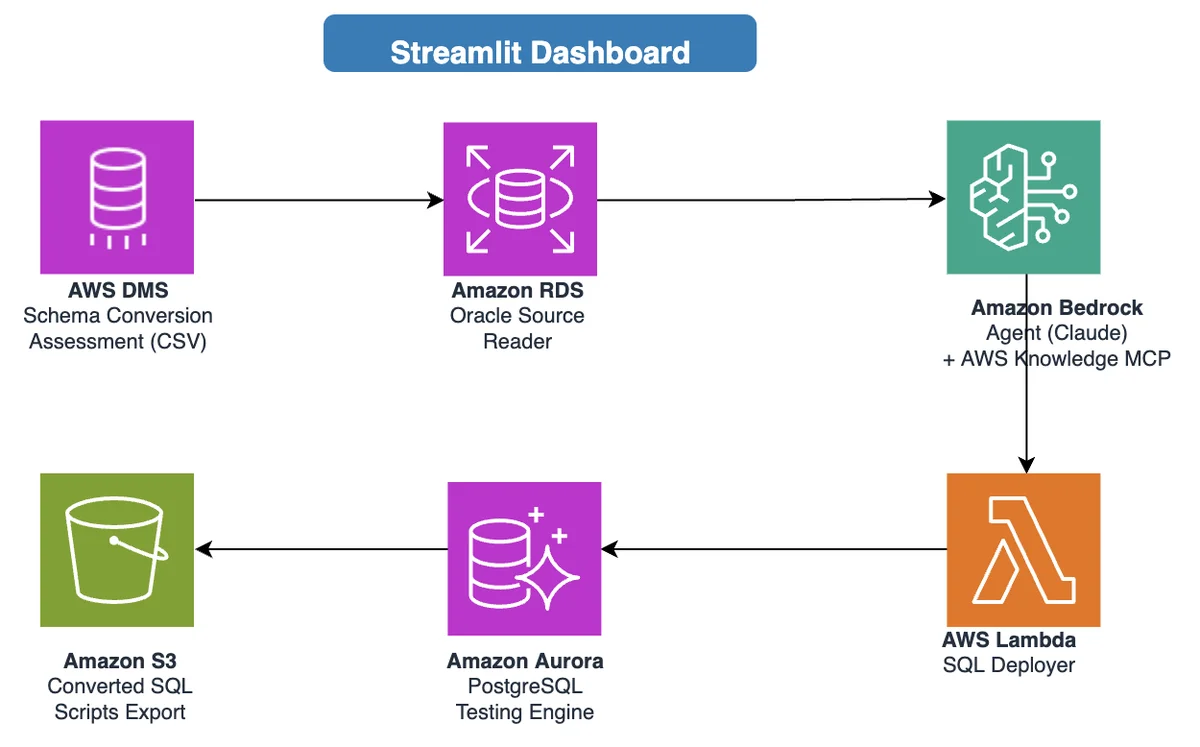
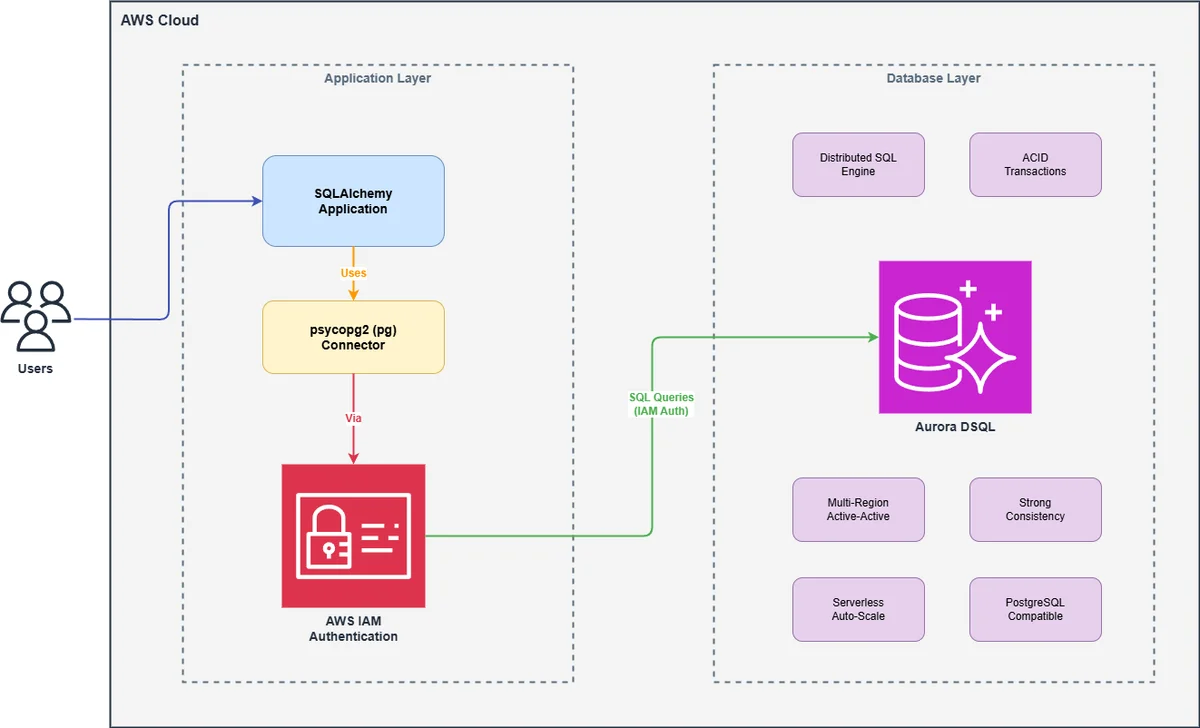
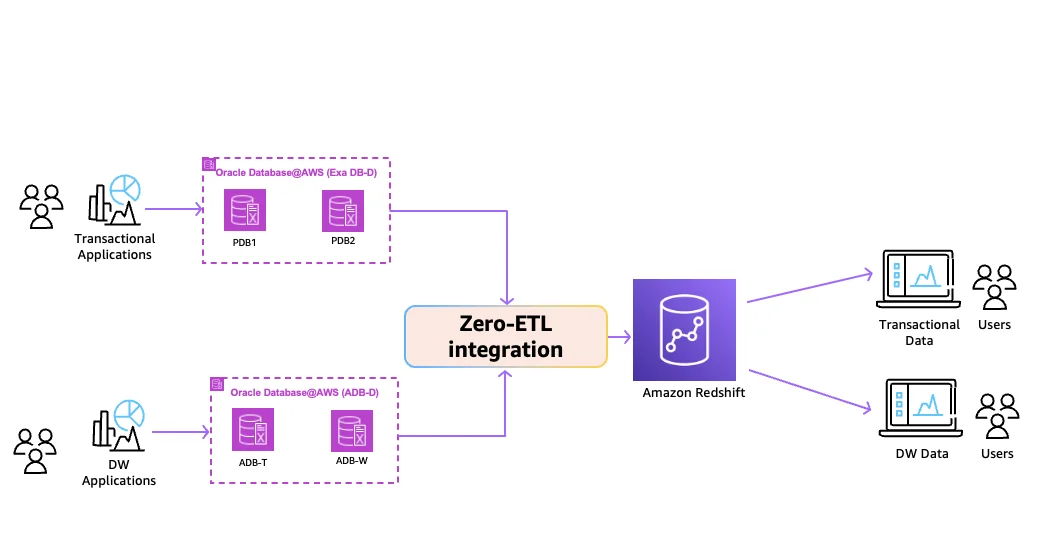
AWS Database Blog Follow
The website provides an Amazon Web Services (AWS) blog for databases, which works to assist users in efficiently using AWS database services by providing resourceful tutorials, advice, and answers to frequently asked questions.