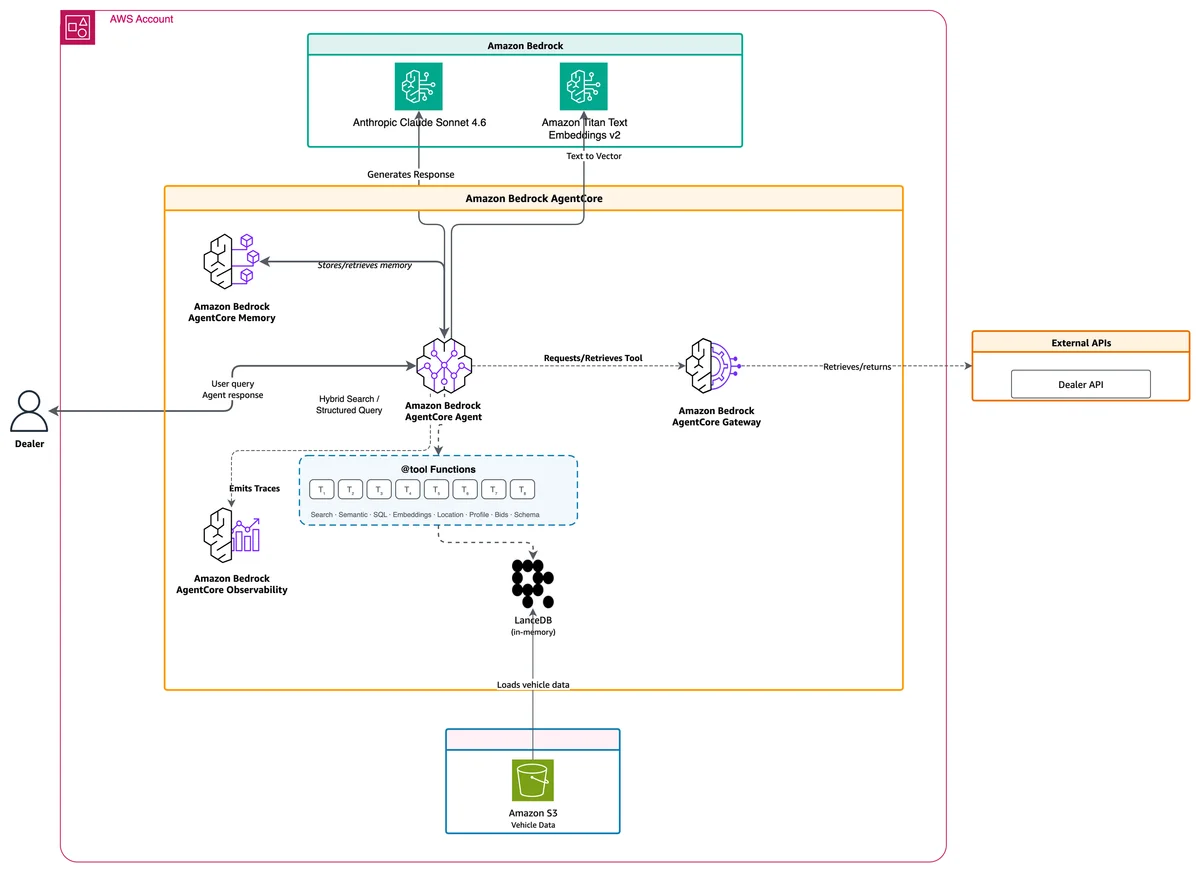
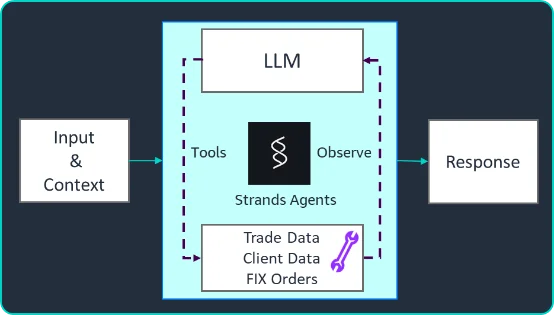
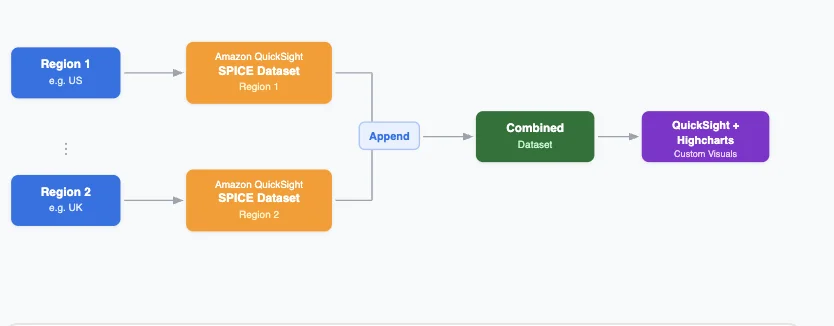
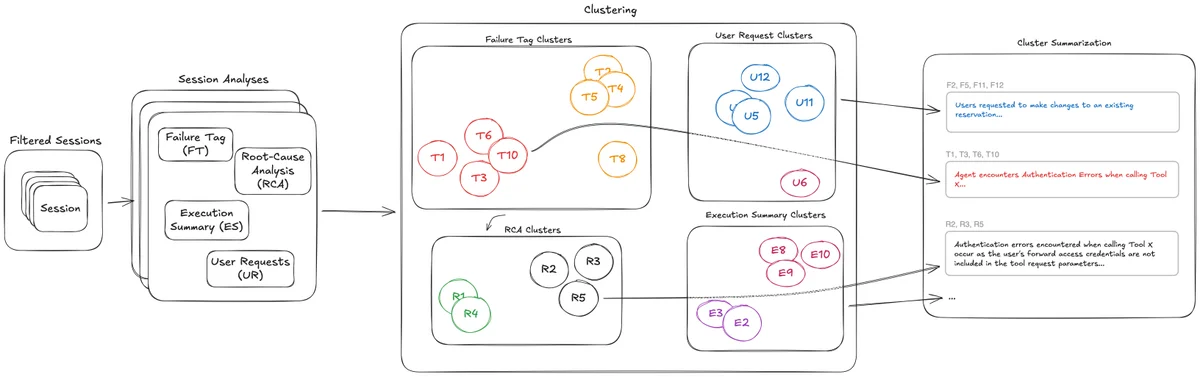
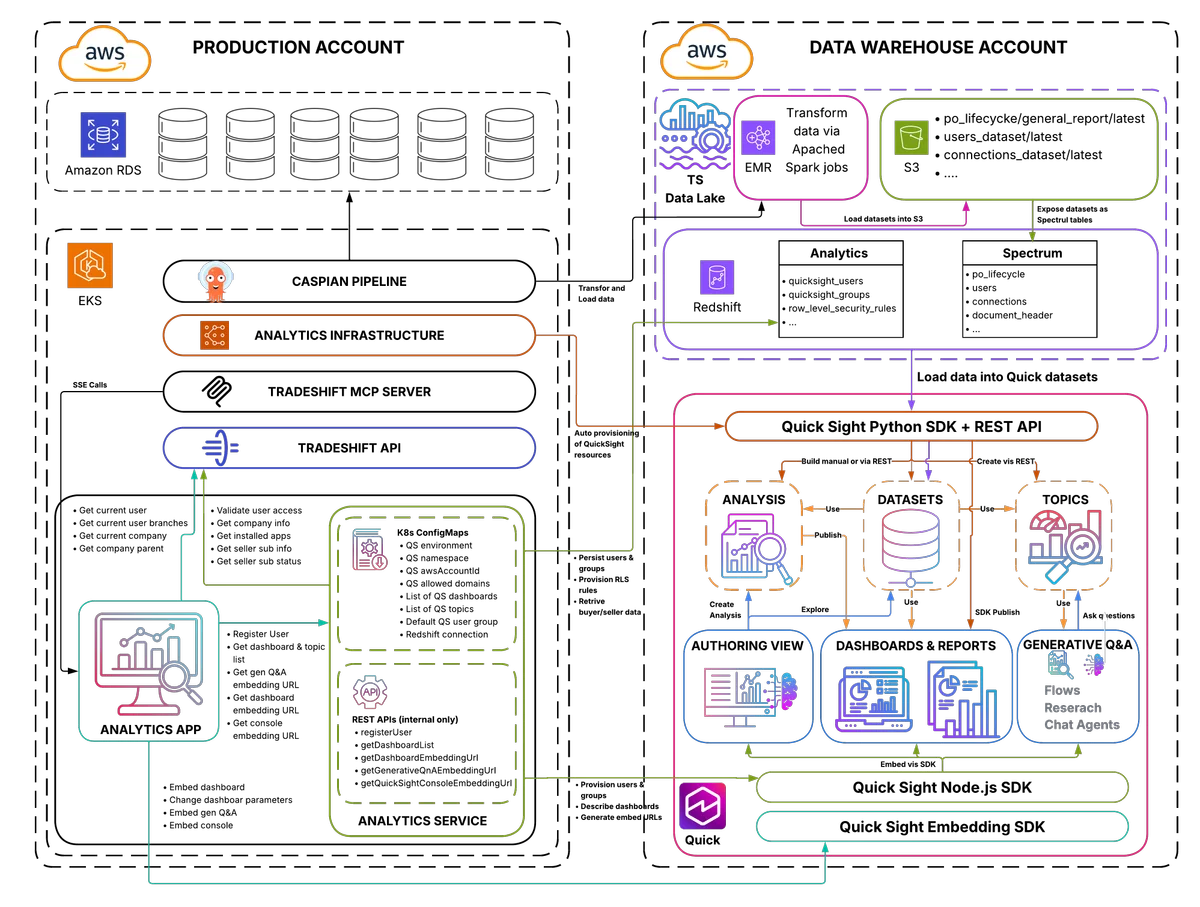
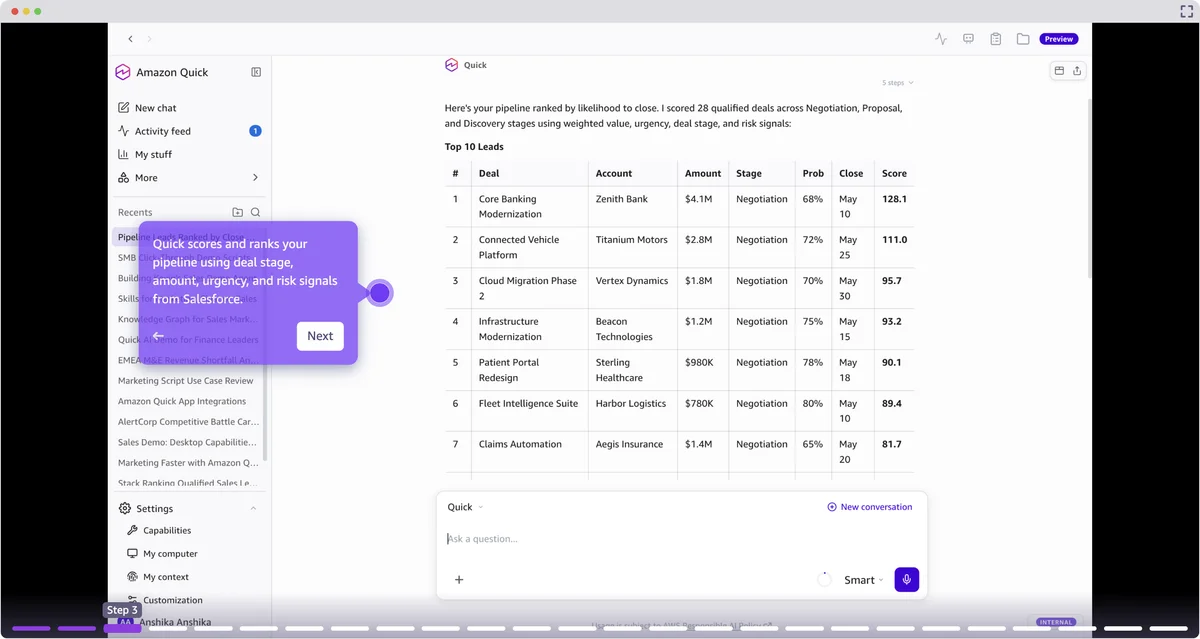
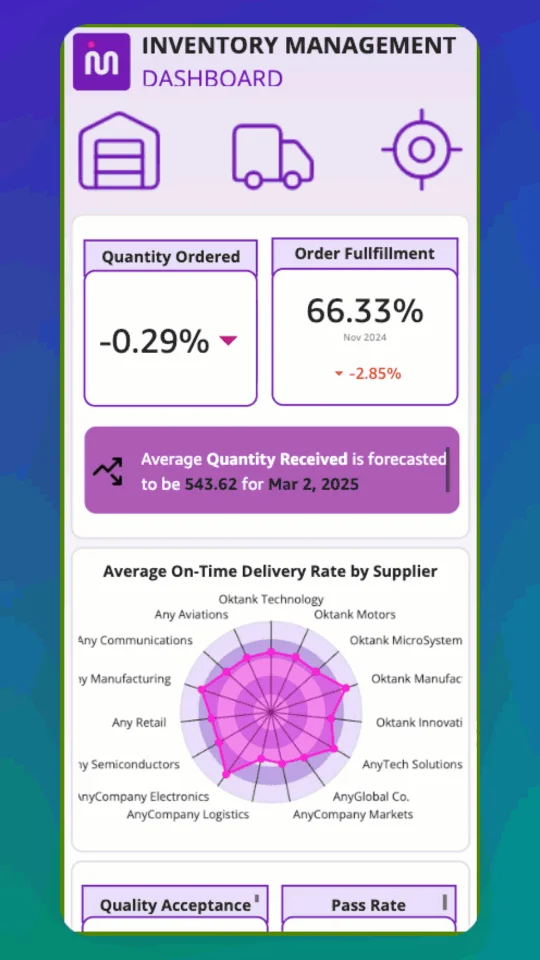
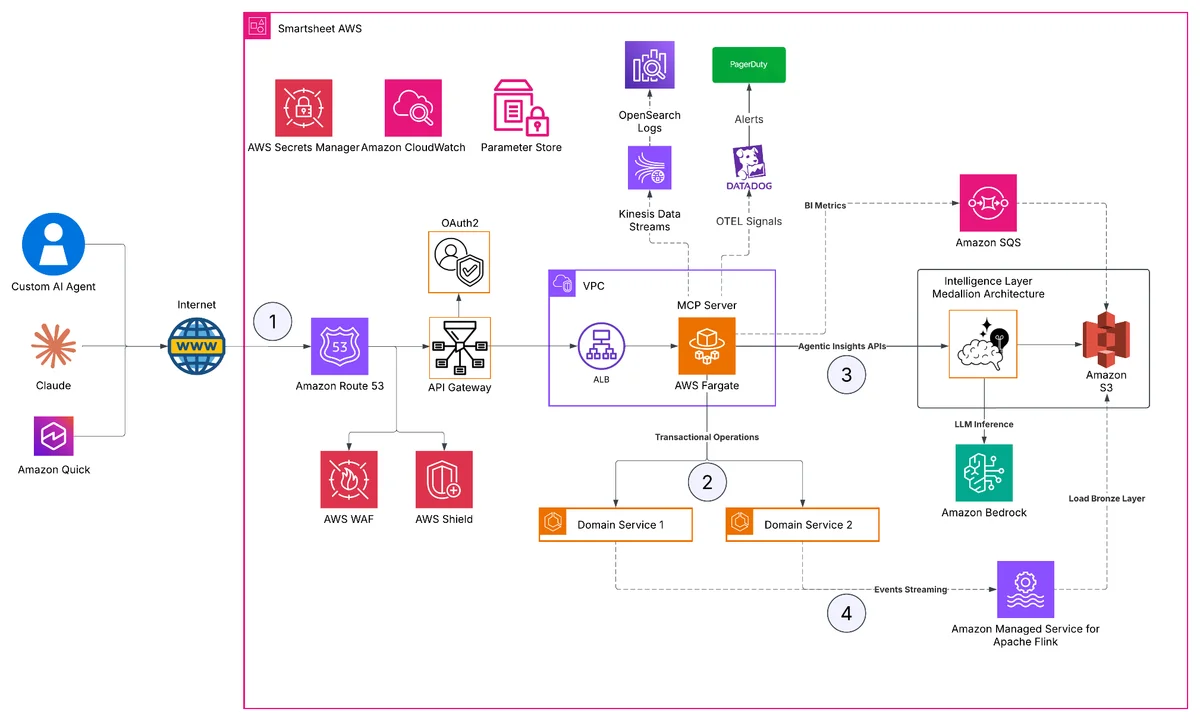
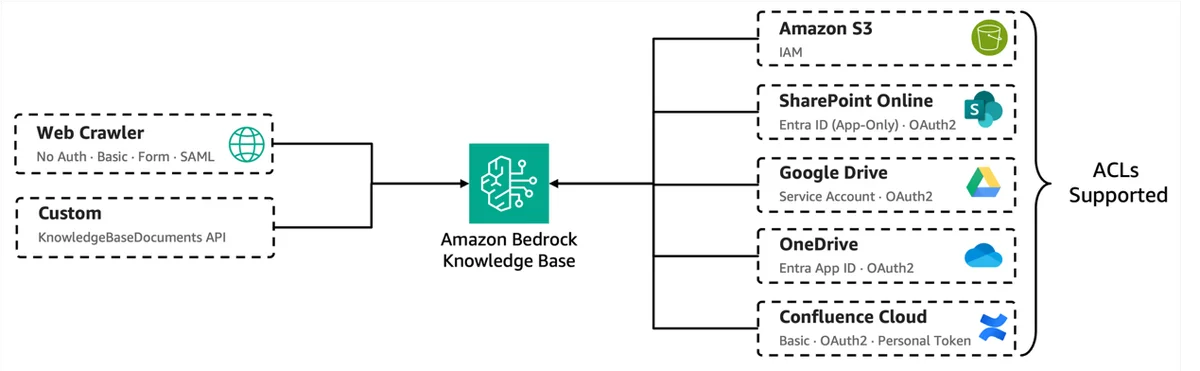
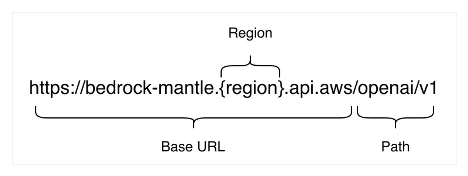
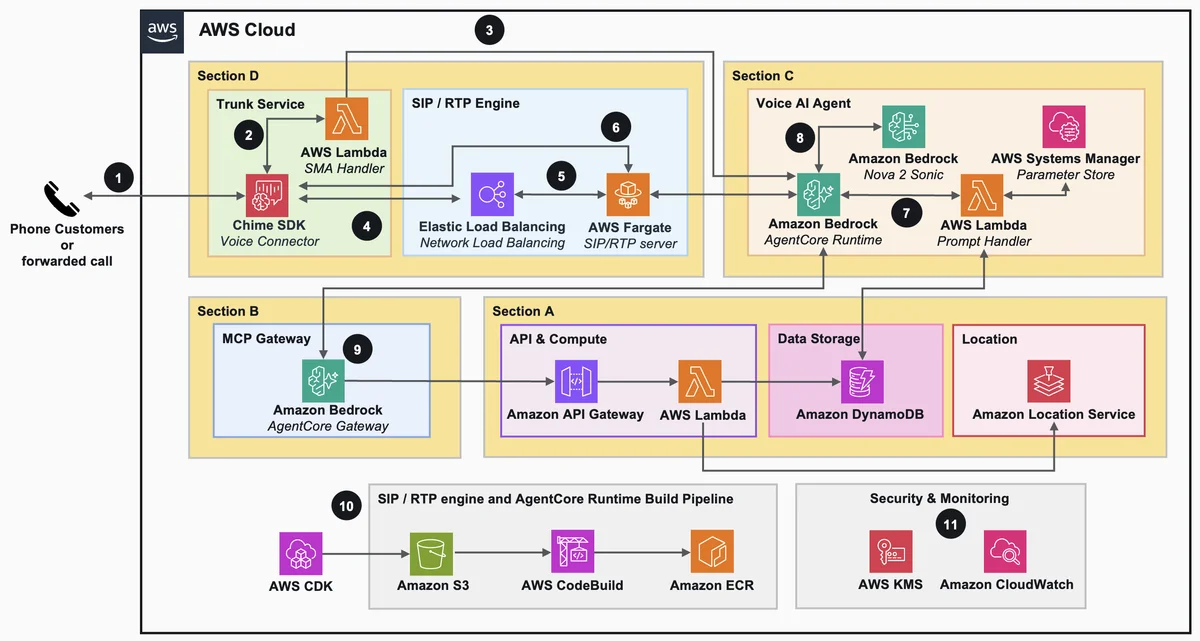
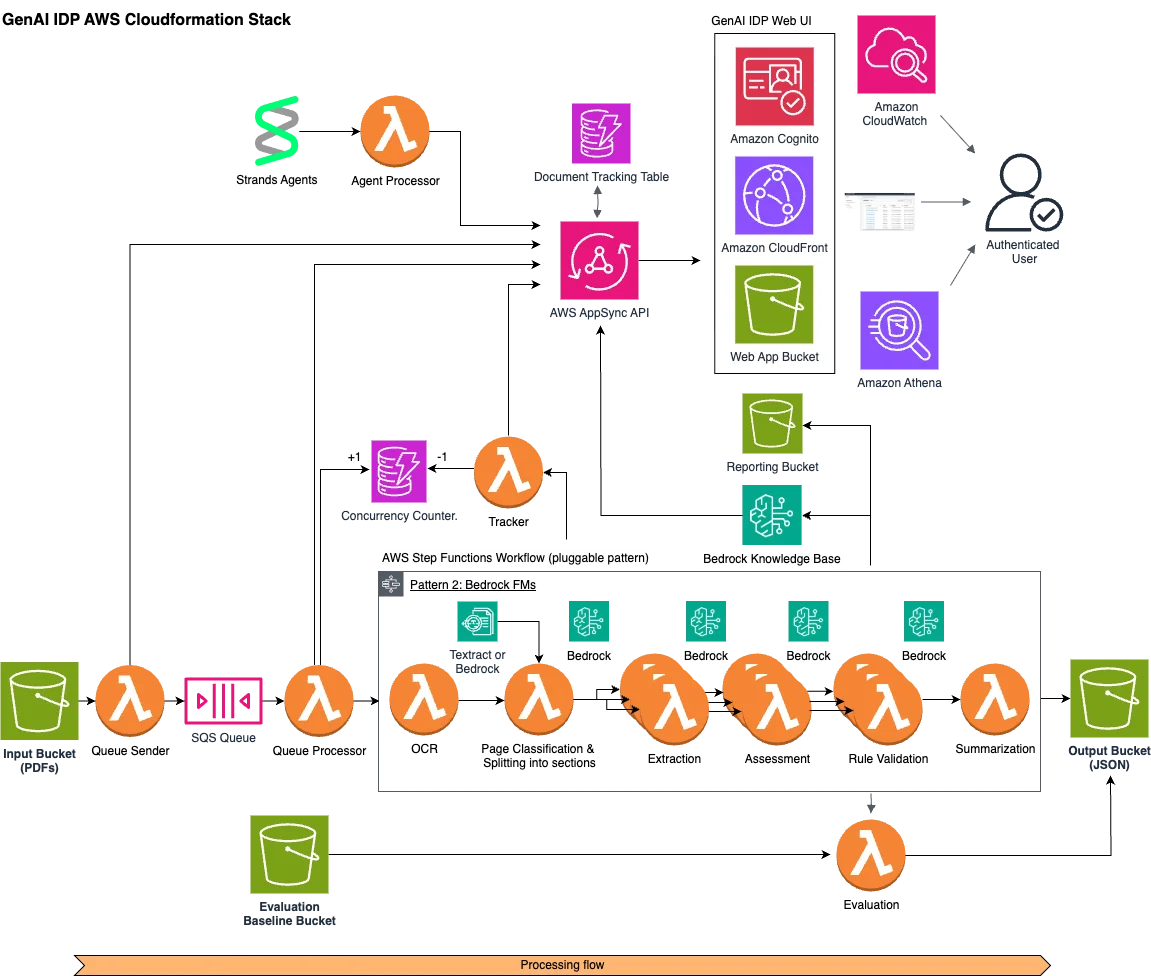
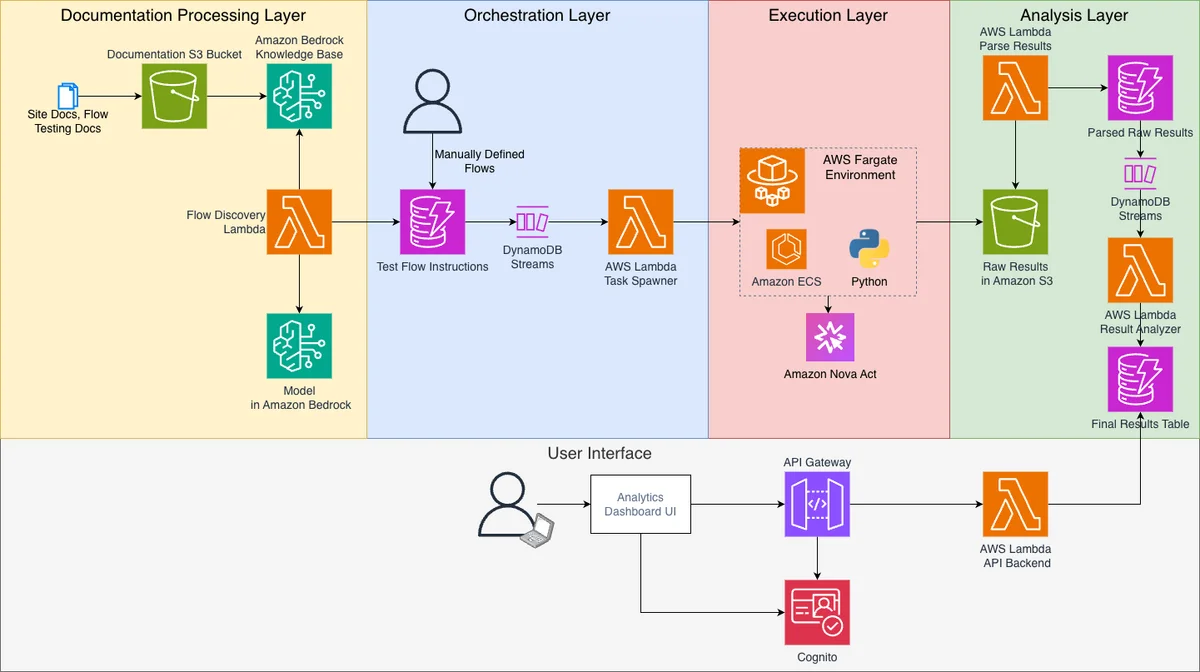
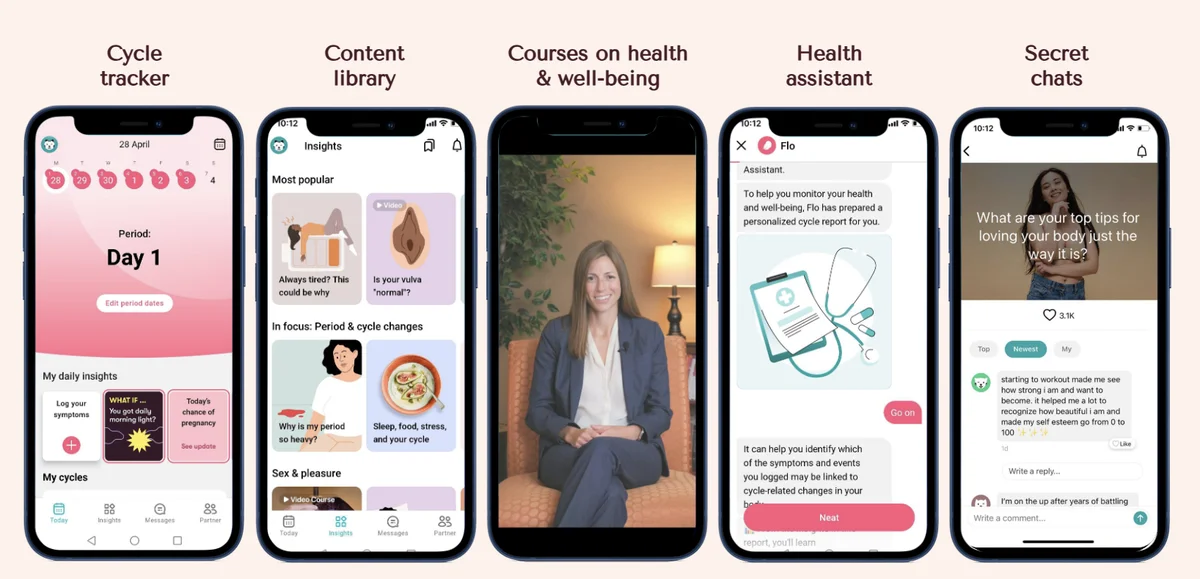
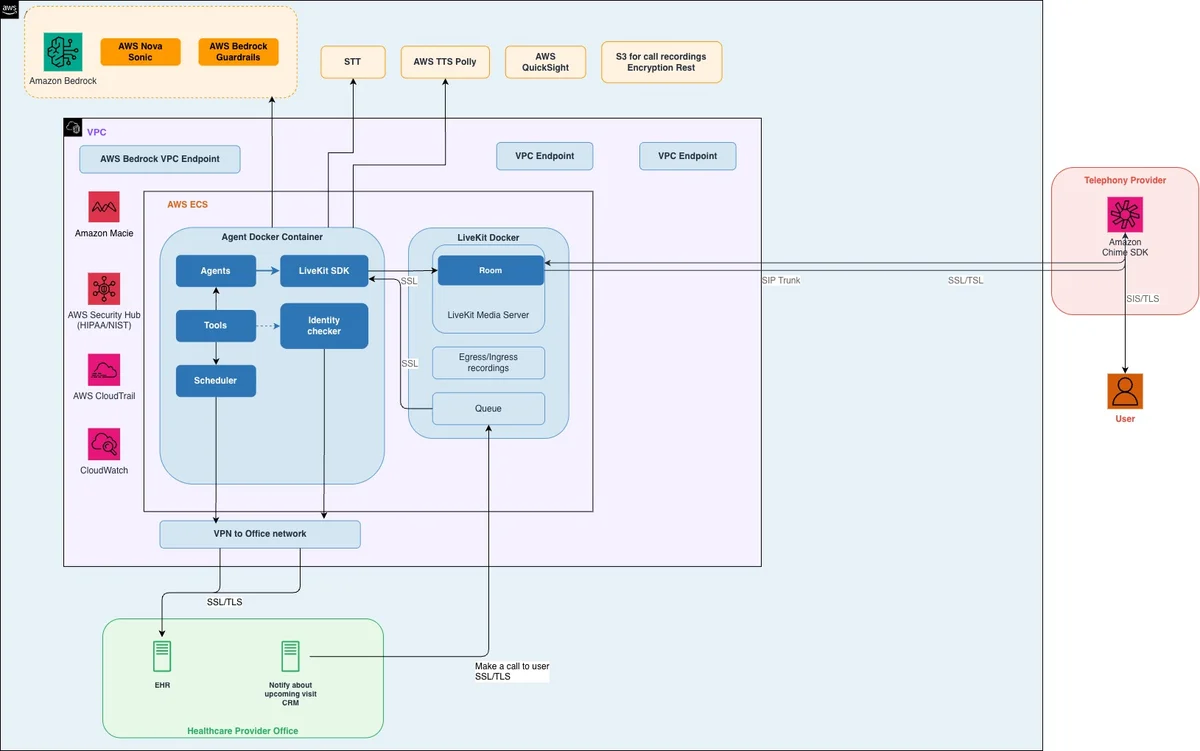
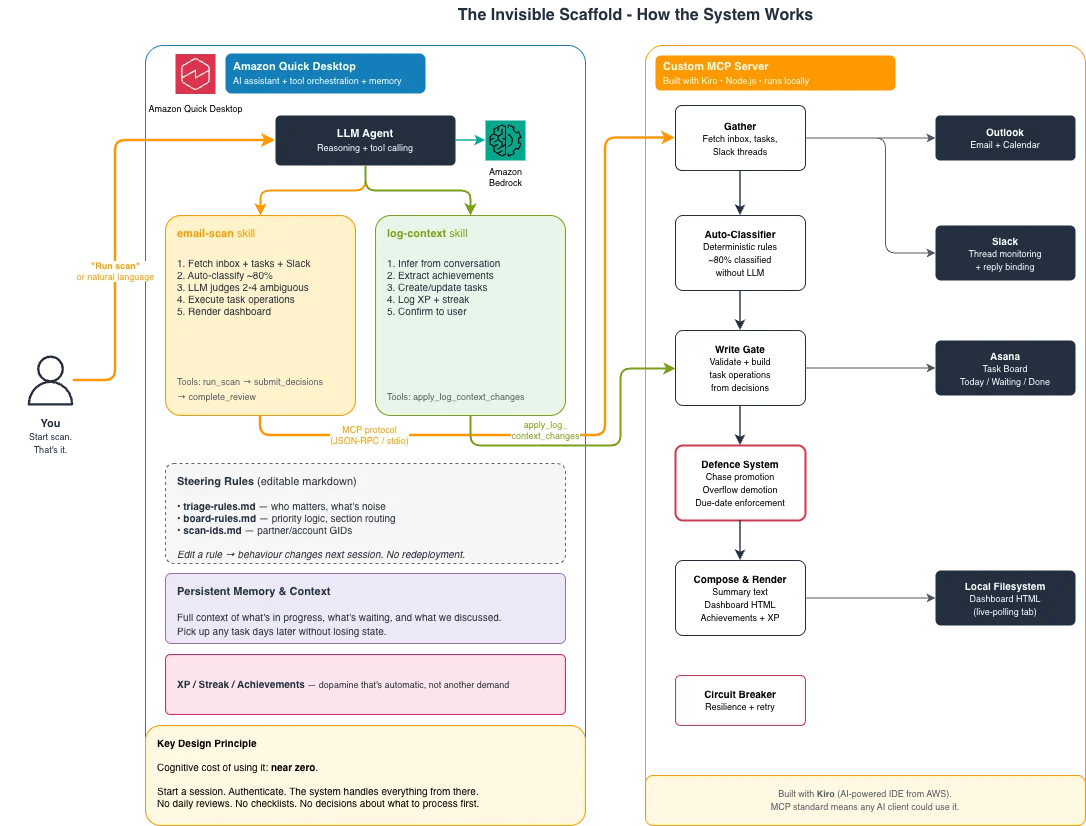
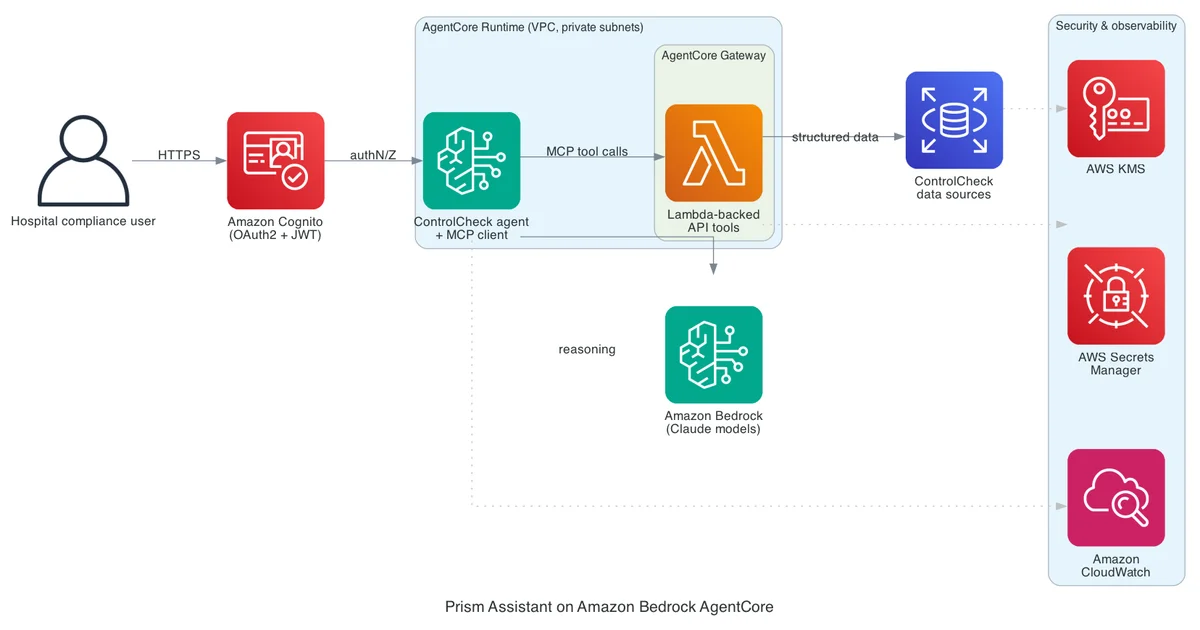
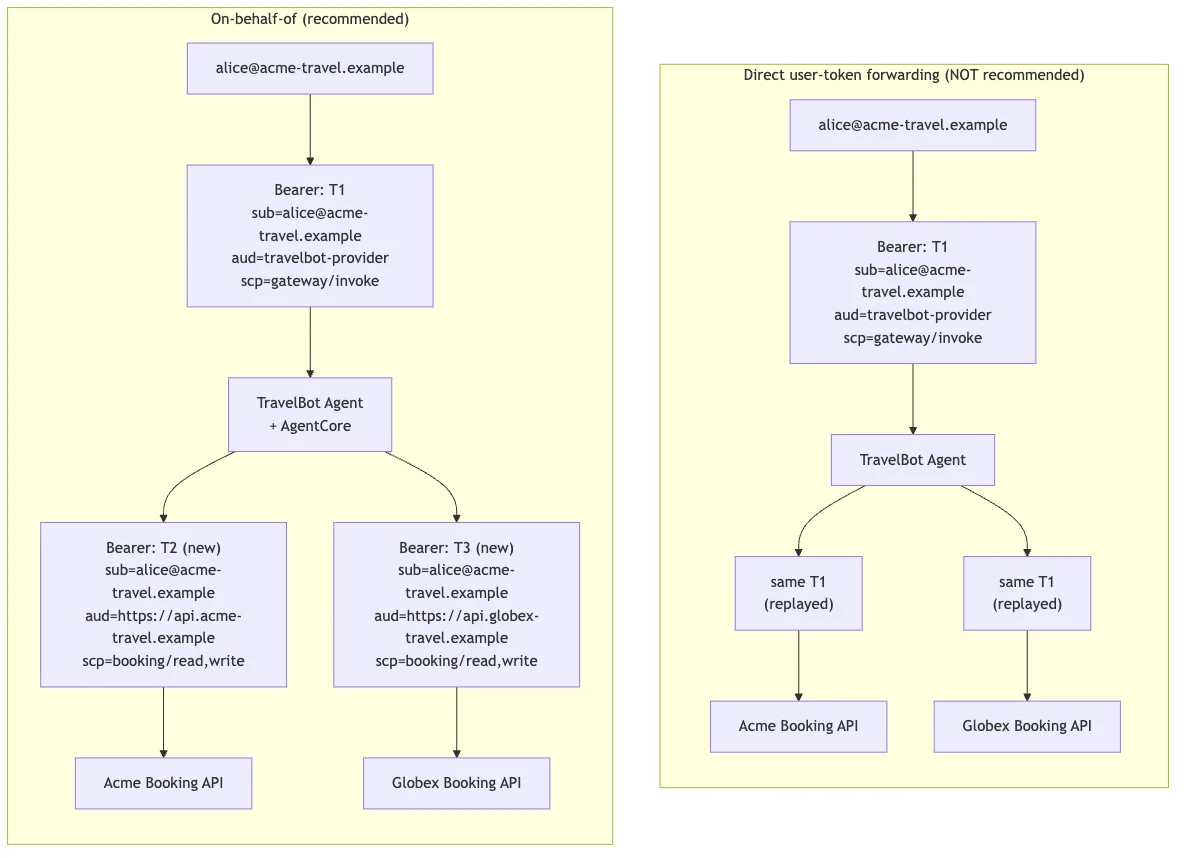
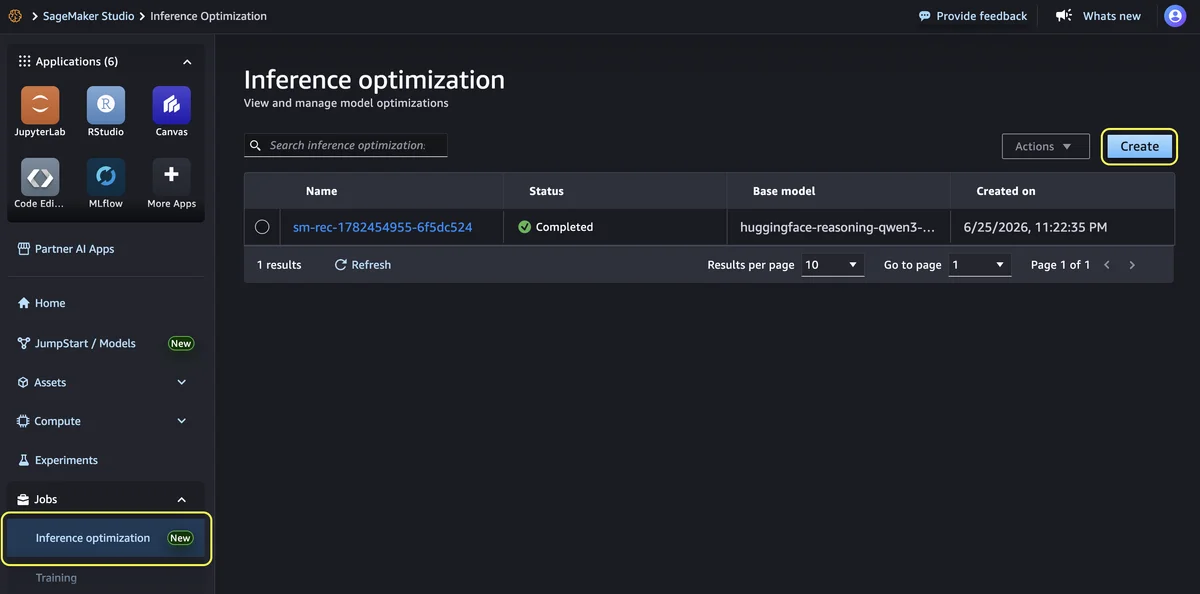
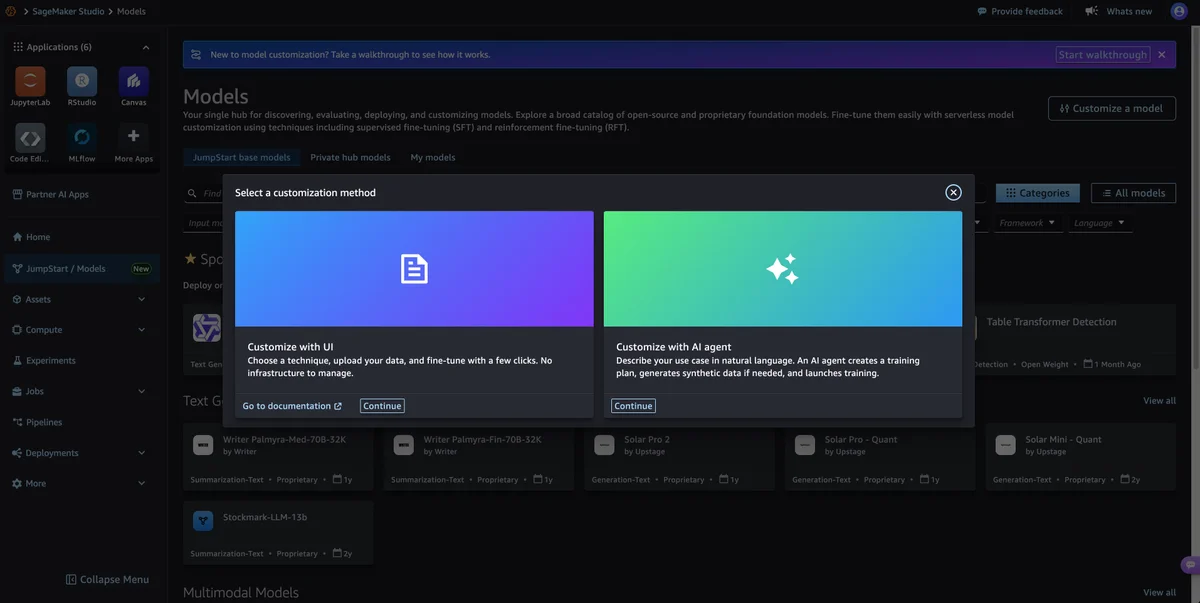
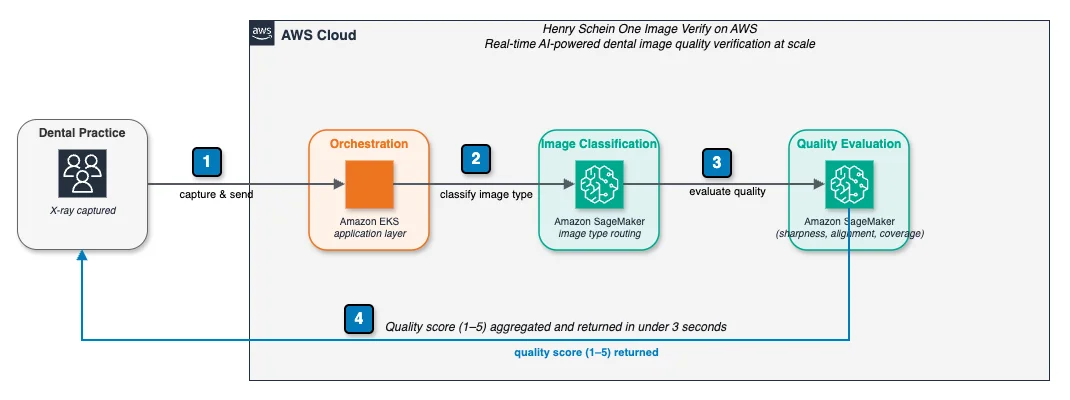
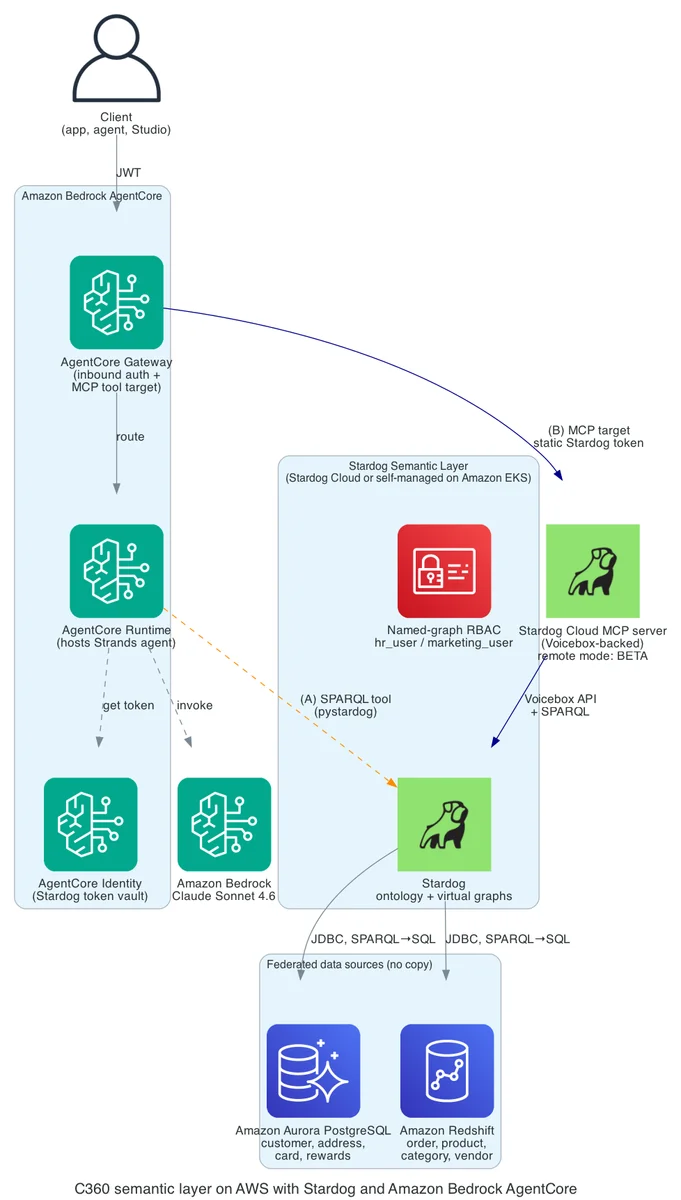
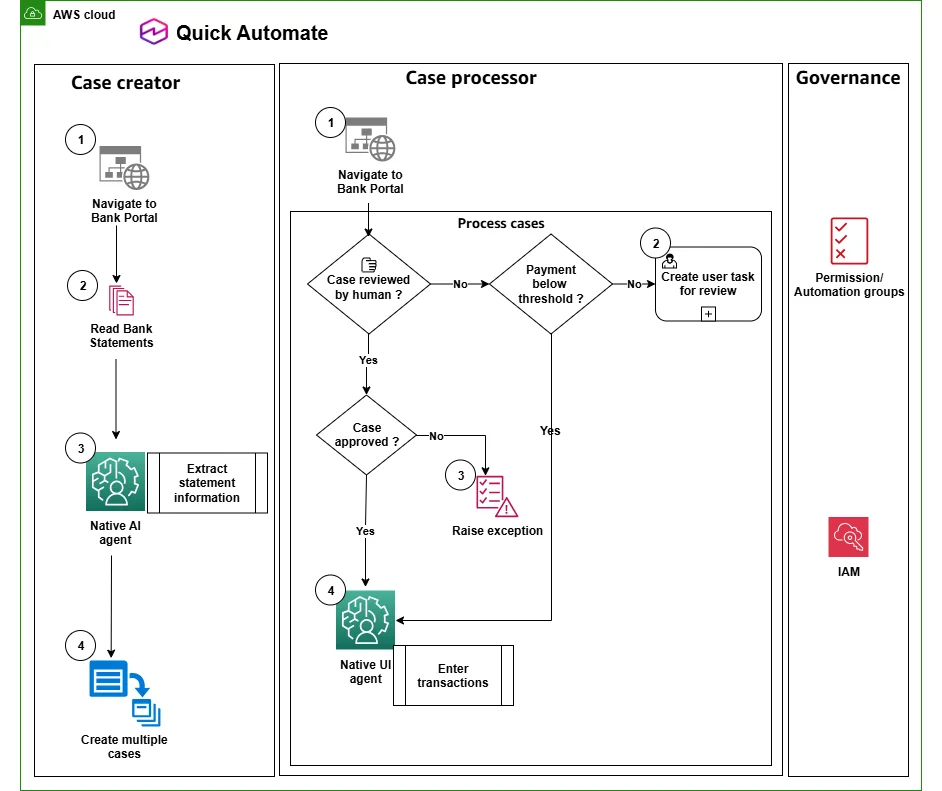
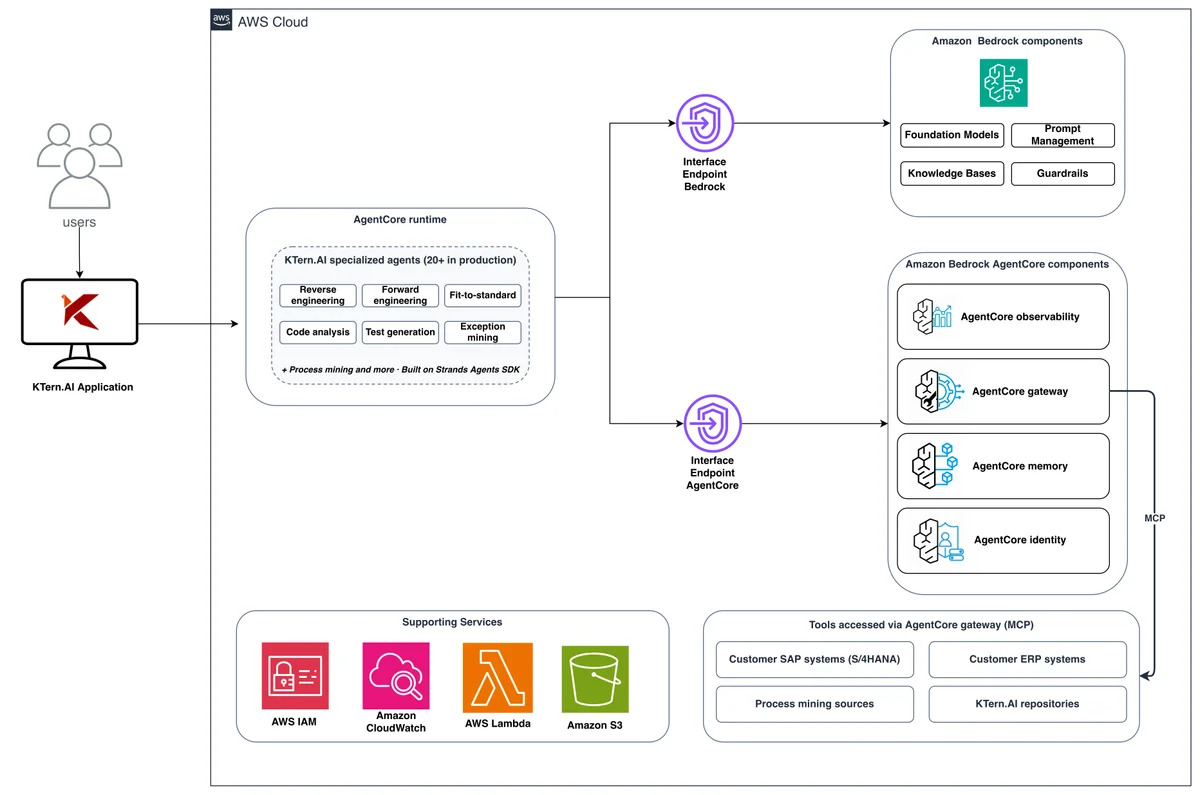
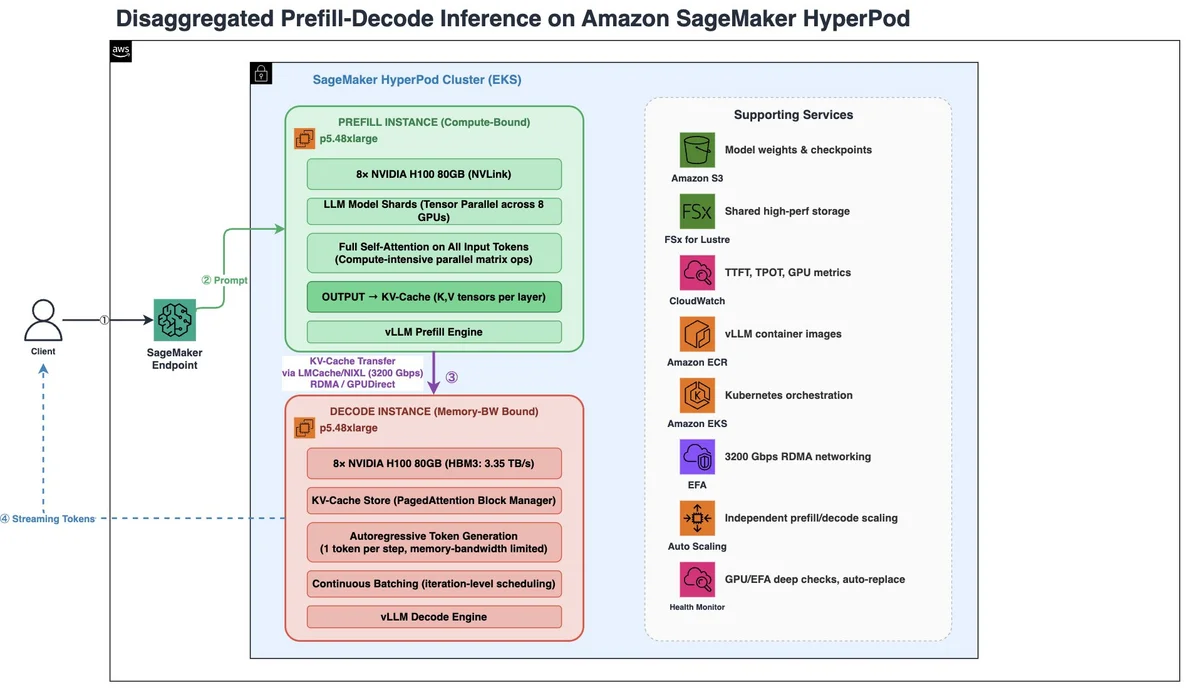
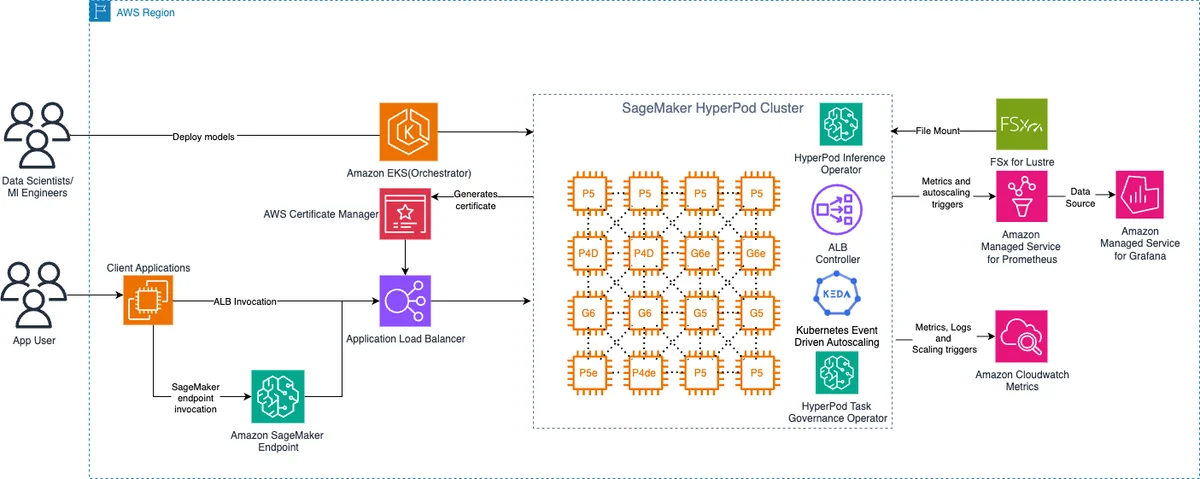
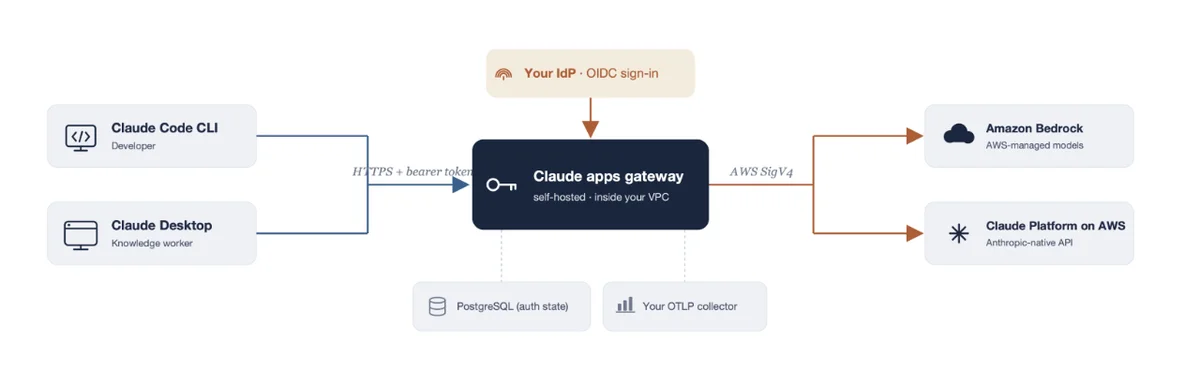
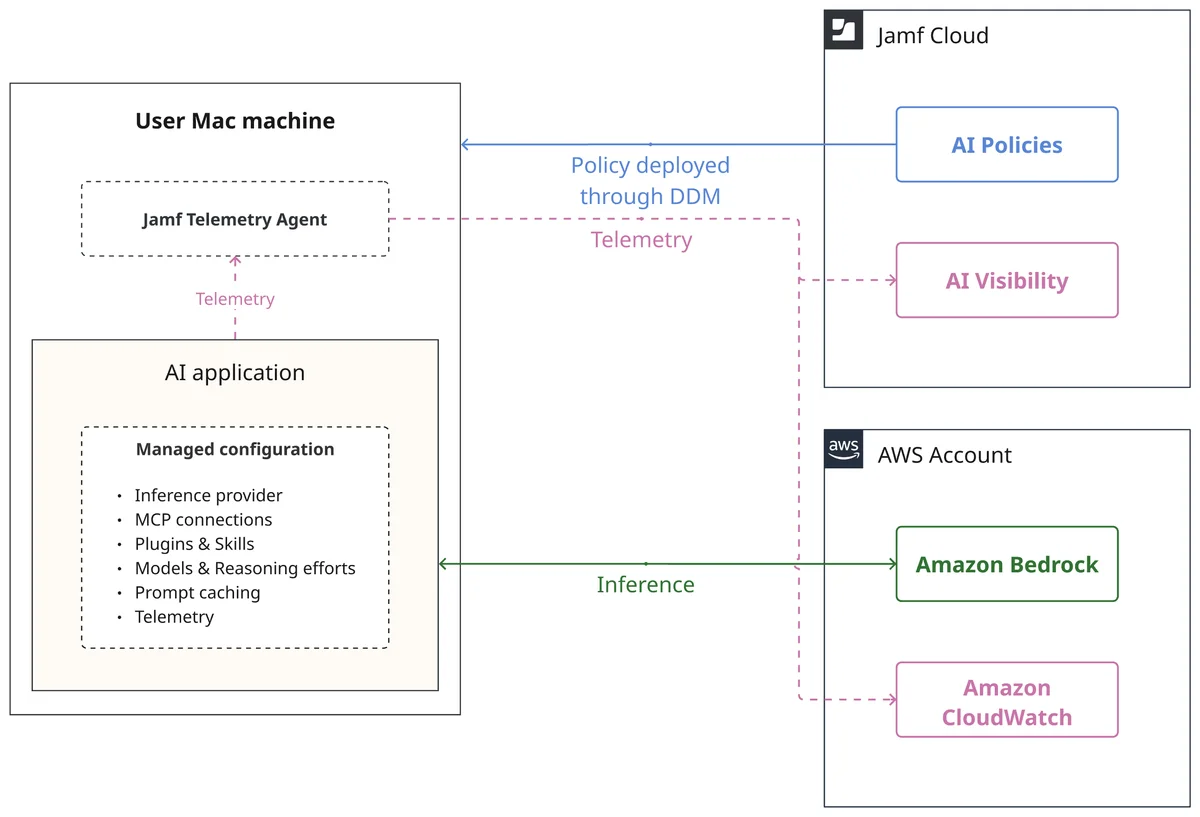
AWS Machine Learning Blog Follow
The provided URL is for the Amazon Web Services (AWS) Machine Learning Blog. This section of the AWS website showcases articles and updates about machine learning technologies, how to use them with AWS, and real-world applications and use cases of machine learning. These blogs are designed to help developers, scientists, and engineers understand how to leverage machine learning for a variety of tasks such as predictive analytics, natural language processing, and computer vision, among others. The blog section also discusses new and emerging trends within the machine learning field and how to integrate them with AWS services.