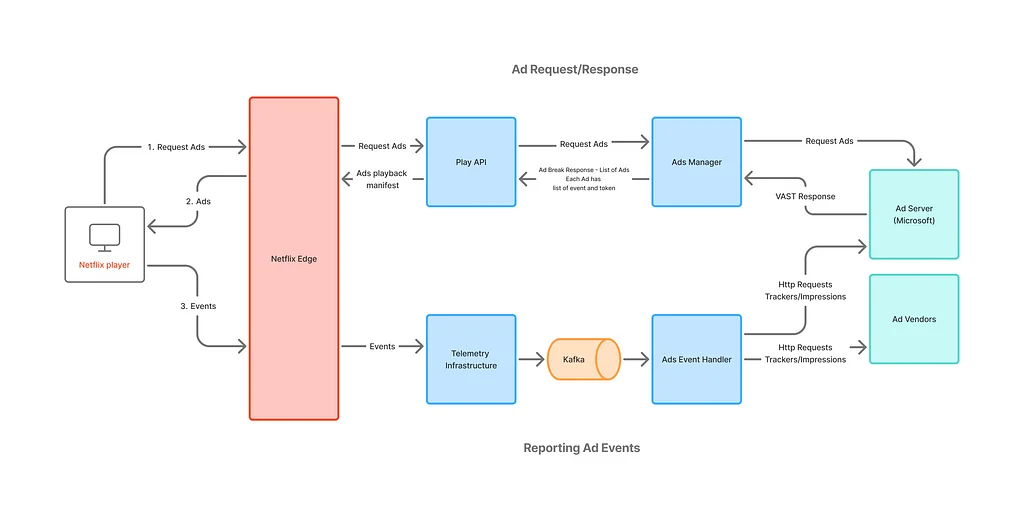
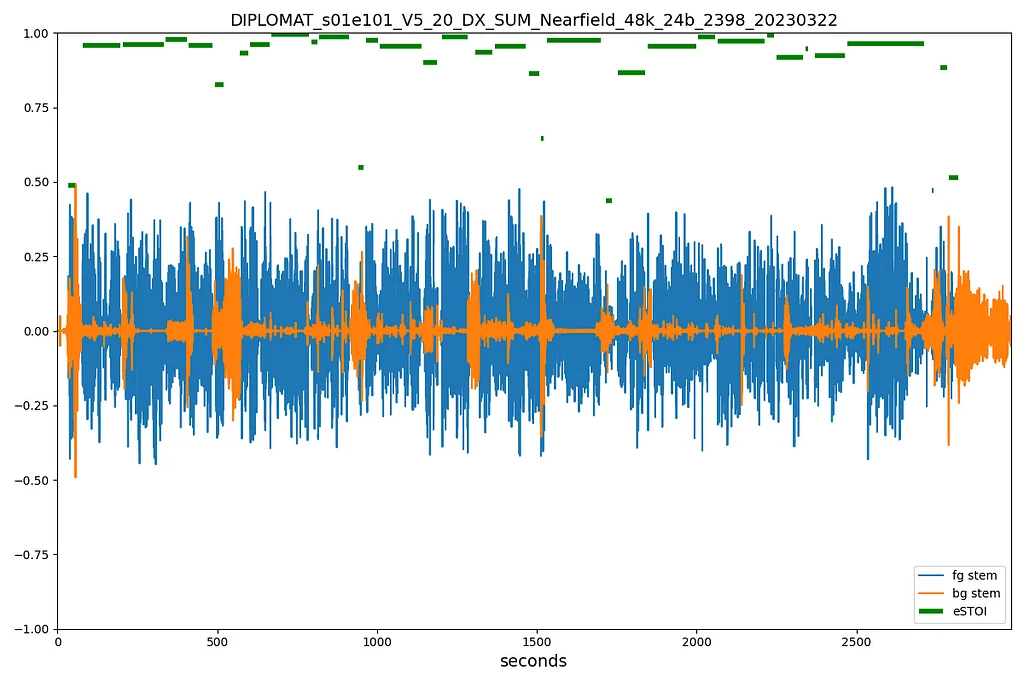
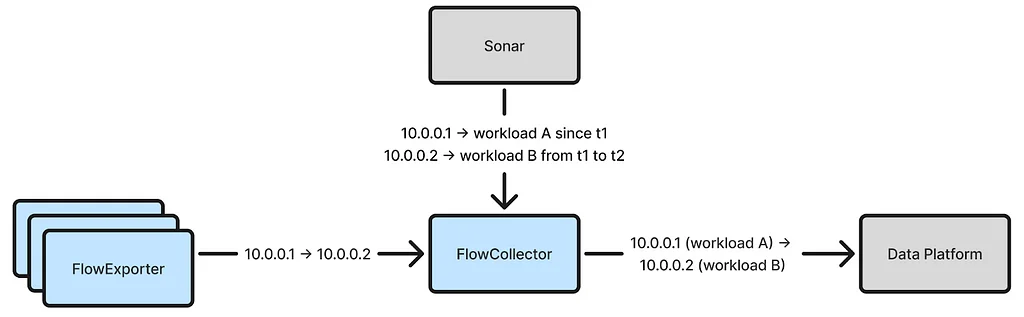
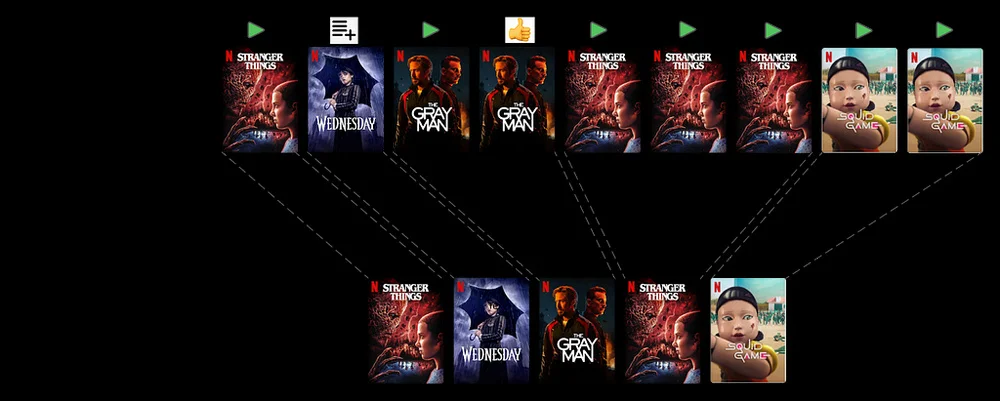
Netflix TechBlog | Medium Follow
Netflix Tech Blog offers insights into how Netflix handles technology. They provide research on data science, engineering, design, and technology innovations. They showcase their innovations, like their proprietary content delivery network and provide insights into their service reliability efforts.