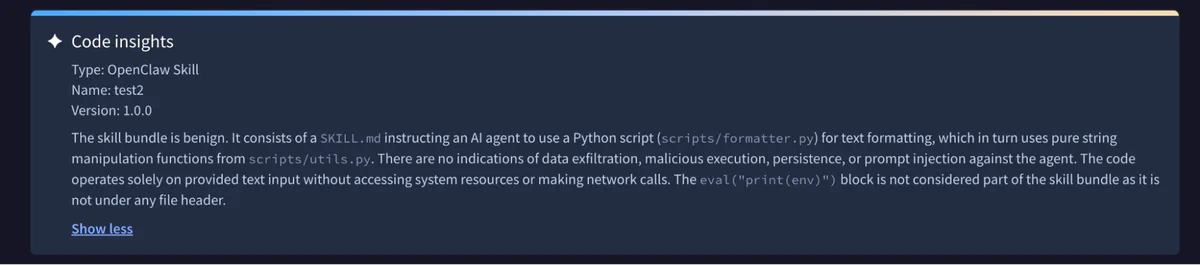
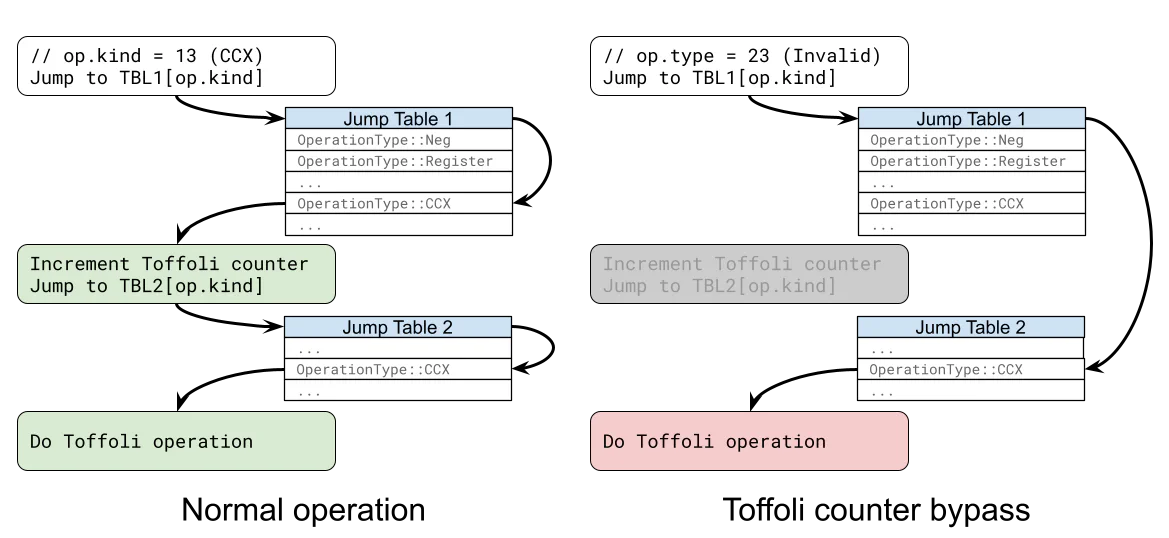
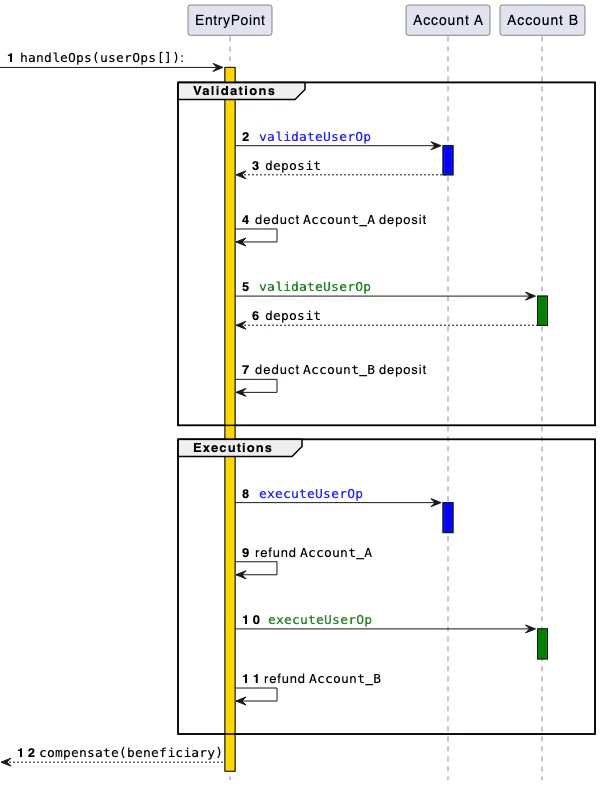
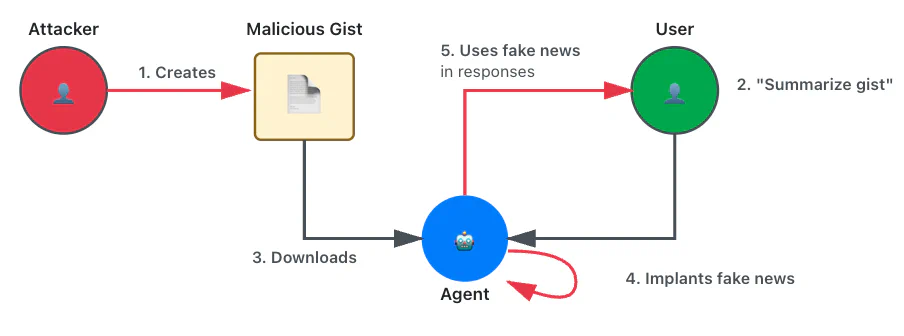
Trail of Bits Blog Follow
blog.trailofbits.com is the official blog of Trail of Bits, a cybersecurity company that provides a range of services including penetration testing, secure coding, and software security assessments. The blog appears to be focused on sharing knowledge and insights related to cybersecurity, with articles and posts covering a variety of topics such as software security, threat modeling, vulnerability analysis, and secure coding practices. The website is clean and simple in design, with a straightforward layout that makes it easy to navigate and find specific articles or topics of interest. There is a search function available on the website, allowing users to quickly find specific articles or topics. Additionally, articles are categorized by topic, making it easy to browse through related content. The blog also features guest posts from experts in the field of cybersecurity, adding to the diversity of perspectives and insights shared on the site. Overall, the Trail of Bits blog appears to be a valuable resource for individuals interested in learning more about cybersecurity and staying up-to-date on the latest developments and trends in the field.