RSS Google AI Blog
Follow
Securing private data at scale with differentially private partition selection
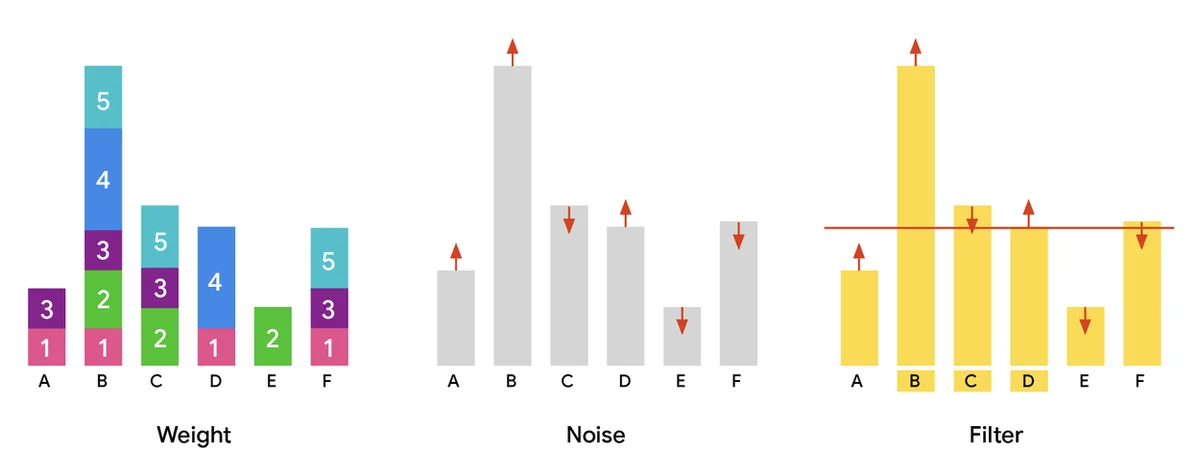
Large user-based datasets are vital for AI advancement, improving services and personalization. Sharing these datasets accelerates research but poses privacy risks. Differentially private (DP) partition selection identifies safe, common data subsets by adding noise to protect individual contributions. This is crucial for tasks like vocabulary extraction and private data analysis. Processing massive datasets requires parallel algorithms, not just for speed but for handling immense scales. Our publication, “Scalable Private Partition Selection via Adaptive Weighting,” introduces an efficient parallel algorithm for DP partition selection. This algorithm scales to hundreds of billions of items, significantly exceeding previous capabilities. The goal is to maximize selected items while preserving user privacy, prioritizing popular data. The standard approach involves weighting, adding noise, and filtering items based on a threshold. Our novel adaptive weighting algorithm, MAD, reallocates "excess weight" from popular items to those just below the privacy threshold. This improves utility by including more items without compromising privacy or scalability. Experiments show our two-iteration MAD algorithm achieves state-of-the-art results, outputting more items than other methods with the same privacy guarantees. We are open-sourcing our algorithm to foster community innovation.