RSS Google AI Blog
Follow
Simulating large systems with Regression Language Models
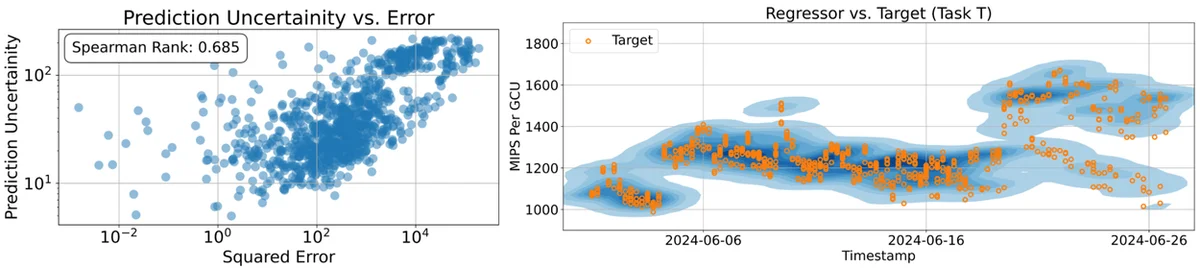
Large Language Models (LLMs) are enhanced by learning from human preferences to generate helpful text. A novel approach extends this by using operational data to train reward models for predicting performance metrics. Traditional regression struggles with complex, unstructured data, requiring laborious feature engineering. The paper introduces Regression Language Models (RLMs) that perform text-to-text regression, directly processing text inputs to output numerical predictions as strings. This method avoids feature engineering and allows for few-shot adaptation to new tasks. RLMs can capture probability distributions of outcomes and quantify prediction uncertainty. This approach was applied to predict resource efficiency in Google's large-scale compute infrastructure, Borg. The RLM effectively predicted Millions of Instructions Per Second per Google Compute Unit (MIPS per GCU). This new paradigm offers a scalable and efficient way to predict numerical outcomes from raw text, enabling universal system simulators and advanced reward mechanisms.