RSS Google AI Blog
Follow
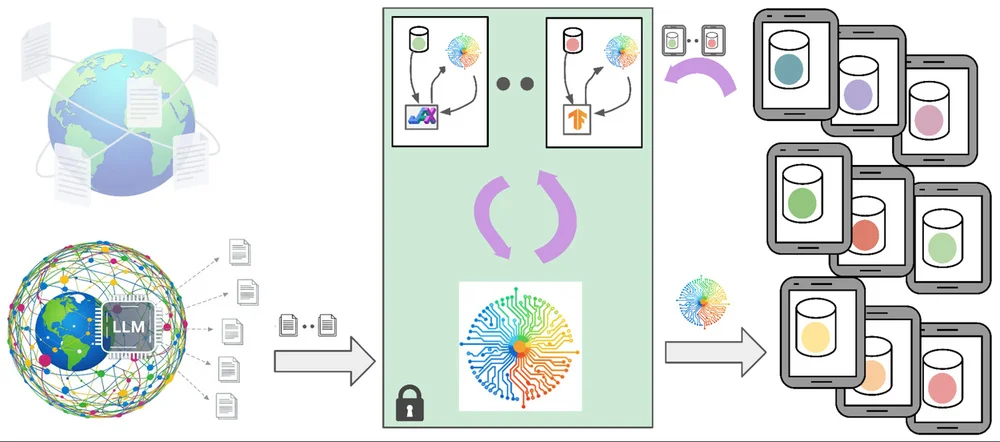
Synthetic and federated: Privacy-preserving domain adaptation with LLMs for mobile applications
Google's Gboard utilizes large and small language models (LLMs and LMs) for features like typing prediction and proofreading. Training these models requires high-quality data, but using user data raises privacy concerns. To address this, Gboard employs synthetic data generated by LLMs trained on public data, mimicking user interaction without revealing private information. This synthetic data pre-trains models, improving performance before further training with privacy-preserving techniques like federated learning and differential privacy. This approach minimizes privacy risks while significantly enhancing model accuracy, resulting in improvements to Gboard's features. The process involves prompting LLMs to generate realistic mobile typing data, which is then used to pre-train smaller models. A "buttress module," a small model trained on user data with differential privacy, further refines the synthetic data for better domain adaptation. This combined approach improves both small and large models, enhancing Gboard's functionality while upholding user privacy. The system incorporates multiple privacy safeguards, including data minimization and anonymization. Ongoing research focuses on improving the generation and application of privacy-preserving synthetic data for even better model performance and enhanced user experience.