RSS Google AI Blog
Follow
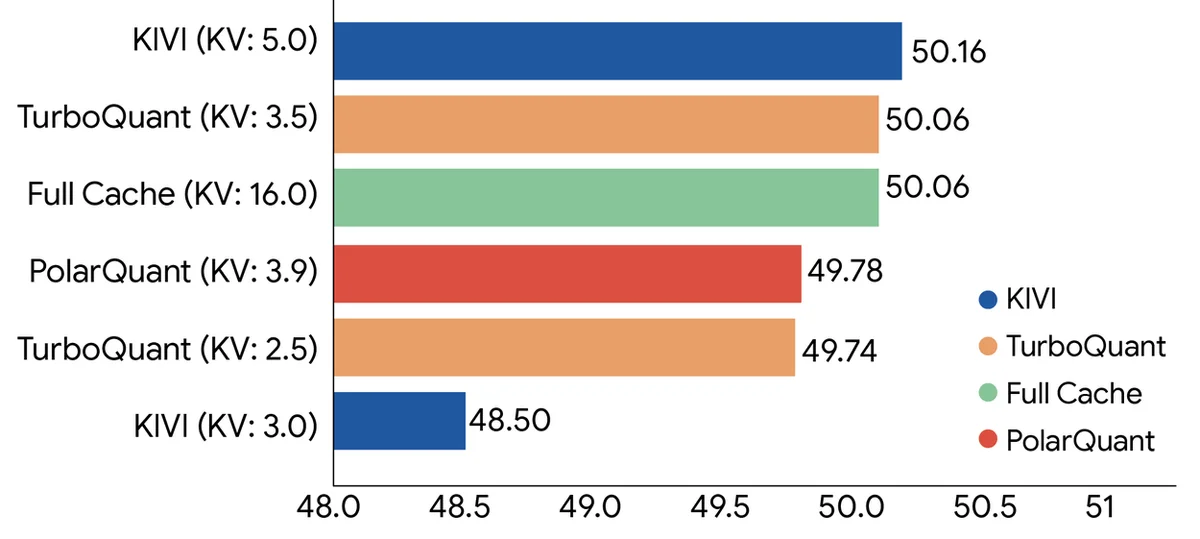
TurboQuant: Redefining AI efficiency with extreme compression
AI models use vectors to represent and process information, with high-dimensional vectors efficiently capturing complex data. These high-dimensional vectors consume excessive memory, creating bottlenecks in key-value caches, which are a critical component for fast AI processing. TurboQuant, a new compression algorithm, tackles this memory issue in vector quantization, improving speed and reducing memory usage. TurboQuant uses PolarQuant and Quantized Johnson-Lindenstrauss (QJL) to compress vectors with minimal accuracy loss. QJL achieves zero memory overhead by reducing vectors to single sign bits preserving important relationships. PolarQuant uses a polar coordinate system for compression, eliminating memory overhead by transforming cartesian coordinates into angles and radii. Experiments demonstrate TurboQuant's superior performance in terms of recall and dot product distortion. TurboQuant achieves significant speedups in attention logit computation and high-dimensional vector search. These methods improve vector search, making semantic search at scale more efficient with minimal memory usage. Research also demonstrates TurboQuant's robust and efficient performance and its impact on the future of AI.