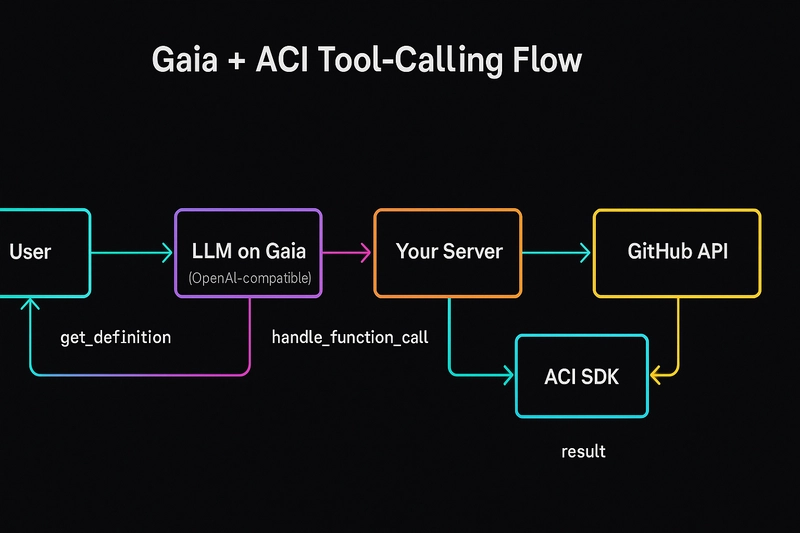
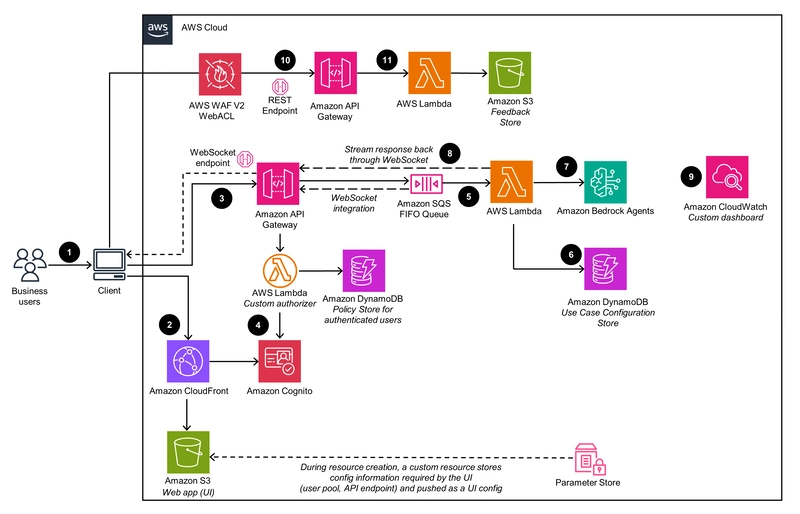
Comunidad de Desarrolladores RSS Seguir
Dev.to es un sitio web impulsado por la comunidad centrado en el desarrollo de software, la programación y la tecnología. Fue lanzado en 2016 por Ben Halpern, y su principal objetivo es brindar una plataforma para que los desarrolladores compartan conocimientos, aprendan de otros y construyan una comunidad.
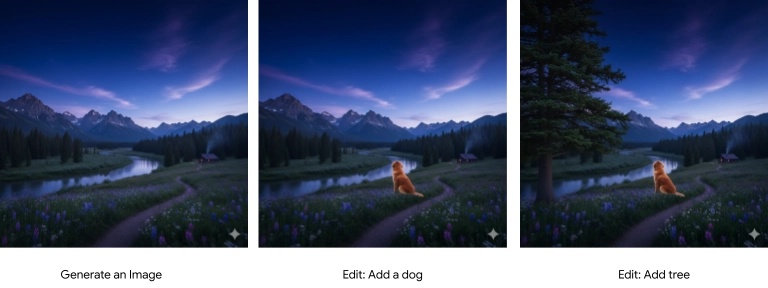
El sitio web cuenta con un formato de blog, donde los usuarios pueden crear y compartir artículos sobre diversos temas, incluyendo tutoriales de codificación, exhibiciones de proyectos, perspectivas de la industria y más. Dev.to permite a los usuarios crear cuentas, seguir a otros usuarios y interactuar con su contenido a través de comentarios y reacciones.
Dev.to tiene un fuerte enfoque en la participación de la comunidad, con características como foros de discusión, podcasts y transmisiones en vivo. También alberga una serie de proyectos comunitarios, como desafíos de codificación y hackathons, para fomentar la colaboración y la innovación.
Además del contenido generado por los usuarios, Dev.to cuenta con un tablón de anuncios laborales, donde las empresas pueden publicar ofertas de empleo y los desarrolladores pueden buscar oportunidades laborales. El sitio web también ofrece un boletín informativo, que ofrece actualizaciones sobre los últimos artículos, noticias y eventos.
En general, Dev.to ha surgido como una plataforma popular para que los desarrolladores se conecten, compartan conocimientos y se mantengan al día con las últimas tendencias y tecnologías en la industria del desarrollo de software.