Mejorando la Relevancia de la Búsqueda en Pinterest Usando Modelos de Lenguaje Extensos
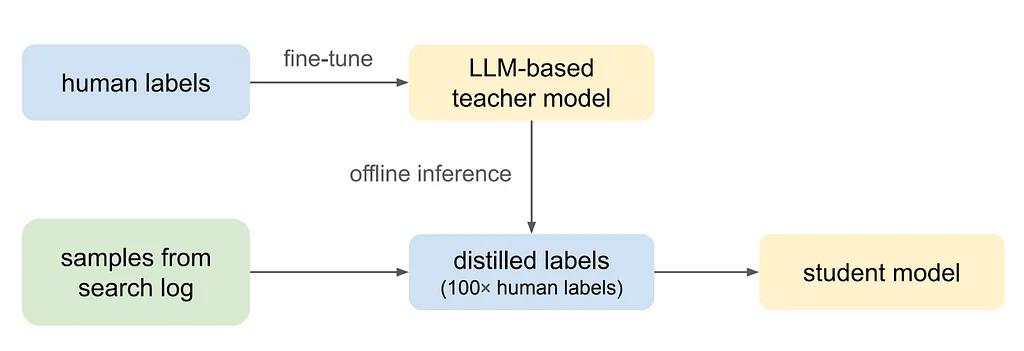
La búsqueda de Pinterest es una superficie clave donde los usuarios pueden descubrir contenido inspirador que se alinea con sus necesidades de información, y la relevancia de la búsqueda mide qué tan bien los resultados de la búsqueda se alinean con la consulta de búsqueda. Para mejorar el modelo de relevancia de la búsqueda, se utiliza una guía de 5 niveles para medir la relevancia entre las consultas y los Pins. Se utiliza un modelo de lenguaje cross-encoder para predecir la relevancia de un Pin para una consulta, junto con el texto del Pin, y la tarea se formula como un problema de clasificación multiclase. El modelo se ajusta utilizando datos anotados por humanos, minimizando la pérdida de entropía cruzada.Para representar cada Pin, se utiliza un conjunto variado de características de texto, incluidos los títulos y descripciones de los Pins, los subtítulos de imágenes sintéticas, los tokens de consulta de alta participación, los títulos de los tableros seleccionados por el usuario y los títulos y descripciones de los enlaces. Sin embargo, el clasificador basado en LLM cross-encoder es difícil de escalar para la búsqueda de Pinterest debido a consideraciones de latencia en tiempo real y costo. Por lo tanto, se utiliza la destilación de conocimiento para destilar el modelo maestro basado en LLM en un modelo de relevancia de estudiante ligero.El modelo de estudiante utiliza características a nivel de consulta, características a nivel de Pin y características de interacción consulta-Pin para predecir puntuaciones de relevancia en una escala de 5 niveles. Se emplean la destilación de conocimiento y el aprendizaje semi-supervisado para entrenar el modelo de estudiante, lo que permite un uso eficaz de grandes cantidades de datos inicialmente no etiquetados y expande los datos a una amplia gama de idiomas de todo el mundo.Los experimentos offline demuestran la eficacia de cada decisión de modelado, incluida la comparación de modelos de lenguaje, la importancia de enriquecer las características de texto y la ampliación de las etiquetas de entrenamiento mediante la destilación. Los resultados online muestran una mejora del +2,18% en la relevancia del feed de búsqueda, medida por nDCG@20, y un aumento significativo en las tasas de cumplimiento de la búsqueda a nivel mundial.La canalización de modelado de relevancia propuesta se generaliza eficazmente en idiomas no encontrados durante el entrenamiento, y el modelo maestro de relevancia basado en LLM multilingüe se generaliza en idiomas no vistos. El trabajo futuro explorará la integración de LLM que se pueden servir, modelos multimodales de visión y lenguaje y estrategias de aprendizaje activo para escalar dinámicamente y mejorar la calidad de los datos de entrenamiento.