Flux RSS du blog Google IA
Suivre
Ajustement fin de modèles de langage volumineux avec confidentialité différentielle au niveau de l'utilisateur
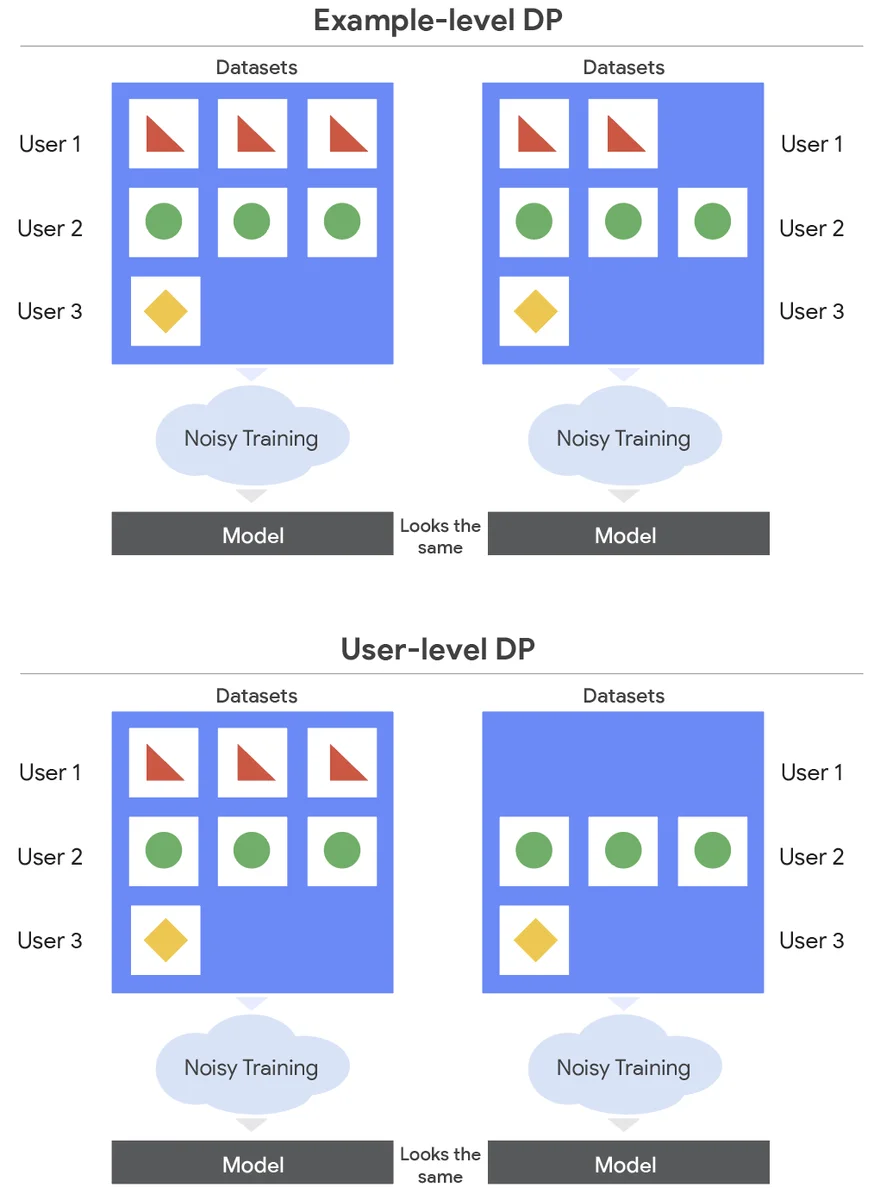
Les modèles d'apprentissage automatique nécessitent un ajustement fin sur des données spécifiques au domaine, mais cela peut être problématique en raison de préoccupations concernant la confidentialité. La confidentialité différentielle (DP) permet d'entraîner des modèles tout en respectant la confidentialité, mais la plupart des travaux se concentrent sur la DP au niveau de l'exemple, ce qui présente des inconvénients. La DP au niveau de l'utilisateur est une forme de confidentialité plus forte qui garantit qu'un attaquant ne peut pas apprendre de ses données, et elle est utilisée dans l'apprentissage fédéré. L'apprentissage avec la DP au niveau de l'utilisateur est plus difficile et nécessite d'ajouter plus de bruit, ce qui s'aggrave avec des modèles plus volumineux. Cet article se concentre sur l'ajustement fin de grands modèles linguistiques avec la DP au niveau de l'utilisateur dans l'entraînement en centre de données. Les auteurs modifient la descente de gradient stochastique (SGD) pour ajouter du bruit et limiter l'effet de chaque utilisateur sur le modèle. Ils comparent deux méthodes, l'échantillonnage au niveau de l'exemple (ELS) et l'échantillonnage au niveau de l'utilisateur (ULS), qui diffèrent dans la manière dont elles échantillonnent les données. Les auteurs optimisent ces algorithmes pour les grands modèles linguistiques, constatant que l'ULS est généralement meilleur, et que les deux méthodes fonctionnent mieux que l'absence d'ajustement fin malgré l'exigence stricte de confidentialité. Les optimisations permettent aux formateurs de modèles d'affiner leurs modèles sur des ensembles de données sensibles tout en offrant de fortes protections aux utilisateurs.