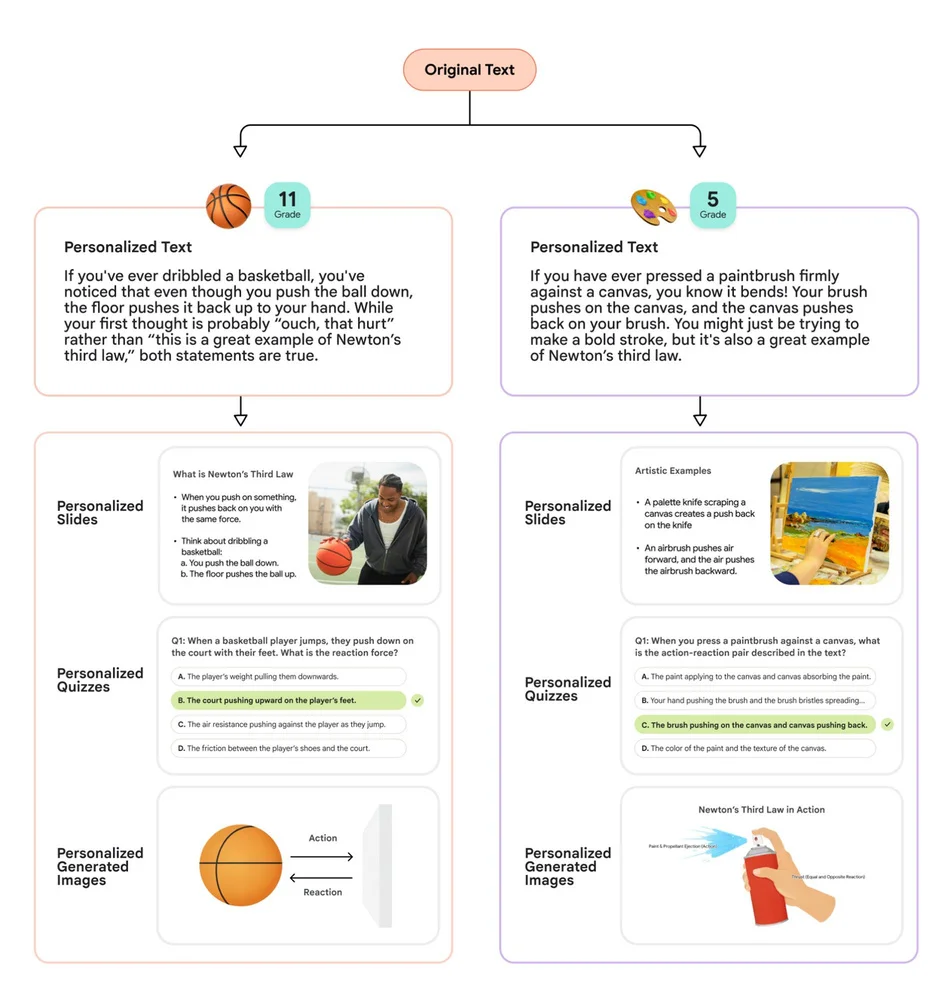
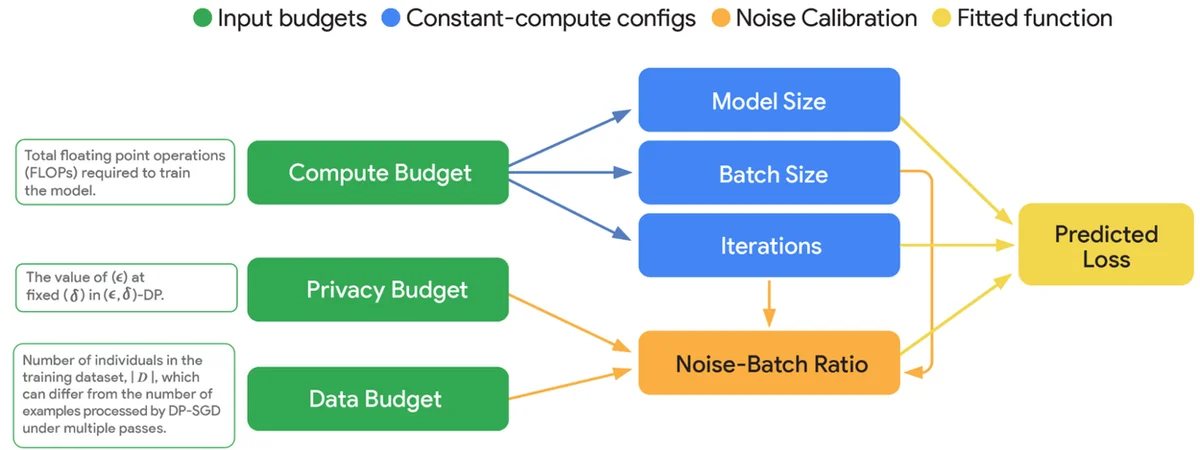
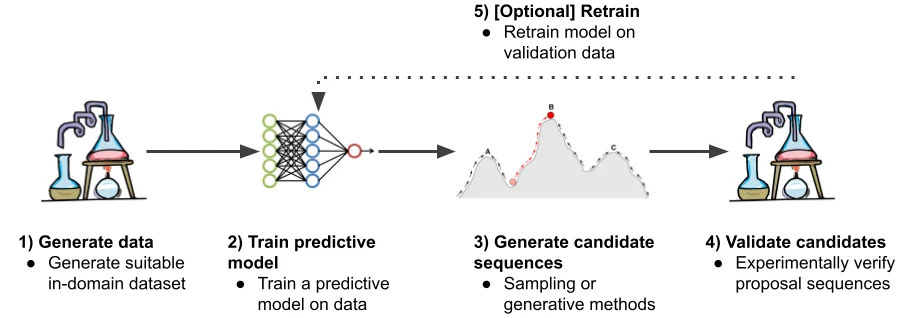
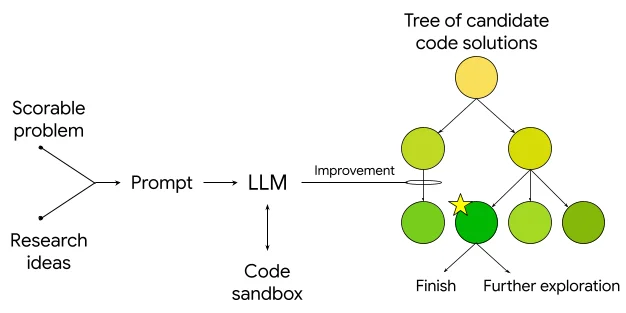
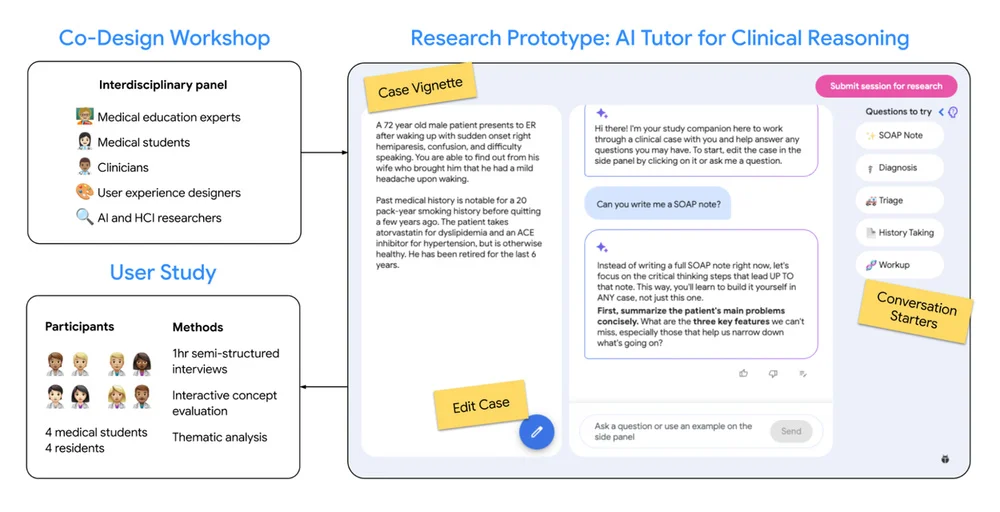
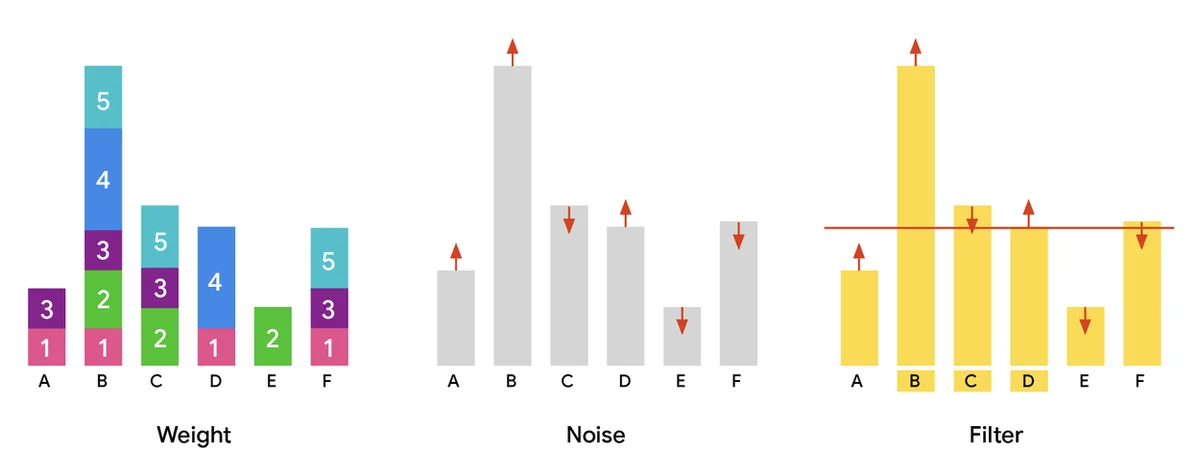
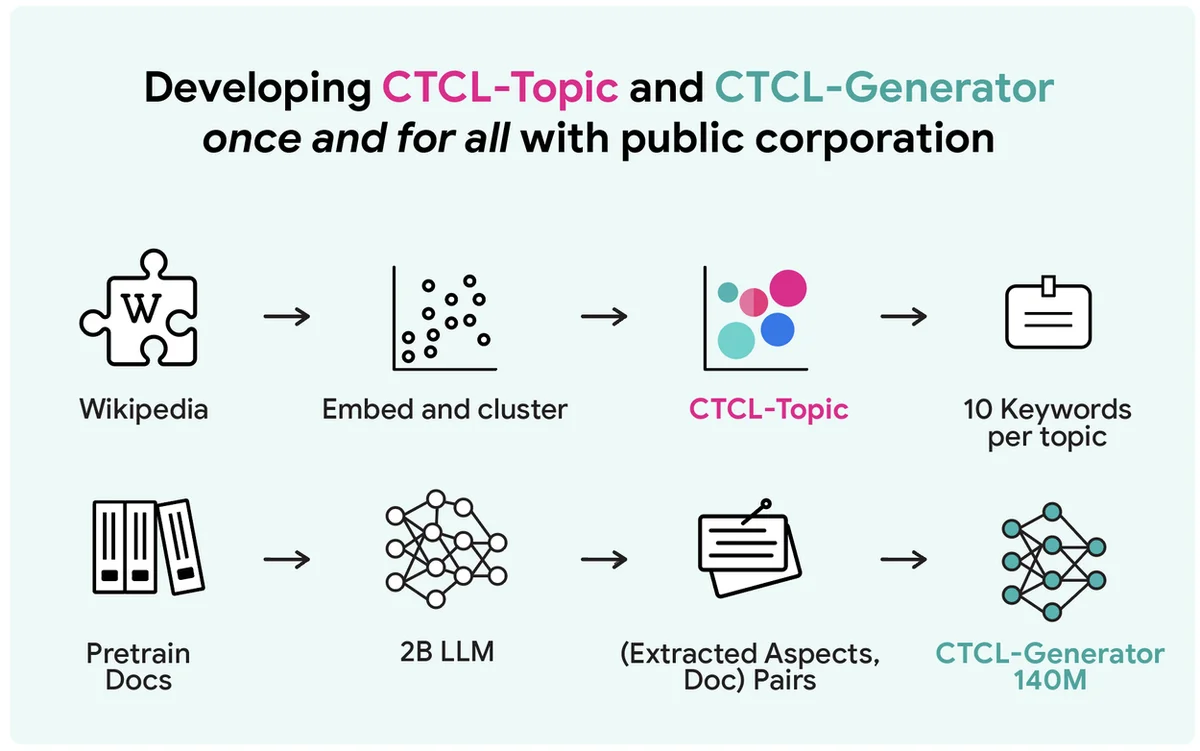
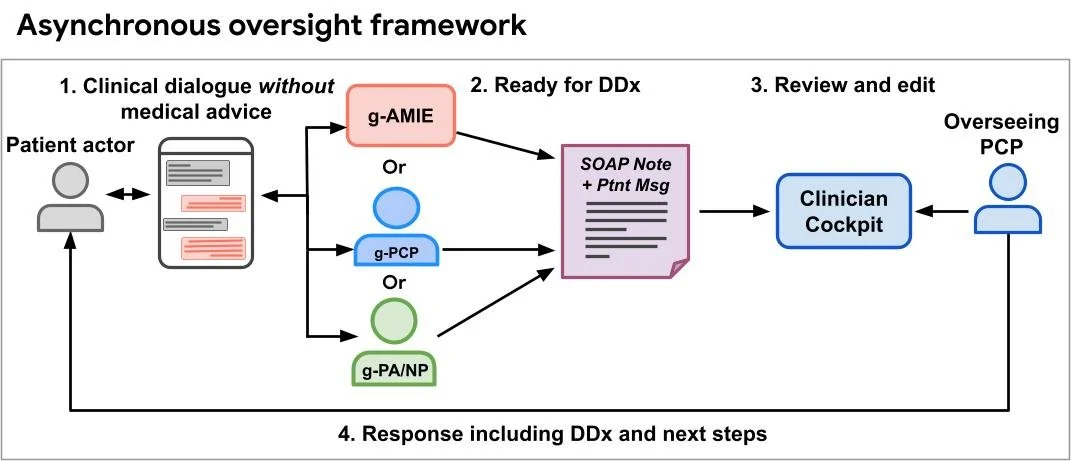
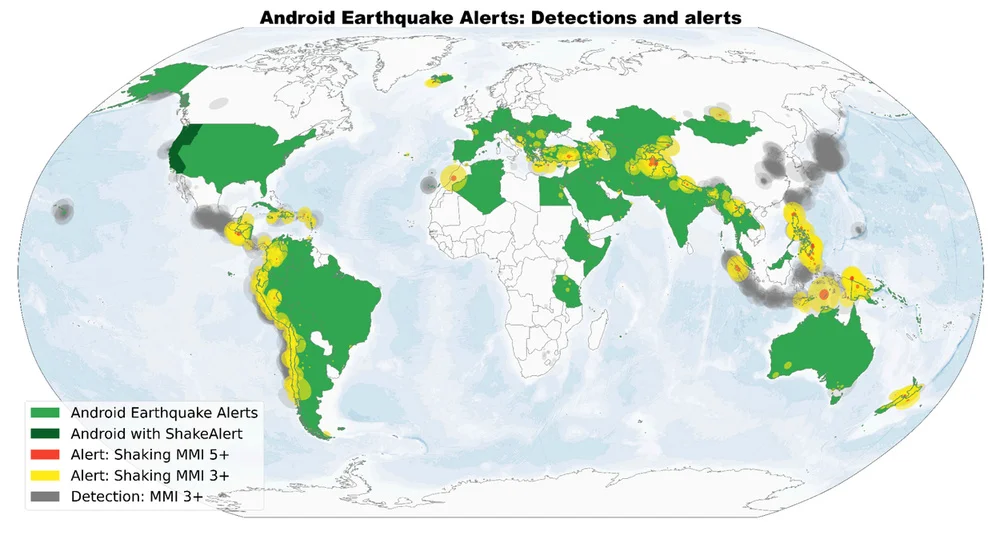
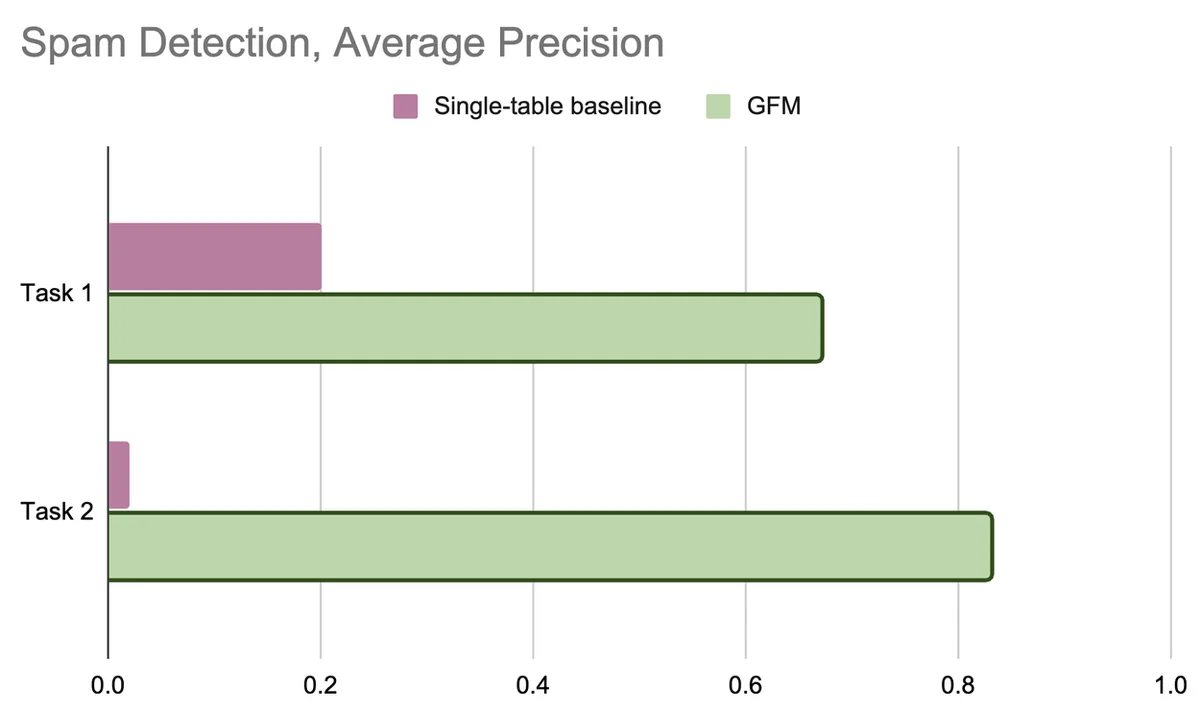
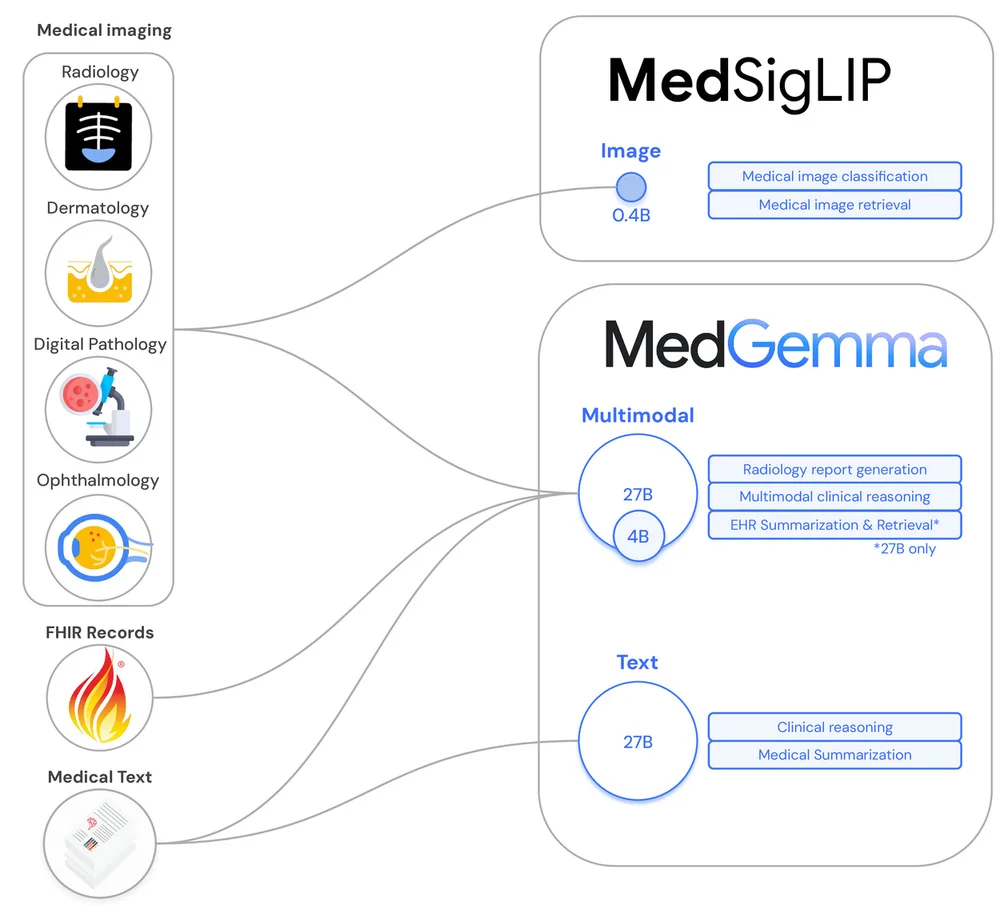
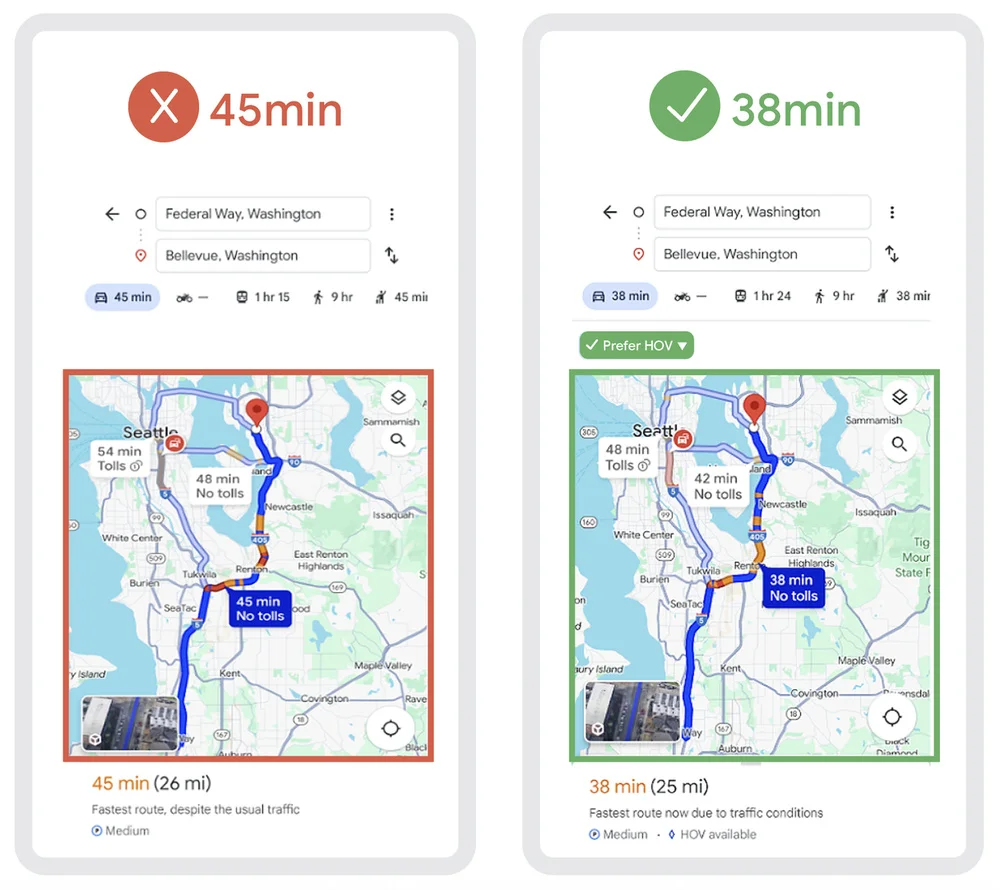
Flux RSS du blog Google IA Suivre
Le blog de Google Research est une plateforme destinée à partager les dernières percées et les révélations de la communauté scientifique de Google Research. Cette plateforme permet aux chercheurs d'interagir avec les utilisateurs en dehors des cercles scientifiques, en discutant de nouvelles technologies prometteuses, d'aperçus et d'innovations.Google Research publie fréquemment sur divers sujets scientifiques, allant de l'intelligence artificielle et de l'apprentissage automatique aux innovations dans le domaine de la santé. Il explore également souvent de nouvelles technologies, des voitures autonomes aux techniques de diagnostic médical de pointe et aux méthodes d'analyse de données.Une caractéristique notable du blog est la contribution des membres de l'équipe. De nombreux technologistes et chercheurs de premier plan chez Google fournissent des articles éclairés qui reflètent leurs intérêts et leurs compétences variés. Ce site offre l'opportunité de lire des comptes rendus de première main des dernières avancées et des visions d'avenir du monde technologique.Le blog comprend une section "auteurs", permettant aux utilisateurs d'accéder aux articles et aux révélations des contributeurs individuels. En plus des discussions techniques et des innovations, le blog traite également de questions sociales et philosophiques plus larges liées aux nouvelles technologies, offrant aux utilisateurs une compréhension plus complète de l'impact de la technologie sur notre vie quotidienne.En résumé, le blog de Google Research offre un mélange unique d'expertise technique, de percées de recherche et d'implications sociétales, en faisant de lui une ressource précieuse pour les amateurs de technologie, les chercheurs et quiconque souhaite comprendre et façonner les technologies futures.