Flux RSS du blog Google IA
Suivre
Des aperçus plus profonds sur la génération augmentée de récupération : Le rôle du contexte suffisant
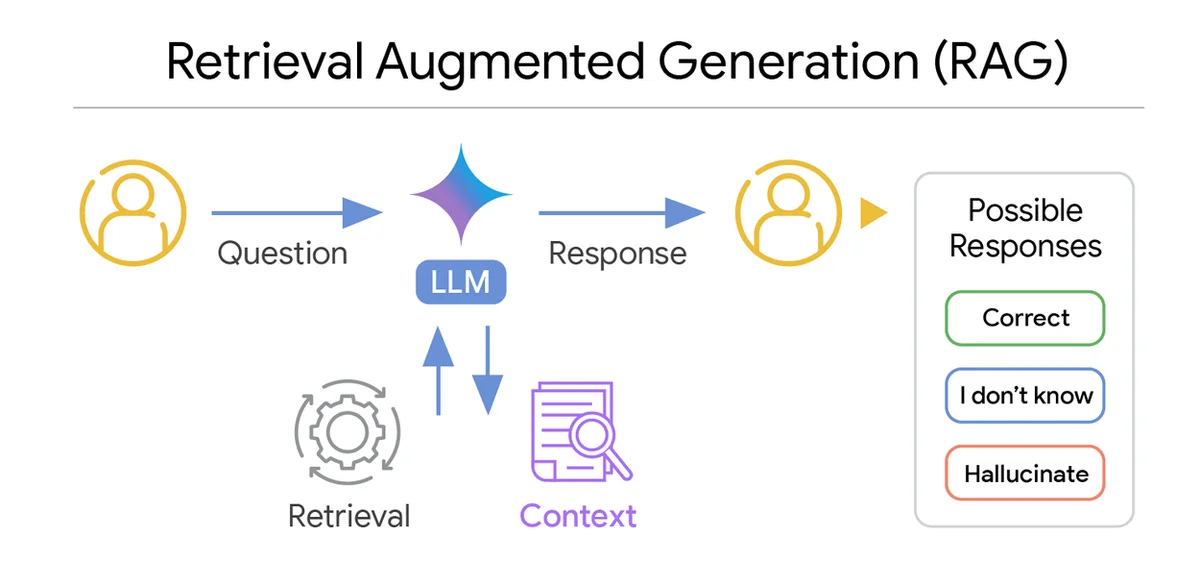
Les systèmes de génération augmentée par récupération (RAG) sont utilisés pour améliorer les grands modèles de langage (LLM) en leur fournissant des informations externes pertinentes. Idéalement, le LLM produit la bonne réponse ou répond par "Je ne sais pas" lorsqu'il manque certaines informations clés. Le principal défi des systèmes RAG est qu'ils peuvent induire l'utilisateur en erreur avec des informations hallucinées (et donc incorrectes). Les auteurs estiment que la pertinence du contexte seul est la mauvaise chose à mesurer - ils veulent vraiment savoir s'il fournit suffisamment d'informations au LLM pour répondre à la question ou non. Les auteurs définissent le contexte comme "suffisant" s'il contient toutes les informations nécessaires pour fournir une réponse définitive à la requête et "insuffisant" s'il manque les informations nécessaires. Les auteurs développent un moyen de quantifier la suffisance du contexte pour les LLM et lancent le LLM Re-Ranker dans le Vertex AI RAG Engine. Les auteurs montrent qu'il est possible de savoir quand un LLM dispose de suffisamment d'informations pour fournir une réponse correcte à une question. Les auteurs utilisent ces idées pour analyser les facteurs qui influencent la performance des systèmes RAG et pour analyser quand et pourquoi ils réussissent ou échouent. Les auteurs développent un évaluateur automatique de contexte suffisant qui évalue les paires requête-contexte et montrent qu'ils peuvent classer les contextes suffisants avec une très grande précision. Les auteurs utilisent leur évaluateur automatique de contexte suffisant pour analyser la performance de divers LLM et ensembles de données, ce qui conduit à plusieurs conclusions clés.