Flux RSS du blog Google IA
Suivre
Synthétique et fédéré : Adaptation de domaine préservant la vie privée avec des LLM pour les applications mobiles
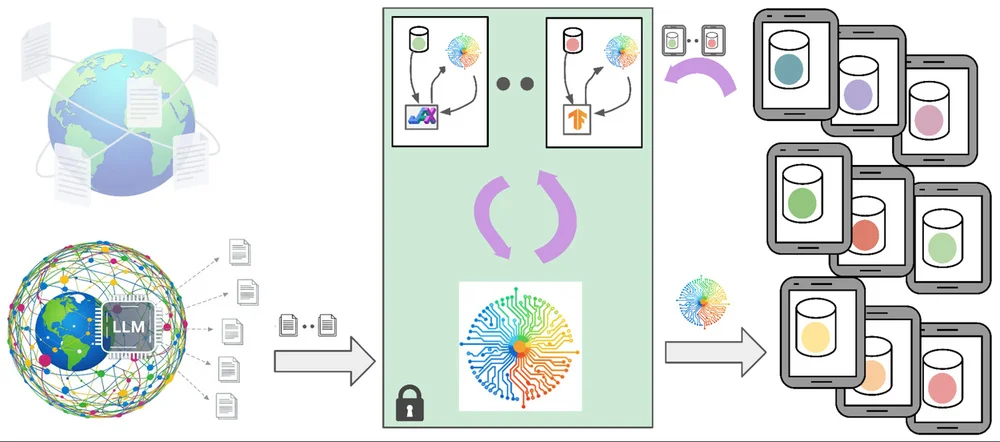
Le clavier Gboard de Google utilise de grands et petits modèles de langage (LLMs et LM) pour des fonctionnalités comme la prédiction de frappe et la correction orthographique. L'entraînement de ces modèles nécessite des données de haute qualité, mais l'utilisation de données utilisateur soulève des préoccupations de confidentialité. Pour répondre à cela, Gboard emploie des données synthétiques générées par des LLM entraînés sur des données publiques, imitant l'interaction utilisateur sans révéler d'informations privées. Ces données synthétiques pré-entraînent les modèles, améliorant leur performance avant une formation supplémentaire avec des techniques de préservation de la confidentialité comme l'apprentissage fédéré et la confidentialité différentielle. Cette approche minimise les risques de confidentialité tout en améliorant significativement la précision des modèles, ce qui se traduit par des améliorations des fonctionnalités de Gboard. Le processus implique de solliciter les LLM pour générer des données de frappe mobile réaliste, qui sont ensuite utilisées pour pré-entraîner des modèles plus petits. Un "module de soutien", un petit modèle entraîné sur des données utilisateur avec confidentialité différentielle, affine encore les données synthétiques pour une meilleure adaptation de domaine. Cette approche combinée améliore à la fois les petits et les grands modèles, améliorant les fonctionnalités de Gboard tout en protégeant la confidentialité des utilisateurs. Le système intègre plusieurs garanties de confidentialité, notamment la minimisation et l'anonymisation des données. Les recherches en cours se concentrent sur l'amélioration de la génération et de l'application de données synthétiques préservant la confidentialité pour une performance de modèle encore meilleure et une expérience utilisateur améliorée.