Flux RSS du blog Google IA
Suivre
Apprendre à clarifier : Conversations en plusieurs tours avec auto-entraînement contrastif basé sur les actions
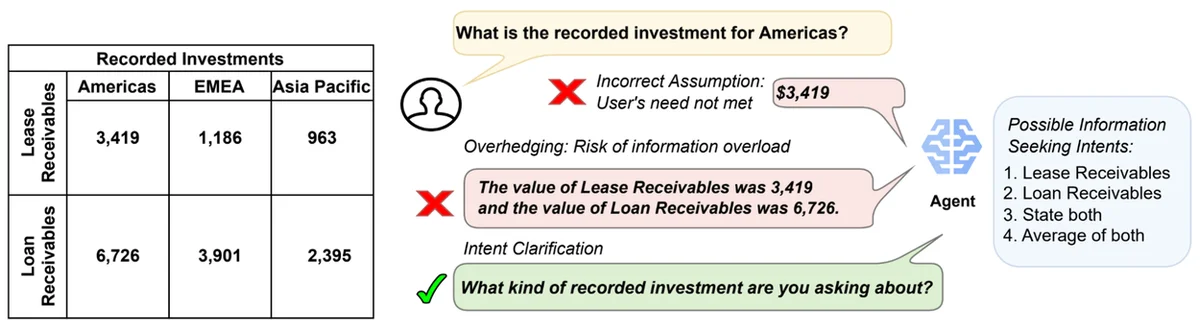
Les modèles de langage de grande taille (LLMs) sont devenus un paradigme principal pour développer des agents conversationnels intelligents, mais ils manquent souvent de compétences conversationnelles multi-tours telles que la désambiguïsation. Pour remédier à cela, les auteurs proposent la formation auto-supervisée par contraste basée sur les actions (ACT), un algorithme d'optimisation quasi-en ligne qui permet d'apprendre des politiques de dialogue efficaces dans la modélisation de conversations multi-tours. ACT démontre des améliorations substantielles de la modélisation de conversations par rapport aux approches d'ajustement standard telles que la mise à jour supervisée et la DPO. Les auteurs introduisent également AmbigSQL, une tâche novatrice pour désambiguïser les requêtes d'information complexes générant du code SQL structuré. ACT implique la construction d'un jeu de données de préférence, la synthèse de réponses rejetées et la mise à jour de politique utilisant l'objectif DPO. Les auteurs expérimentent ACT avec des LLMs à poids ouverts sur un ensemble diversifié de données conversationnelles et comparent avec diverses lignes de base compétitives, notamment la mise à jour supervisée, l'optimisation de préférence par raisonnement itératif et la mise en contexte d'exemples d'apprentissage avec Gemini et Claude. ACT atteint les meilleures performances sur tous les métriques, avec une amélioration relative de jusqu'à 19,1% par rapport à la mise à jour supervisée lors de la mesure de la capacité du modèle ajusté à reconnaître implicitement l'ambiguïté. Les auteurs réalisent également des études d'ablation pour comprendre les avantages de chaque composant d'ACT et trouvent que les préférences basées sur les actions, l'échantillonnage en ligne et la simulation de trajectoire sont cruciaux pour améliorer l'achèvement des objectifs multi-tours. Dans l'ensemble, ACT est une approche agnostique du modèle qui peut améliorer les performances, indépendamment de l'alignement préalable avec les retours humains.