Flux RSS du blog Google IA
Suivre
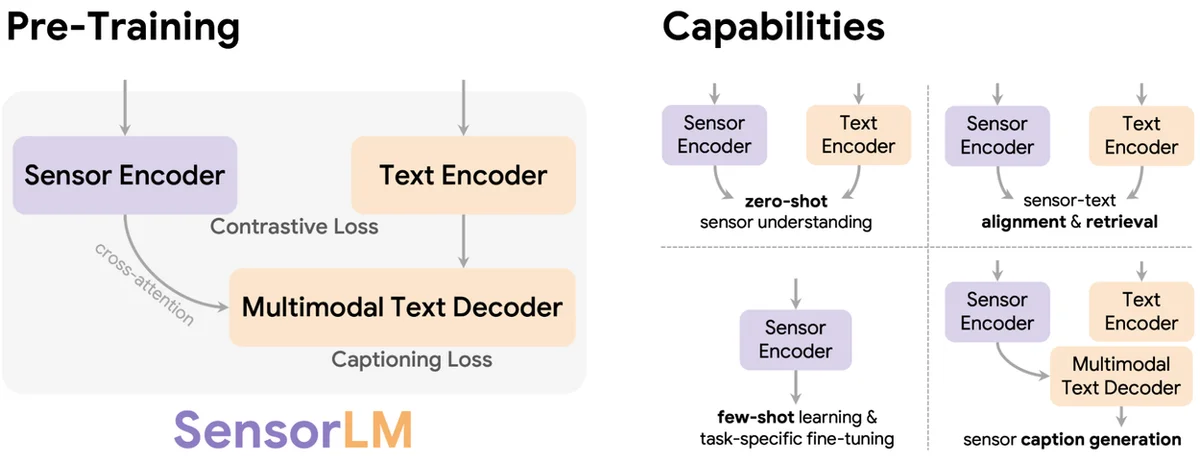
SensorLM : Apprentissage du langage des capteurs portables
Les appareils portables collectent d'énormes quantités de données de santé personnelles, mais comprendre le contexte derrière ces données a été un défi. Cette lacune empêche de réaliser le plein potentiel des informations personnalisées sur la santé. L'annotation manuelle des données de capteurs avec du texte descriptif est irréalisable en raison des coûts et du temps. Pour résoudre ce problème, SensorLM, une famille de modèles fondamentaux sensoriels-linguistiques, a été développée. SensorLM est pré-entraîné sur un volume sans précédent de 59,7 millions d'heures de données multimodales de capteurs provenant de plus de 103 000 individus. Cela lui permet d'interpréter et de générer des descriptions lisibles par l'homme à partir des données des capteurs portables. Un pipeline hiérarchique novateur génère automatiquement des légendes descriptives, créant ainsi le plus grand ensemble de données sensoriels-linguistiques à ce jour. SensorLM offre des capacités telles que la compréhension des capteurs en mode zéro-shot, l'alignement capteurs-texte et la génération de légendes de capteurs. Il démontre des performances de pointe dans des tâches telles que la reconnaissance d'activité et excelle dans la génération de légendes cohérentes et factuellement correctes. Les performances du modèle s'améliorent constamment avec plus de données, des modèles plus grands et une puissance de calcul accrue. SensorLM représente une avancée significative pour rendre les données de santé personnelles compréhensibles et exploitables, ouvrant la voie aux futurs coachs de santé numériques et aux applications de bien-être.