Flux RSS du blog Google IA
Suivre
Sécuriser les données privées à grande échelle avec une sélection de partitions différentiellement privée
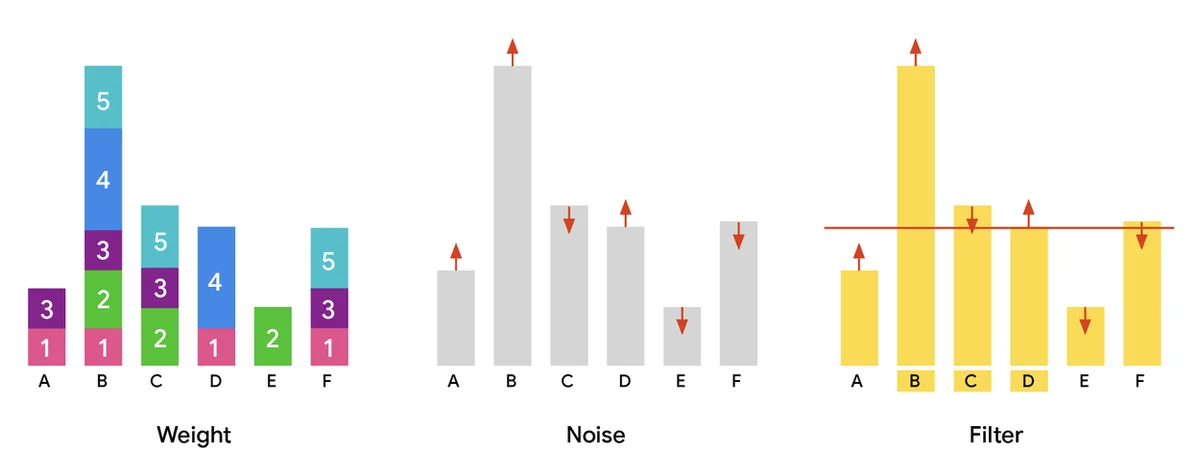
Les jeux de données volumineux basés sur les utilisateurs sont essentiels à l'avancement de l'IA, améliorant les services et la personnalisation. Le partage de ces jeux de données accélère la recherche mais pose des risques pour la vie privée. La sélection de partitions différentiellement privées (DP) identifie des sous-ensembles de données sûrs et communs en ajoutant du bruit pour protéger les contributions individuelles. Ceci est crucial pour des tâches telles que l'extraction de vocabulaire et l'analyse de données privées. Le traitement de jeux de données massifs nécessite des algorithmes parallèles, pas seulement pour la vitesse, mais pour gérer des échelles immenses. Notre publication, « Scalable Private Partition Selection via Adaptive Weighting », présente un algorithme parallèle efficace pour la sélection de partitions DP. Cet algorithme est scalable jusqu'à des centaines de milliards d'éléments, dépassant considérablement les capacités précédentes. L'objectif est de maximiser les éléments sélectionnés tout en préservant la vie privée des utilisateurs, en priorisant les données populaires. L'approche standard implique la pondération, l'ajout de bruit et le filtrage des éléments en fonction d'un seuil. Notre nouvel algorithme de pondération adaptative, MAD, réaffecte le "poids excédentaire" des éléments populaires à ceux qui se situent juste en dessous du seuil de confidentialité. Cela améliore l'utilité en incluant plus d'éléments sans compromettre la confidentialité ou la scalabilité. Les expériences montrent que notre algorithme MAD à deux itérations obtient des résultats de pointe, produisant plus d'éléments que d'autres méthodes avec les mêmes garanties de confidentialité. Nous rendons notre algorithme open-source pour favoriser l'innovation communautaire.