Flux RSS du blog Google IA
Suivre
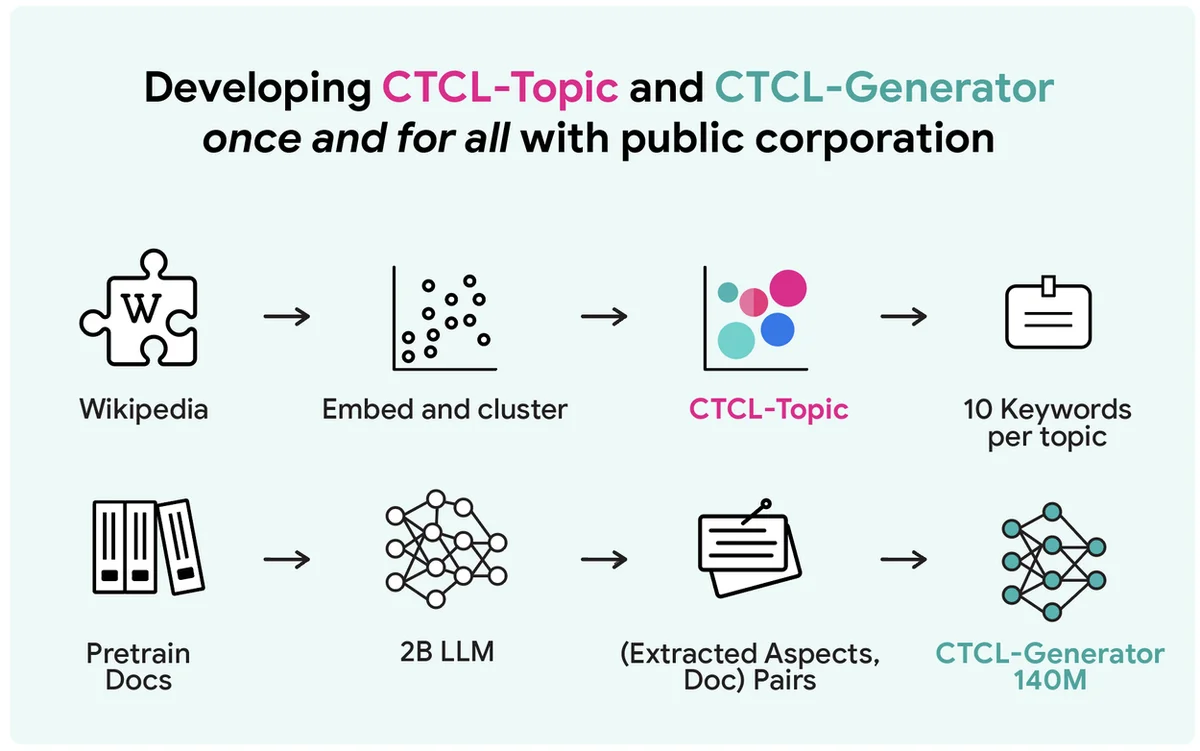
Au-delà des fardeaux de paramètres à billions : Déverrouiller la synthèse de données avec un générateur conditionnel
La génération de données textuelles synthétiques à grande échelle et différentiellement privées fait face à un compromis entre la confidentialité, les calculs et l'utilité. Une méthode courante mais coûteuse en termes de calcul consiste à affiner les grands modèles de langage sur des données privées. Les approches basées sur des API comme Aug-PE reposent sur des prompts manuels et ont du mal à utiliser les informations privées. Le cadre CTCL proposé génère des données synthétiques préservant la confidentialité sans avoir à affiner de grands modèles de langage massive ou à nécessiter une ingénierie de prompts extensive. Il utilise un modèle léger de 140 millions de paramètres, ce qui le rend adapté aux environnements à ressources limitées. CTCL conditionne la génération en fonction des informations de topic pour correspondre aux distributions de données privées. Contrairement à Aug-PE, CTCL peut produire des échantillons de données synthétiques illimités sans coûts de confidentialité supplémentaires. Les expériences montrent que CTCL surpasse les repères, en particulier sous des garanties de confidentialité fortes, démontrant son efficacité pour capturer des informations utiles. Les études d'ablation confirment l'importance de la pré-entraînement et de la conditionnalisation basée sur des mots-clés pour les performances et la scalabilité de CTCL. L'idée centrale de CTCL peut être étendue à des modèles plus grands pour améliorer les applications réelles.