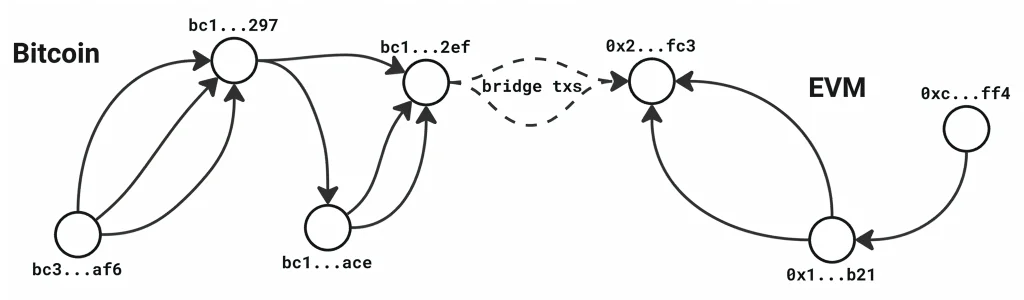
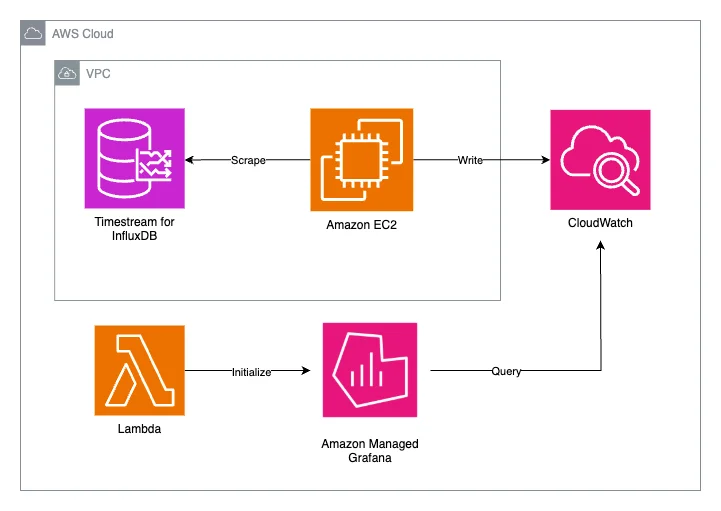
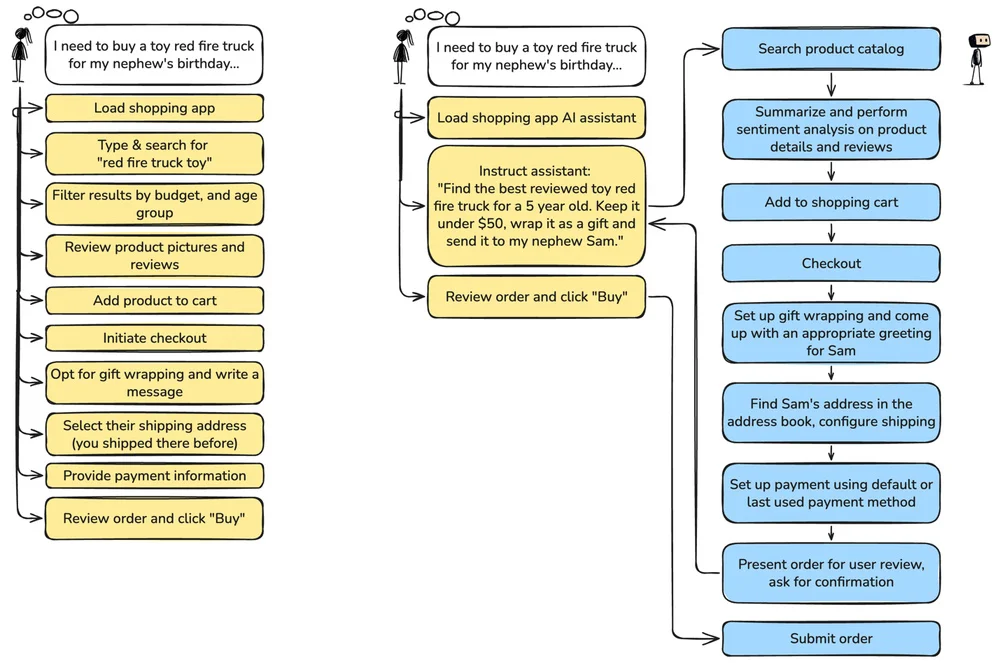
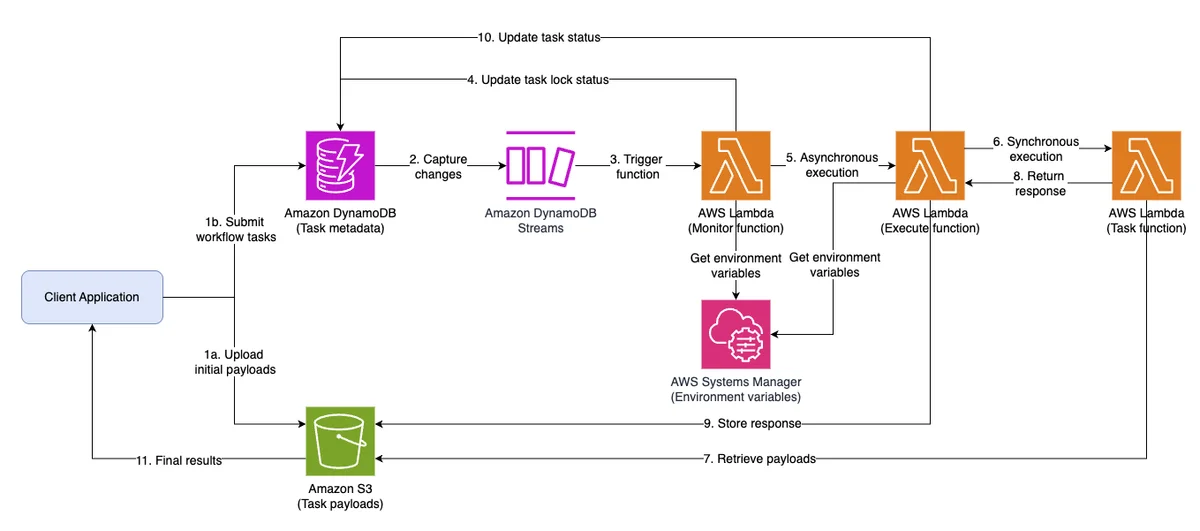
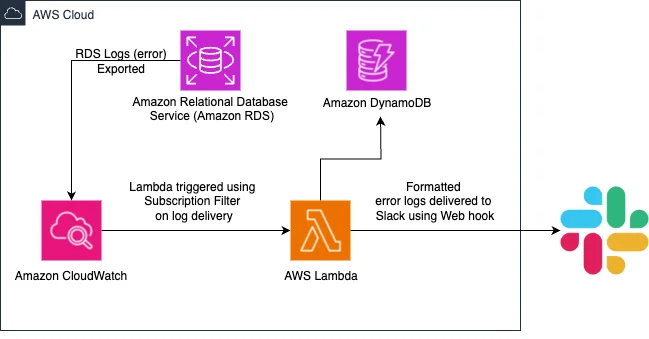
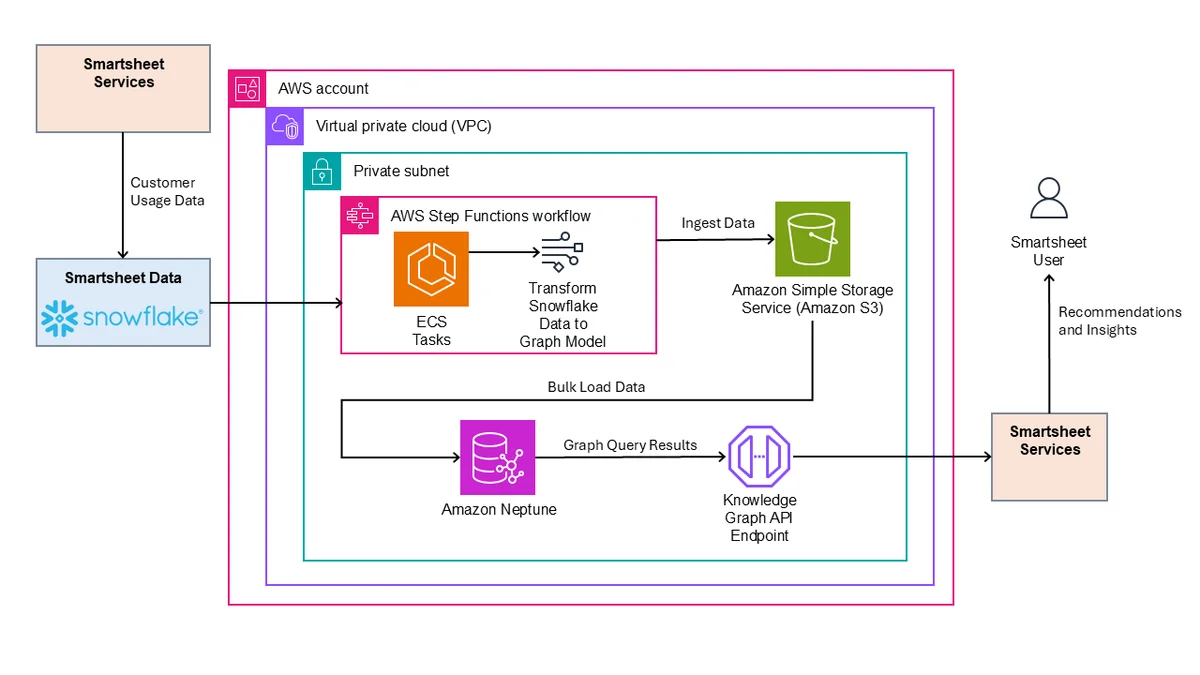
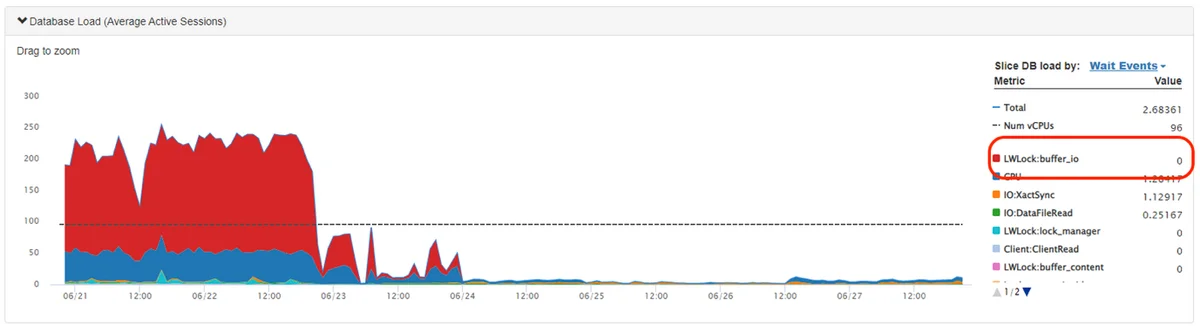
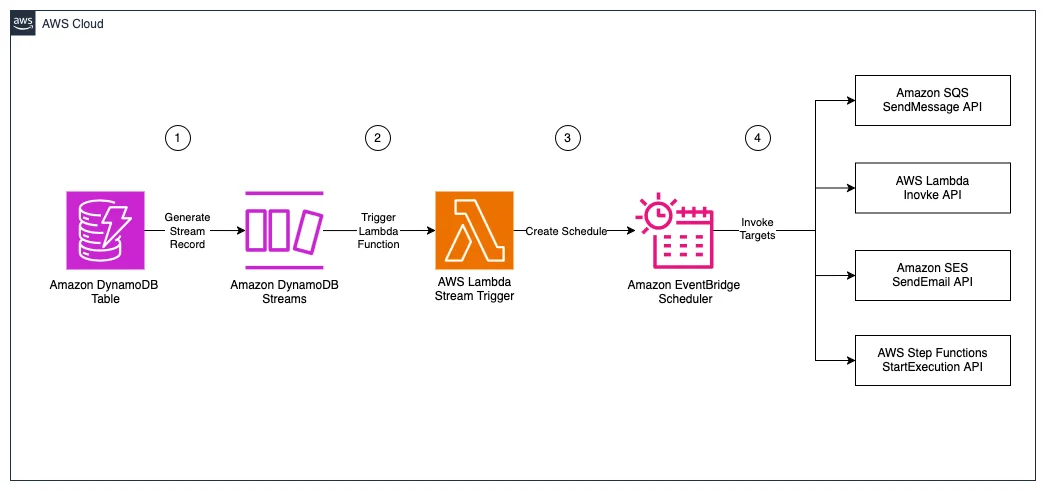
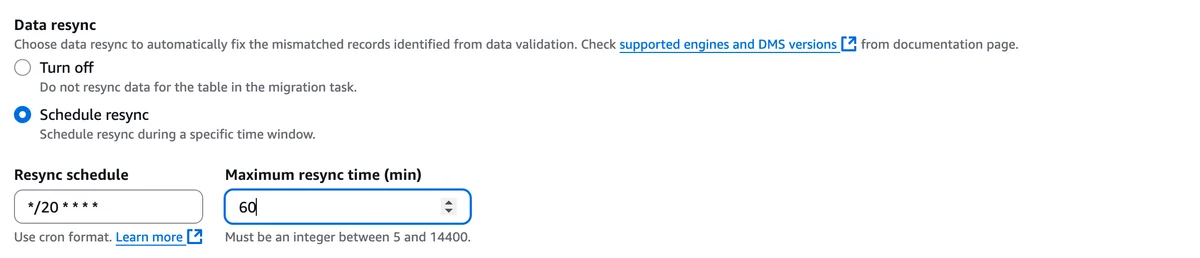
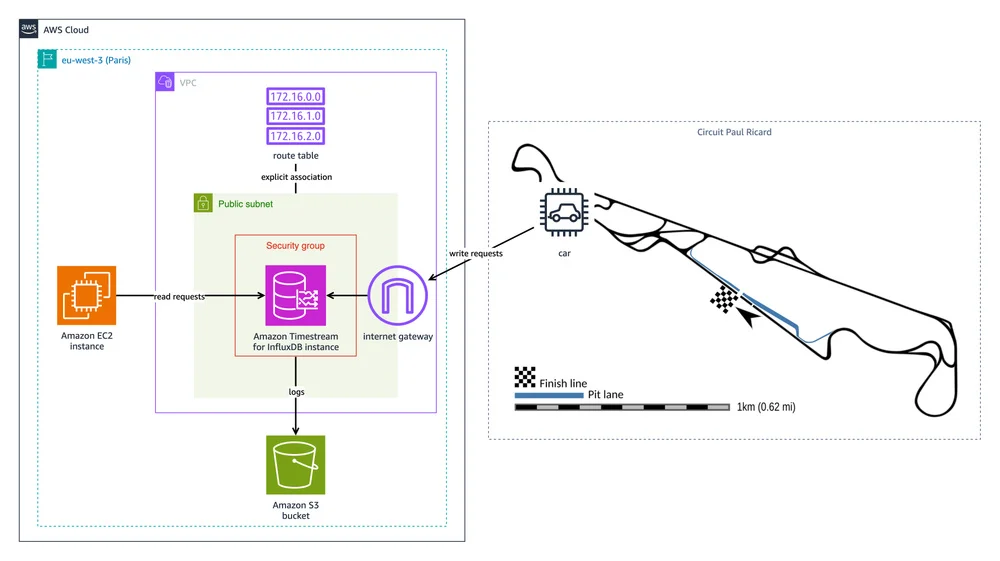
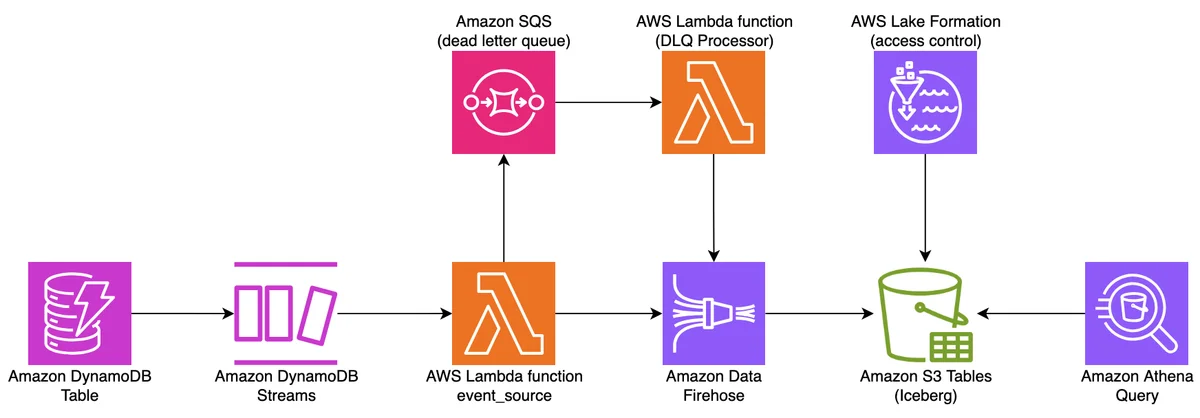
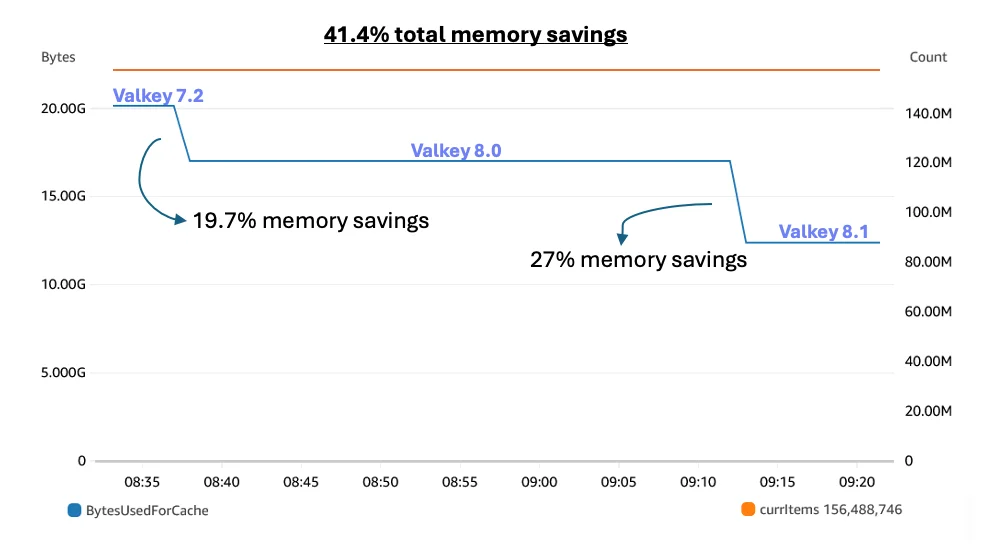
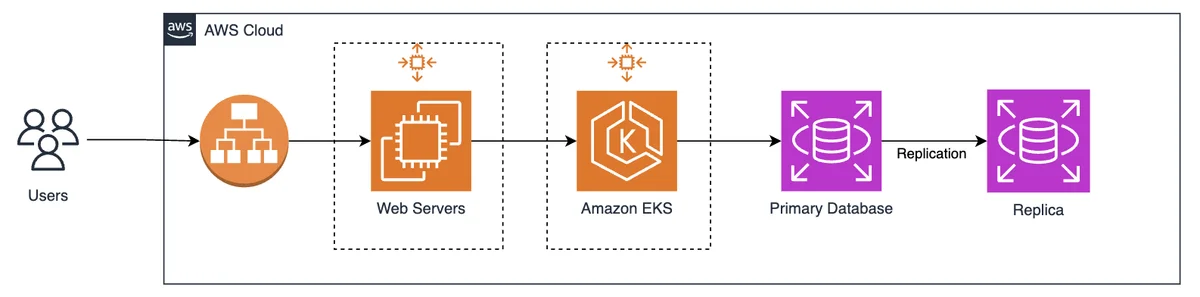
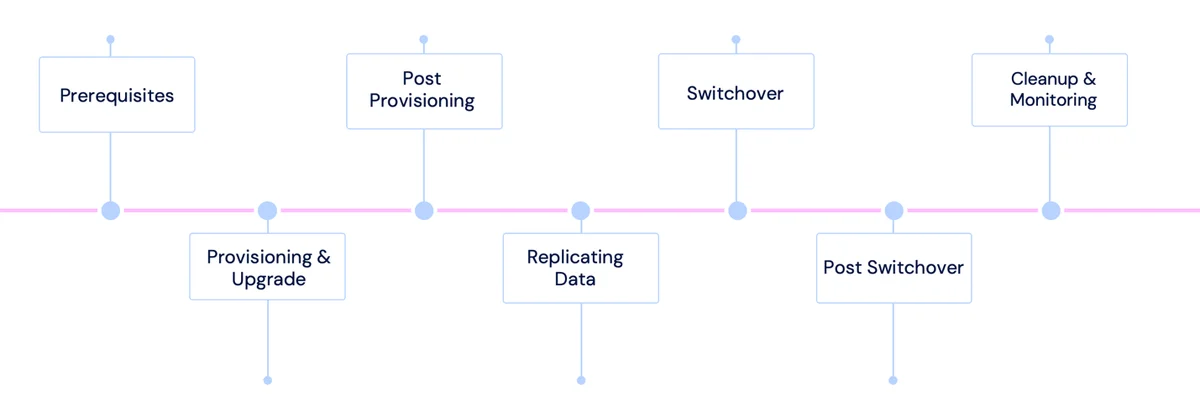
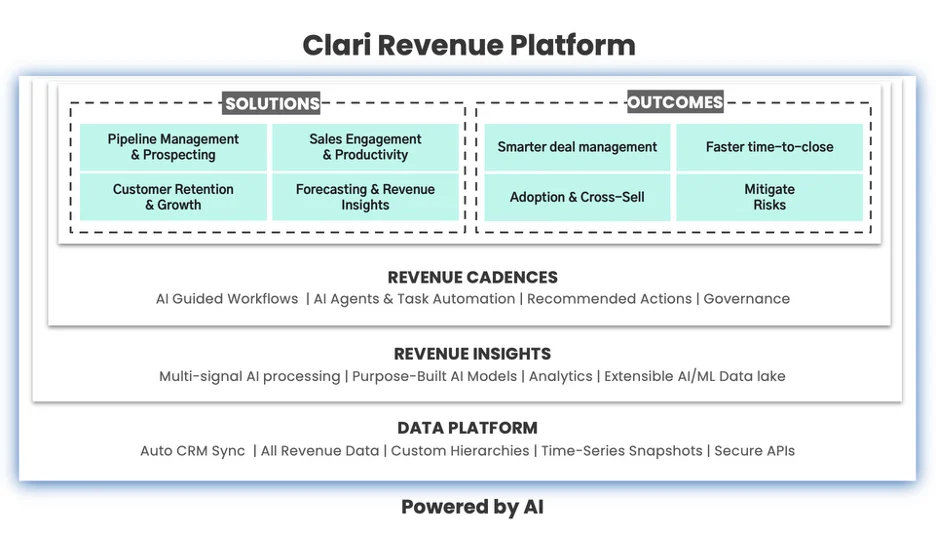
Flux RSS de la base de données AWS Blog Suivre
Le site web propose un blog Amazon Web Services (AWS) pour les bases de données, qui vise à aider les utilisateurs à utiliser efficacement les services de bases de données AWS en offrant des tutoriels utiles, des conseils et des réponses aux questions fréquemment posées.