10億パラメータの負担を超えて:条件付き生成器によるデータ合成の解放
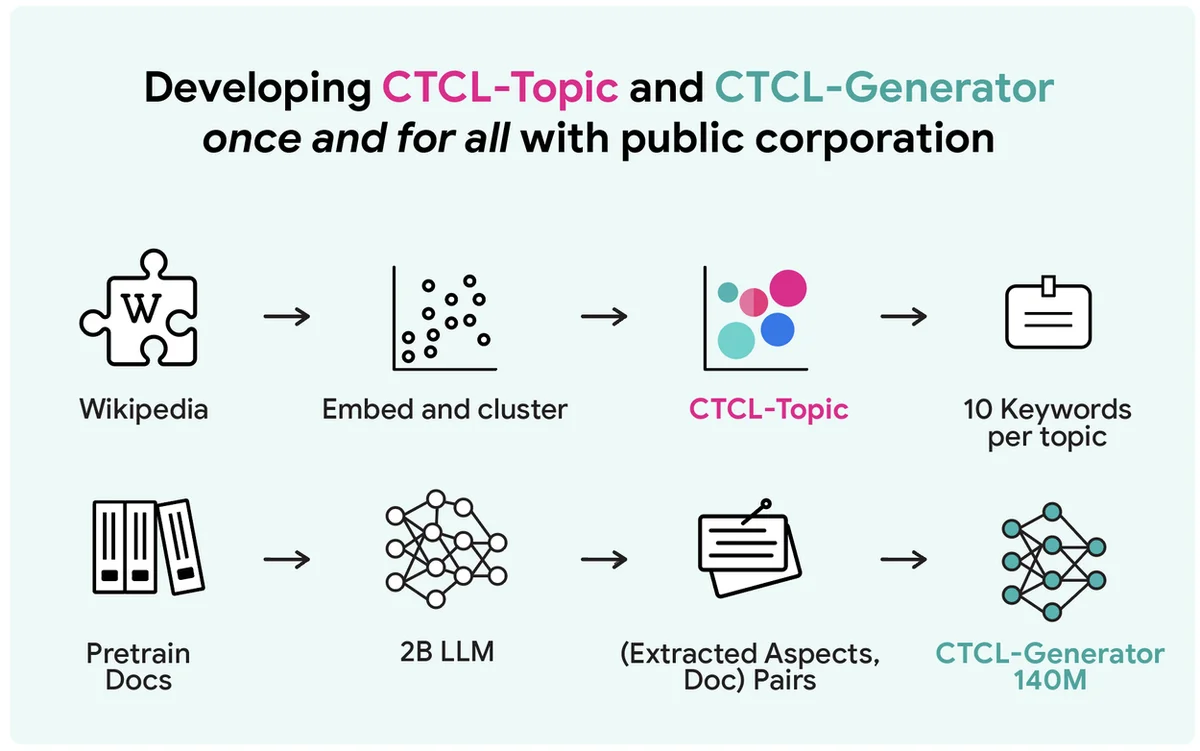
大規模な差分プライベート合成テキストデータの生成は、プライバシー、計算、ユーティリティのトレードオフに直面しています。一般的だが計算コストの高い方法には、プライベートデータで大規模言語モデルをファインチューニングすることが含まれます。Aug-PEのような既存のAPIベースのアプローチは、手動のプロンプトに依存しており、プライベート情報の利用に苦労しています。提案されているCTCLフレームワークは、大規模なLLMのファインチューニングや、広範なプロンプトエンジニアリングを必要とせずに、プライバシーを保護する合成データを生成します。これは、リソースが制約された環境に適した、軽量な1億4千万パラメータモデルを利用しています。CTCLは、プライベートデータの分布に合わせるために、トピック情報に基づいて生成を条件付けます。Aug-PEとは異なり、CTCLは追加のプライバシーコストなしで無制限の合成データサンプルを生成できます。実験によると、CTCLはベースラインを上回り、特に強力なプライバシー保証の下で、有用な情報を捕捉する効果を示しています。アブレーションスタディは、CTCLのパフォーマンスとスケーラビリティにおける事前トレーニングとキーワードベースの条件付けの重要性を確認しています。CTCLのコアアイデアは、より優れた実際のアプリケーションのために、より大きなモデルに拡張できます。