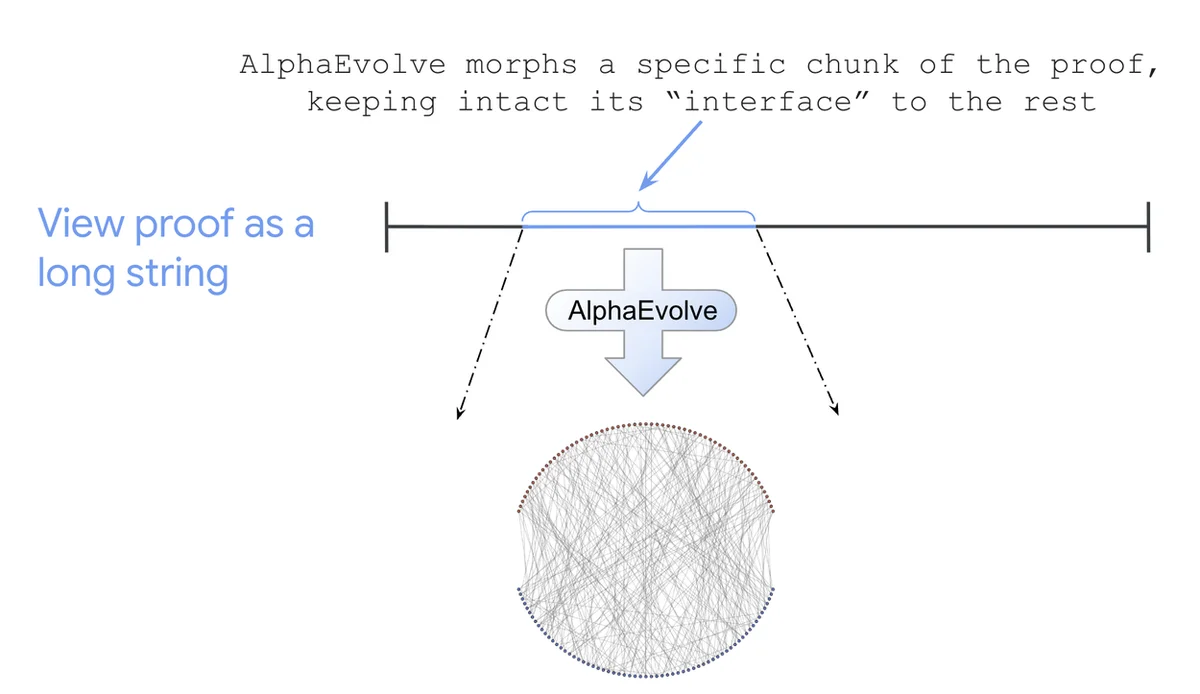
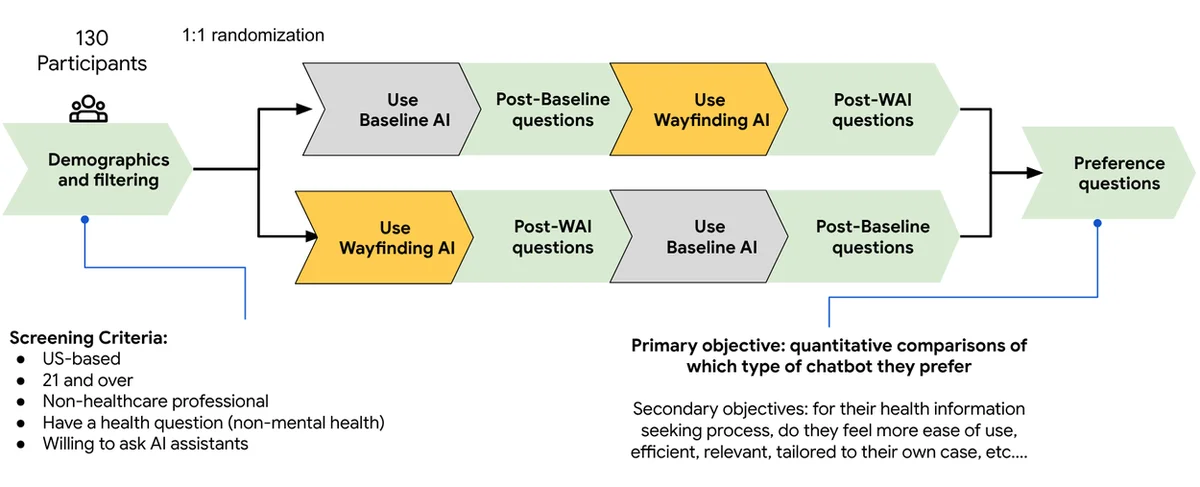
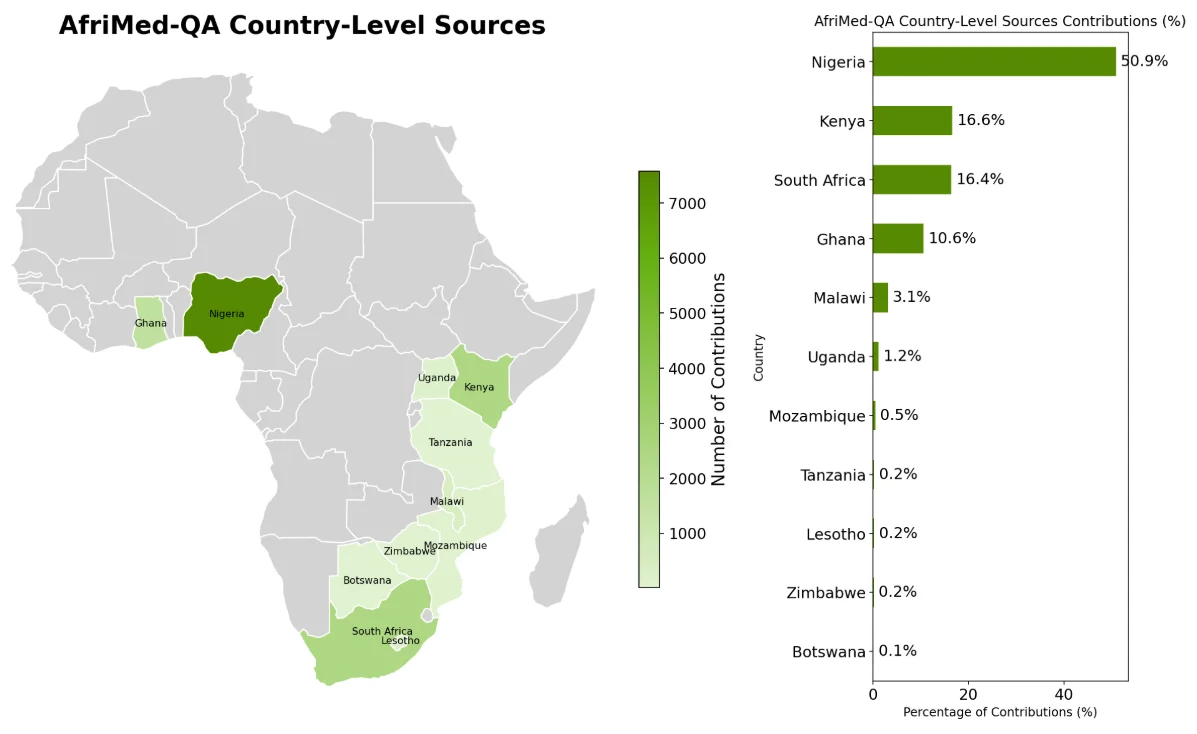
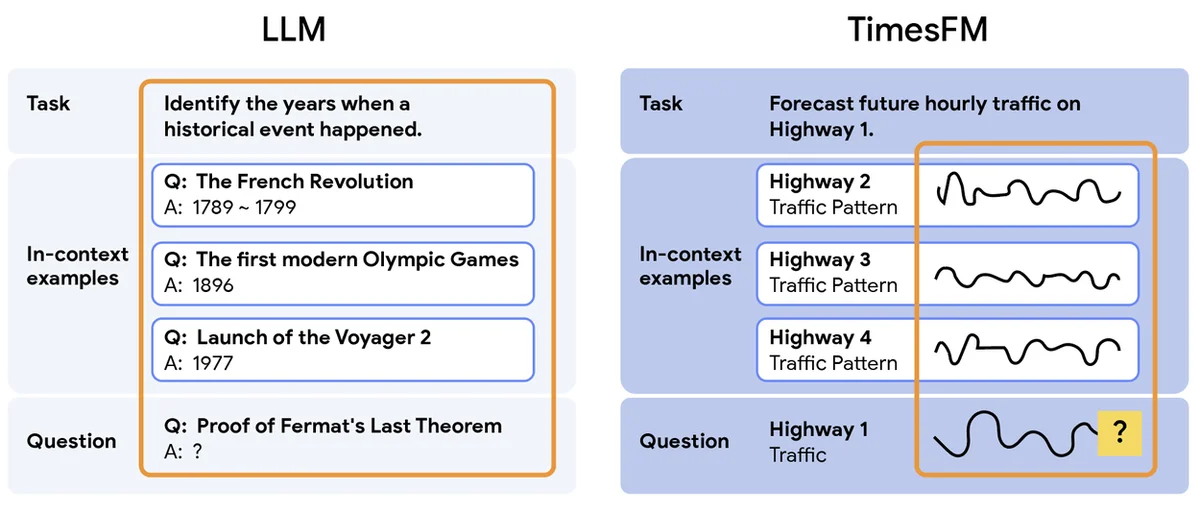
RSS Google AI Blog(RSS グーグル AI ブログ) フォロー
Google Researchは、Google Researchの科学コミュニティから最新のブレークスルーと洞察を共有することを目的としたブログです。このプラットフォームは、研究者が科学的なサークル以外の人々と関わるための手段となり、新しい技術、洞察、革新について話し合います。Google Researchは、人工知能や機械学習からヘルスケアの革新まで、さまざまな科学的なトピックについて頻繁に投稿しています。また、自動運転車から最先端の医療診断やデータ分析技術まで、新しい技術についてもよく取り上げています。このブログの特徴的な機能の1つは、チームメンバーの投稿です。Googleのトップの技術者や研究者が、多様な関心やスキルを反映した洞察的な記事を提供しています。このサイトでは、最新の進歩や技術の世界の将来のビジョンについて、第一手で読むことができます。ブログには、「著者」セクションがあり、ユーザーが個々の投稿者の記事や洞察にアクセスできます。技術的な議論や革新だけでなく、ブログは新しい技術に関連する社会的および哲学的な問題にも取り組み、ユーザーが技術が私たちの日常生活にどのように影響するかをより包括的に理解できるようにしています。本質的に、Google Researchブログは、技術的専門知識、研究のブレークスルー、社会的影響を独自のブレンドで提供し、技術愛好家、研究者、将来の技術を理解し、形作りたい人にとって貴重なリソースとなっています。