合成データと連合学習:モバイルアプリケーション向けLLMによるプライバシー保護ドメイン適応
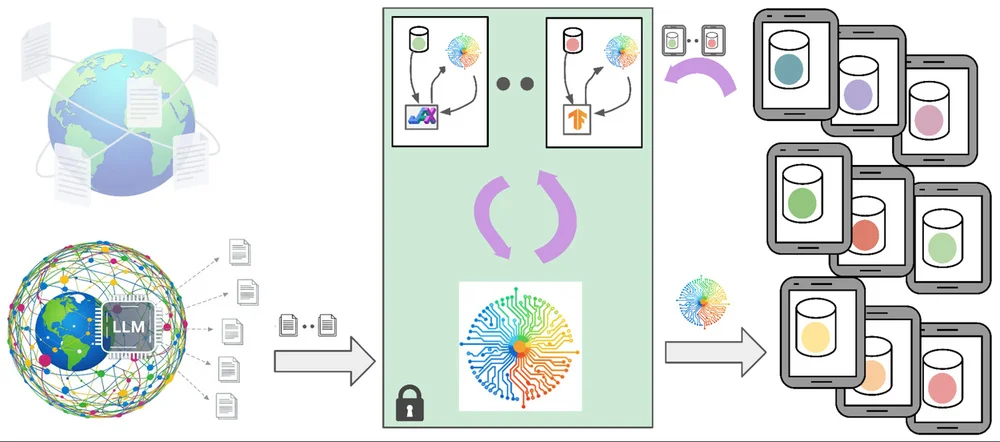
「GoogleのGboardは、タイピング予測や校正機能において、大型言語モデル(LLM)と小型言語モデル(LM)を活用しています。これらのモデルのトレーニングには、高品質のデータが必要ですが、ユーザーデータを使用するとプライバシーに関する懸念が生じます。そのため、Gboardは、公的データに基づいてトレーニングされたLLMによって生成された合成データを使用して、プライベート情報を明かさないままユーザーインタラクションを模倣しています。この合成データを使用して、モデルのプリトレーニングを行い、フェデレーテッドラーニングや差分プライバシーのようなプライバシー保護技術を使用して、モデルのパフォーマンスを向上させています。このアプローチにより、プライバシーのリスクを最小化しながら、モデルの正確さを大幅に向上させることができ、Gboardの機能を改善しています。プロセスでは、LLMにモバイルタイピングデータを生成させるプロンプトを与え、生成されたデータを使用して小型モデルのプリトレーニングを行います。また、「buttress module」と呼ばれる小型モデルは、差分プライバシーを使用してユーザーデータをトレーニングし、ドメイン適応を改善するために合成データをさらに改良しています。この複合アプローチにより、小型モデルと大型モデルの両方を改善し、Gboardの機能を向上させつつ、ユーザーのプライバシーを守ることができます。システムには、データ最小化や匿名化などの多くのプライバシーサーフガードが組み込まれています。現在、プライバシー保護の合成データの生成と適用に関する研究が継続されており、モデルのパフォーマンスとユーザー体験の向上を目指しています。」