高忠実度ラベルによるトレーニングデータの大幅な削減(10,000倍)
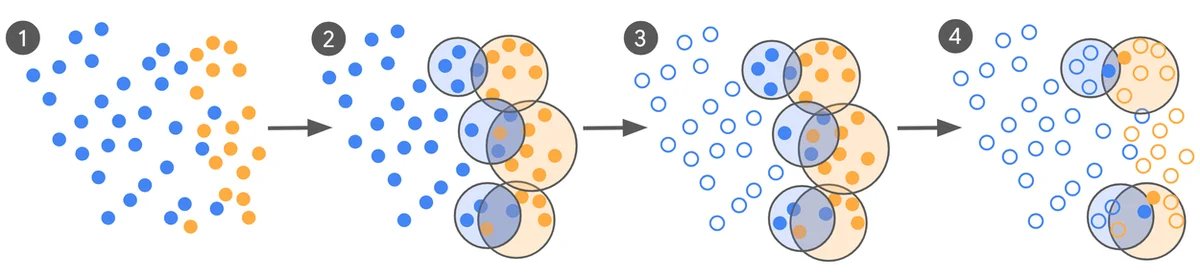
不適切な広告コンテンツを分類することは、コンテキストを理解する能力がある大規模言語モデル(LLM)にとって適したタスクですが、LLMをそのようなタスクに微調整するには、高品質で大規模なトレーニングデータが必要であり、これをキュレーションすることは費用がかかり、時間がかかる作業です。安全性ポリシーが変更される概念ドリフトにより、頻繁な再トレーニングが必要になり、コストが増加します。これに対処するために、新しいアクティブラーニングキュレーションプロセスは、トレーニングデータの量を大幅に削減しながら、モデルと人間の専門家の整合性を向上させることができます。このプロセスは、注釈付けのために最も貴重な例を特定し、データ要件を大幅に削減します。実験では、トレーニングデータを10万から500未満の例に削減し、モデル整合性を最大65%向上させることが示されました。キュレーションプロセスは、ゼロショットLLMによるデータのラベル付けから始まり、混同可能な例を特定するためにクラスタリングが行われます。これらの情報豊富で多様な例は、人間の専門家にラベル付けのために送信されます。専門家のラベルは、モデルを評価および微調整するために使用されます。プロセスは、基準となるラベルがしばしば曖昧であるため、整合性を測定するためにCohenのカッパを使用します。大規模なクラウドソーシングデータセットで微調整されたベースラインモデルは、キュレーションされたモデルに比べて効果が低かったです。新しい方法は、慎重にキュレーションされたより少ない情報豊富な例が、劇的に少ないデータで大幅なパフォーマンスの向上につながることを実証しています。このアプローチは、コンテンツが急速に進化する広告の安全性などのドメインにとって特に有益です。