差分プライバシーを用いた大規模なプライベートデータ保護のためのパーティション選択
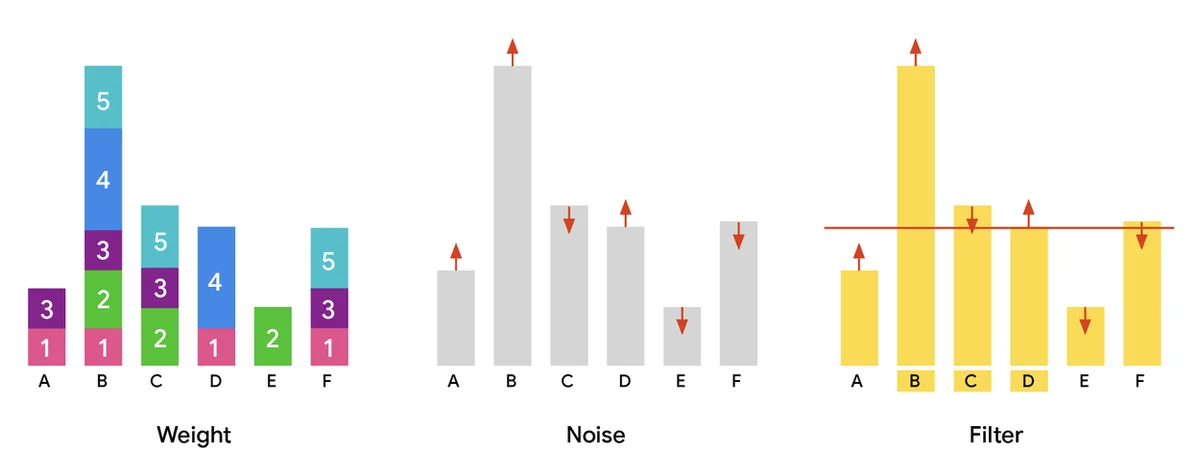
「大規模なユーザーベースのデータセットは、AIの進歩、サービス改善、およびパーソナライゼーションのために不可欠です。ただし、これらのデータセットを共有するとプライバシーのリスクが生じます。差分プライベート(DP)パーティション選択は、個々の貢献を保護するためにノイズを追加し、安全で共通のデータサブセットを特定します。これは、ボキャブラリー抽出やプライベートデータ分析のようなタスクにとって非常に重要です。大規模なデータセットを処理するには、スピードだけでなく、巨大なスケールに対応するために並列アルゴリズムが必要です。我々の論文「Scalable Private Partition Selection via Adaptive Weighting」では、DPパーティション選択のための効率的な並列アルゴリズムを提案しています。このアルゴリズムは、数百億アイテムにスケールアップし、以前の能力を大幅に超えています。目標は、ユーザーのプライバシーを保持しながら、人気のあるデータを優先して選択されたアイテムを最大化することです。標準的なアプローチは、ウェイティング、ノイズの追加、および閾値に基づくアイテムのフィルタリングです。我々の新しい適応ウェイティングアルゴリズムMADは、人気のあるアイテムからプライバシーの閾値以下にあるアイテムに「余剰ウェイト」を再配分します。これにより、プライバシーを損なうことなく、より多くのアイテムを含めることができます。実験結果では、2回のイテレーションのMADアルゴリズムが、同じプライバシーの保証で他の方法よりも多くのアイテムを出力することを示しています。我々は、コミュニティーのイノベーションを促進するために、アルゴリズムをオープンソース化しています。」