現実世界のための合成データセット設計:メカニズム設計と第一原理からの推論
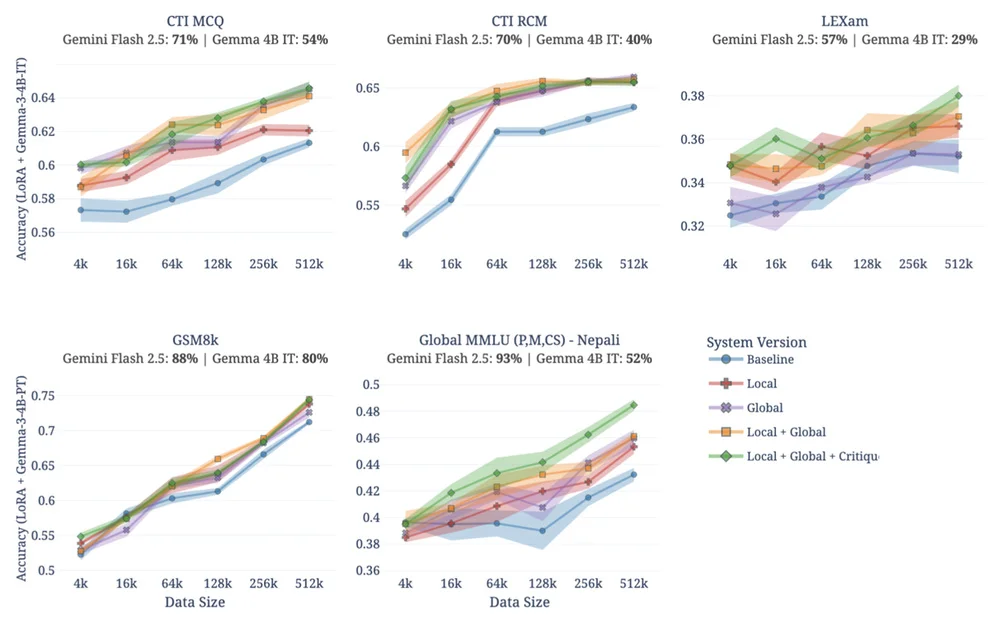
この論文は、実世界のデータが乏しい、あるいはアクセスできない場合に不可欠な、合成データを生成することによる特殊AIモデル作成の課題に取り組んでいます。提案されたフレームワークであるSimulaは、合成データ生成を制御を優先するメカニズム設計問題として再構築します。Simulaの「推論優先」アプローチは、階層的な分類法を通じてグローバルな多様性を確保しながら、第一原理からデータセットを構築します。ローカルな多様性は、メタプロンプトを使用して、概念内のバリエーションを確保し、モード崩壊を防ぎます。このフレームワークには、難易度を調整するための複雑化と、正しさを検証するための品質チェックも組み込まれています。Simulaシステムは、サイバーセキュリティや法的推論などの多様なドメインにわたる実験で、単純なベースラインを常に上回っています。評価には、分類法のカバレッジや調整された複雑度スコアリングなどの推論ベースのメトリックが使用されます。この研究結果は、データはモデルの能力に合わせて調整する必要があり、データの質は量よりも重要であることを強調しています。SimulaはGoogleのデータエンジンとして機能し、特殊モデルやユーザー保護機能の実現を可能にします。さらに、Simulaは、現実的な攻撃シナリオの合成や、AIに地図の読み方を教える研究を可能にします。合成データは将来のAIの進歩にとって極めて重要であり、Simulaはデータ生成を制御する可能性を示しています。