回帰言語モデルによる大規模システムのシミュレーション
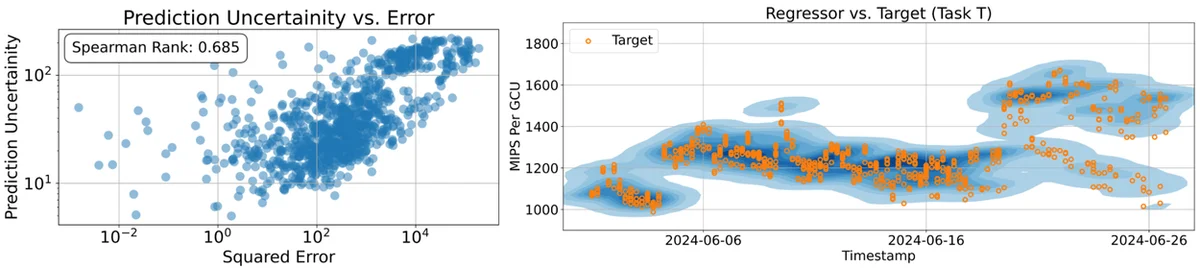
大規模言語モデル(LLM)は、人間が好むデータから学習することで、役立つテキストを生成できるように強化されています。新しいアプローチでは、運用データを使用して、パフォーマンスメトリックを予測するための報酬モデルをトレーニングすることで、これを拡張します。従来の回帰では、複雑で構造化されていないデータを扱うのが難しく、手間のかかる特徴量エンジニアリングが必要になります。本論文では、テキストからテキストへの回帰を実行する回帰言語モデル(RLM)を紹介します。これは、テキスト入力を直接処理して、数値予測を文字列として出力します。この方法では、特徴量エンジニアリングを回避し、新しいタスクへの数ショット適応を可能にします。RLMは、結果の確率分布を捉え、予測の不確実性を定量化できます。このアプローチは、Googleの大規模コンピューティングインフラストラクチャであるBorgにおけるリソース効率の予測に適用されました。RLMは、Million Instructions Per Second per Google Compute Unit(MIPS per GCU)を効果的に予測しました。この新しいパラダイムは、生のテキストから数値結果を予測するためのスケーラブルで効率的な方法を提供し、普遍的なシステムシミュレーターや高度な報酬メカニズムを可能にします。