大規模言語モデルを用いたピンタレスト検索の関連性の向上
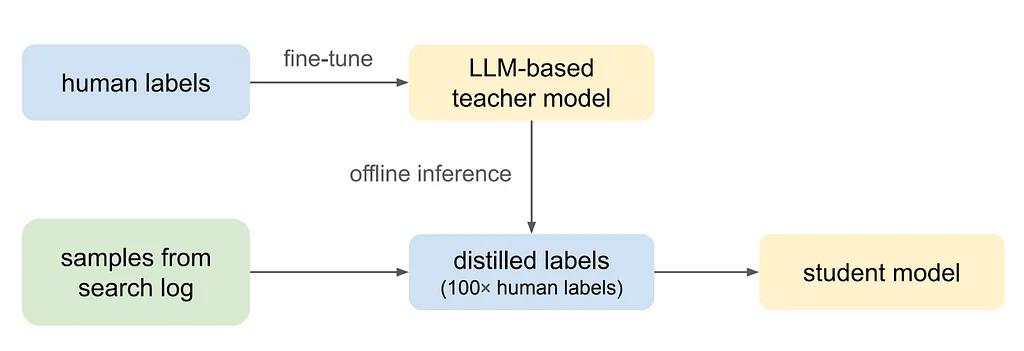
ピンタレスト検索は、ユーザーが自分の情報ニーズに合ったインスピレーションを得ることができる重要な機能であり、検索の関連性は、検索結果が検索クエリとどれだけ一致するかを測定します。検索の関連性モデルを改善するために、クエリとピン(画像)の関連性を測定するための5段階のガイドラインが使用されています。クロスエンコーダ言語モデルを使用して、ピンの関連性を予測し、ピンテキストとともに、タスクはマルチクラス分類問題として定式化されています。モデルは、人間が注釈をつけたデータを使用して、クロスエントロピー損失を最小化することでファインチューンされています。各ピンを表現するために、ピンのタイトルと説明、合成画像キャプション、エンゲージメントの高いクエリトークン、ユーザーが作成したボードのタイトル、リンクのタイトルと説明など、さまざまなテキスト機能が使用されています。ただし、クロスエンコーダLLMベースのクラシファイアーは、ピンタレスト検索のリアルタイム遅延とコストの考慮により、拡大するのが難しいです。したがって、知識の蒸留を使用して、LLMベースの教師モデルを軽量な生徒関連モデルに蒸留しています。生徒モデルは、クエリレベルの機能、ピンレベルの機能、およびクエリとピンの相互作用機能を使用して、5段階の関連性スコアを予測します。知識の蒸留と半教師あり学習を使用して、生徒モデルを訓練し、初期にラベル付けされていない大量のデータを効果的に活用し、世界中のさまざまな言語にデータを拡大しています。オフライン実験では、言語モデルの比較、テキスト機能の豊富化の重要性、蒸留を通じてトレーニングラベルの拡大などの各モデリングの決定の有効性が実証されています。オンライン結果では、nDCG@20によって測定された検索フィードの関連性が+2.18%改善され、世界中で検索の充実率が大幅に増加しました。提案された関連性モデリングパイプラインは、トレーニング中に遭遇しなかった言語にも効果的に一般化し、マルチリンガルLLMベースの関連性教師モデルは、見られない言語にも一般化します。将来的には、提供可能なLLM、ビジョンと言語のマルチモーダルモデル、およびアクティブラーニング戦略の統合を探求して、トレーニングデータの品質を動的に拡大して改善することを目指しています。