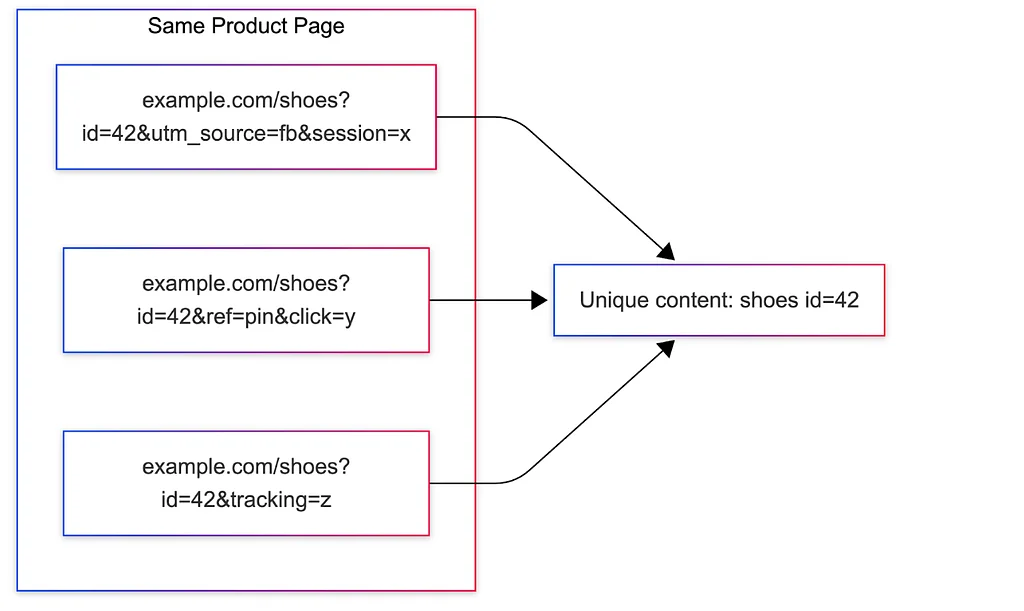
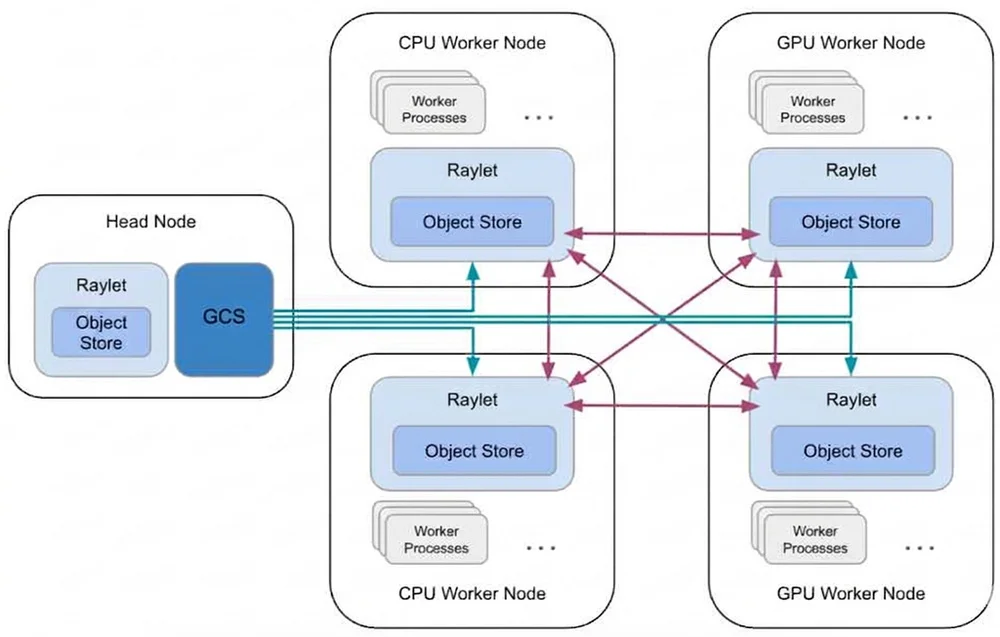
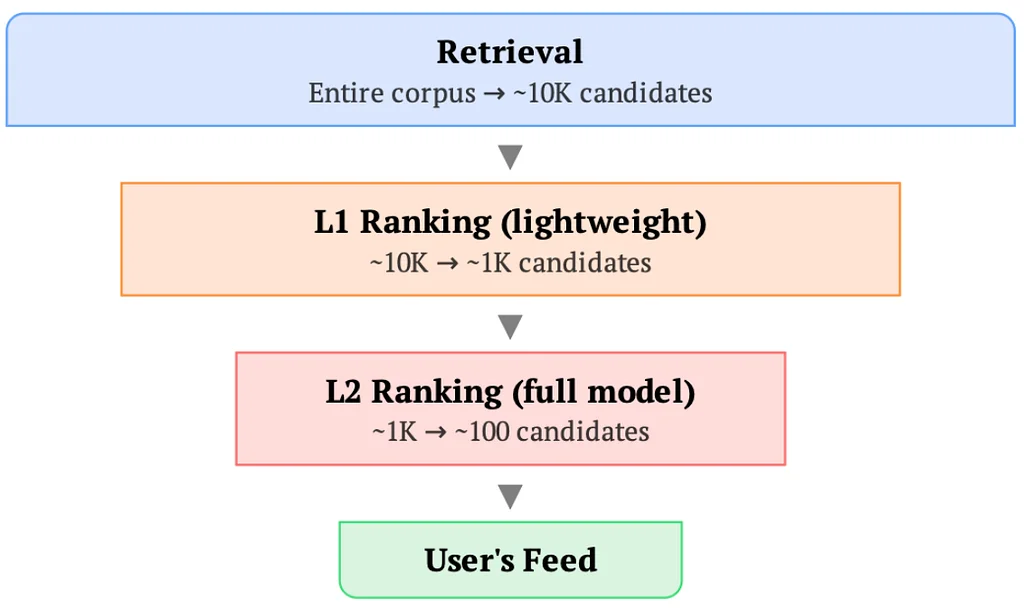
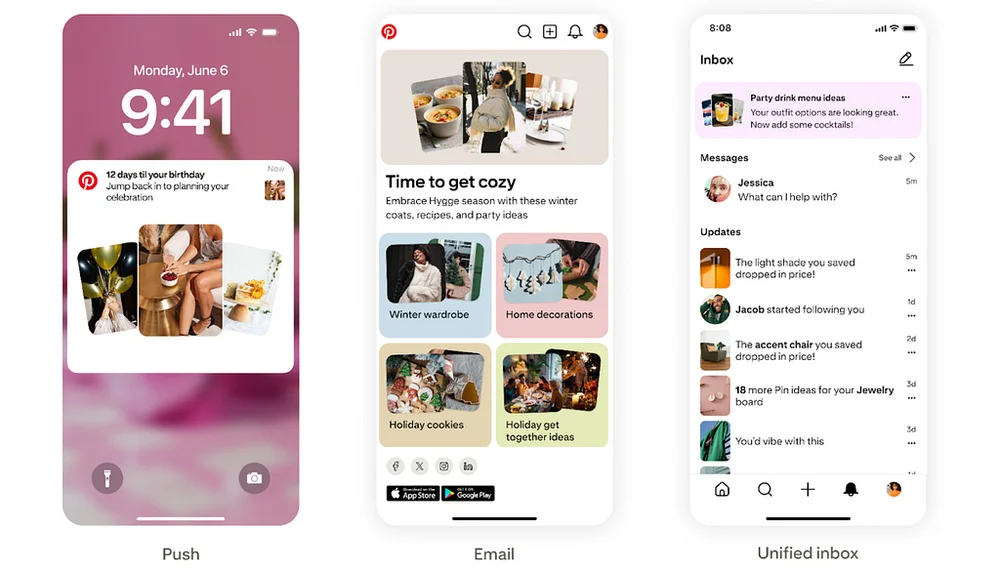
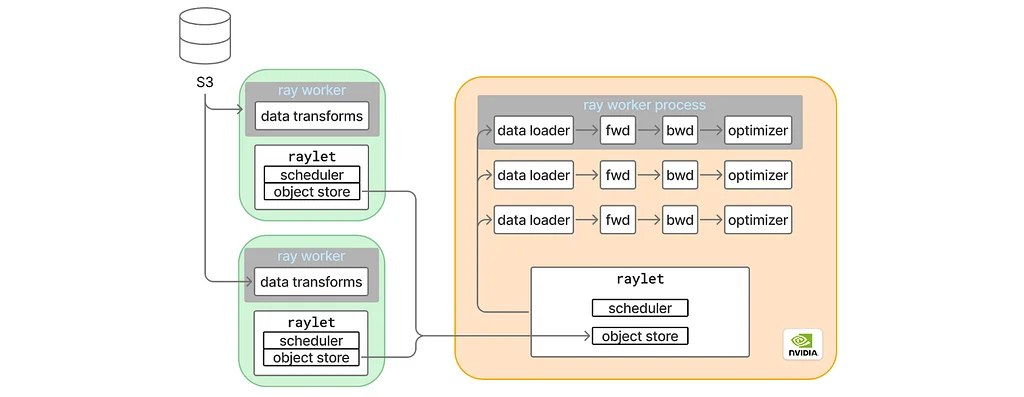
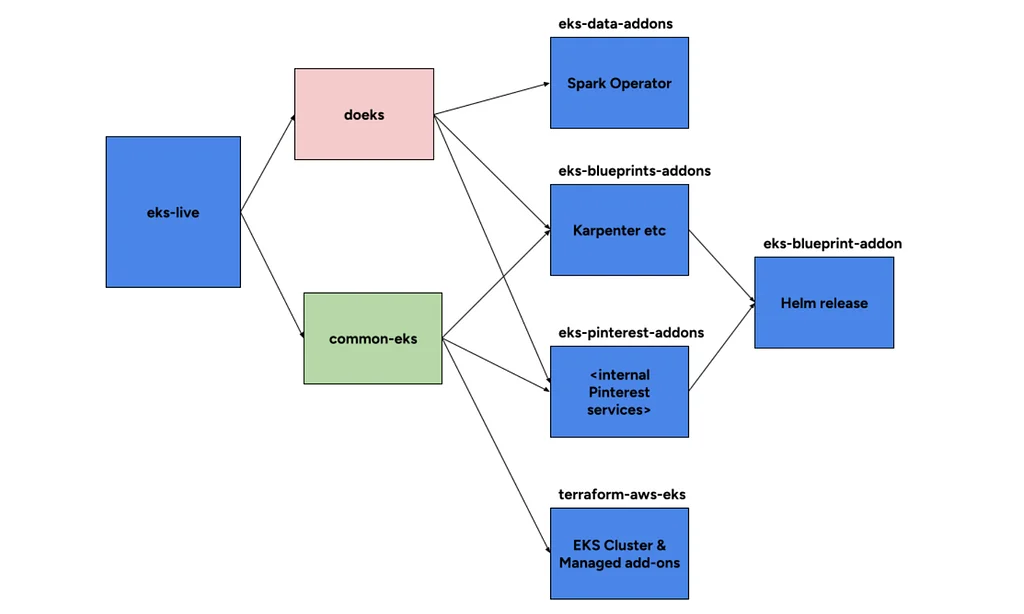
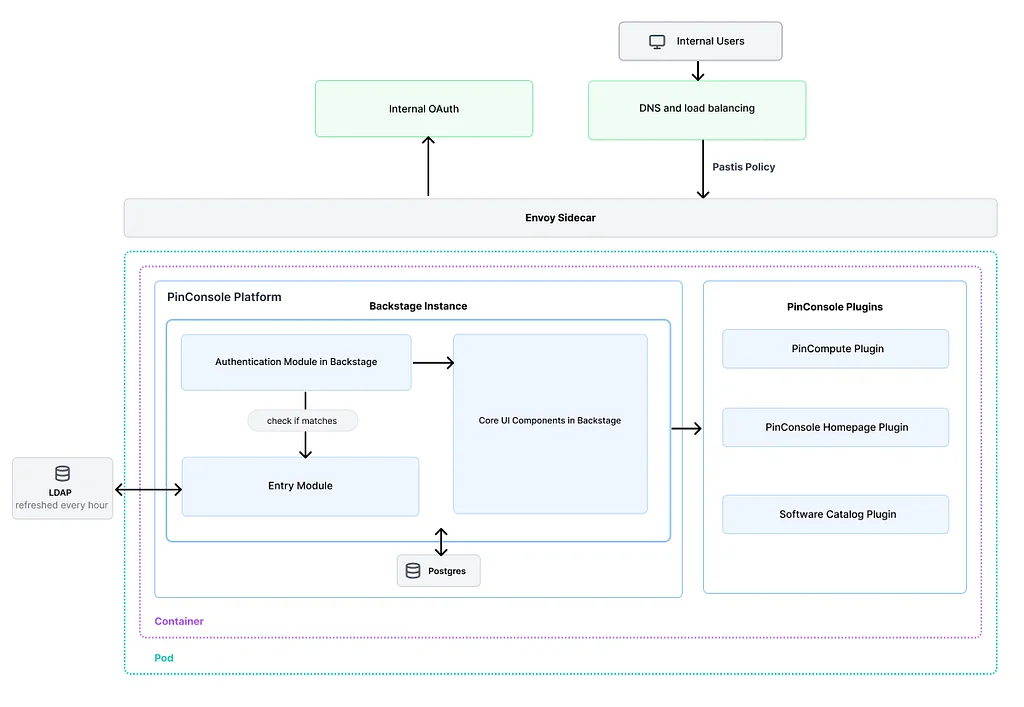
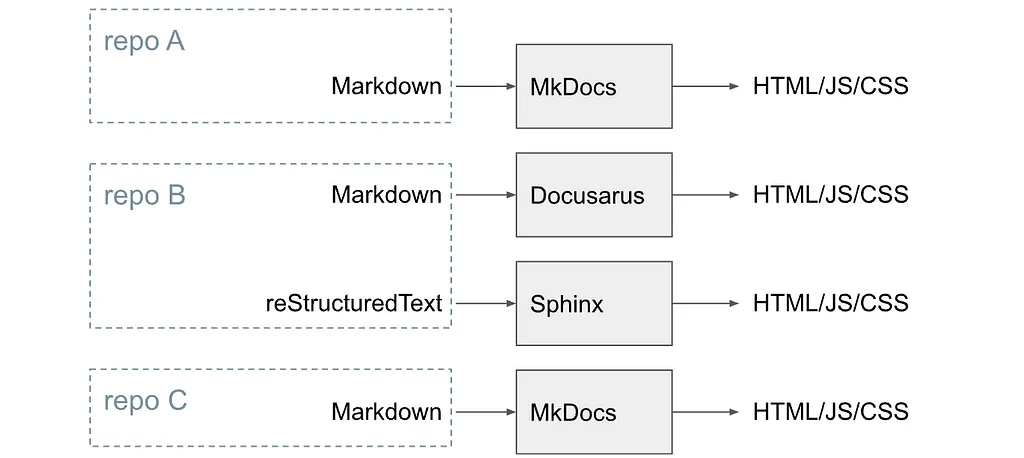
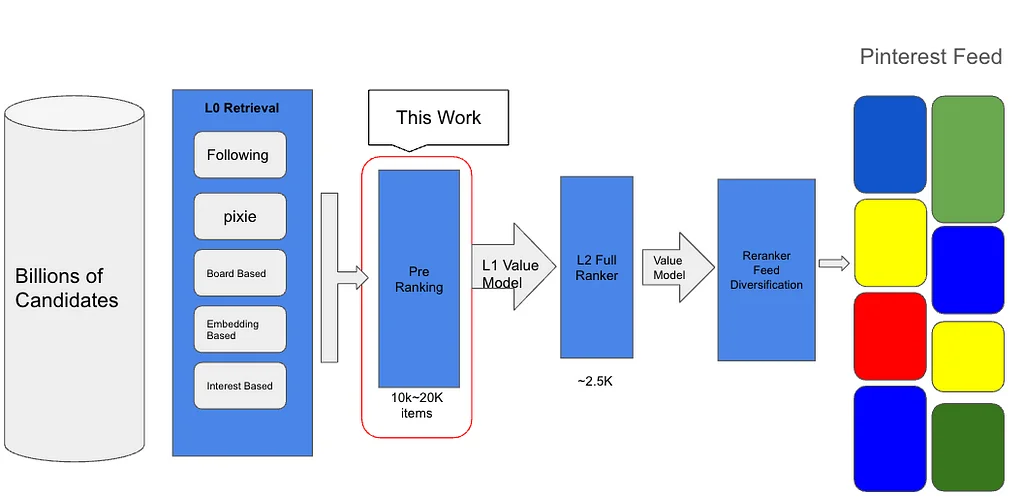
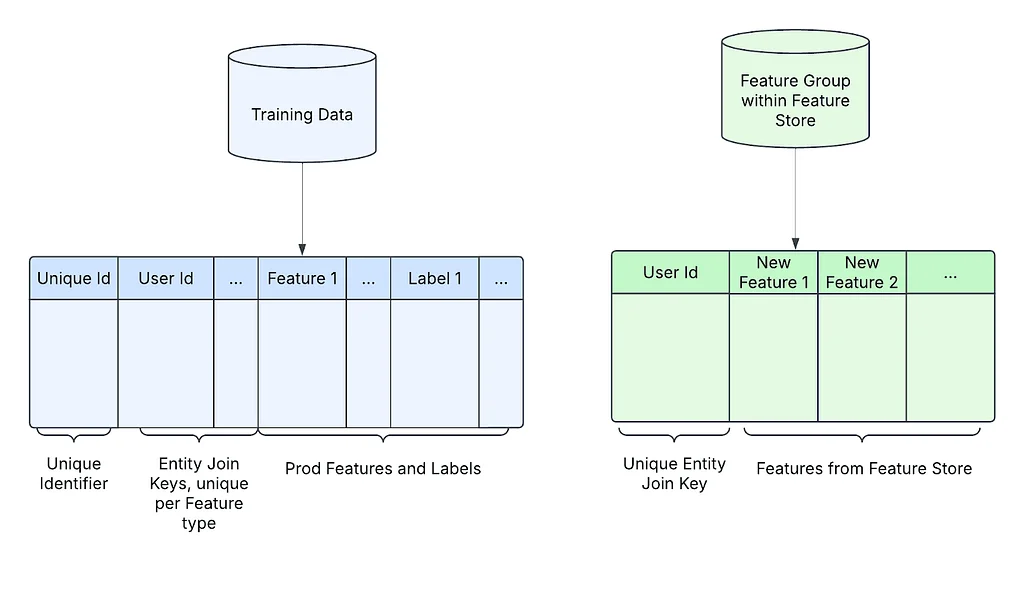
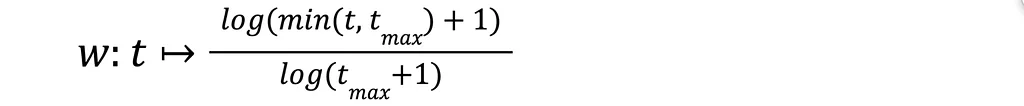Medium上のPinterest EngineeringによるRSSストーリー フォロー
Medium上のPinterest Engineeringは、人気のある視覚的な発見プラットフォームを駆動する技術的なイノベーションを裏側から紹介します。技術者が、スケーラビリティ、機械学習、データインフラストラクチャーなどに関する彼らの仕事の洞察を深く掘り下げています。出版物は、協力、実験、複雑な問題を解決する熱情を強調するPinterestのエンジニアリング文化を強調します。読者は、レコメンデーションシステムの構築、検索機能の最適化、データ分析のためのツールの開発など、多くのトピックを探検できます。この内容は、Pinterestのような大規模なプラットフォームの複雑さに興味のある技術者やテック愛好者にとって非常に有益です。画像認識の課題やインフラストラクチャーの進化など、愛されるオンラインの目的地の技術的な側面を覗くことができます。