Pinterestが効果的なバックフィルを通じてML機能の反復を加速する方法
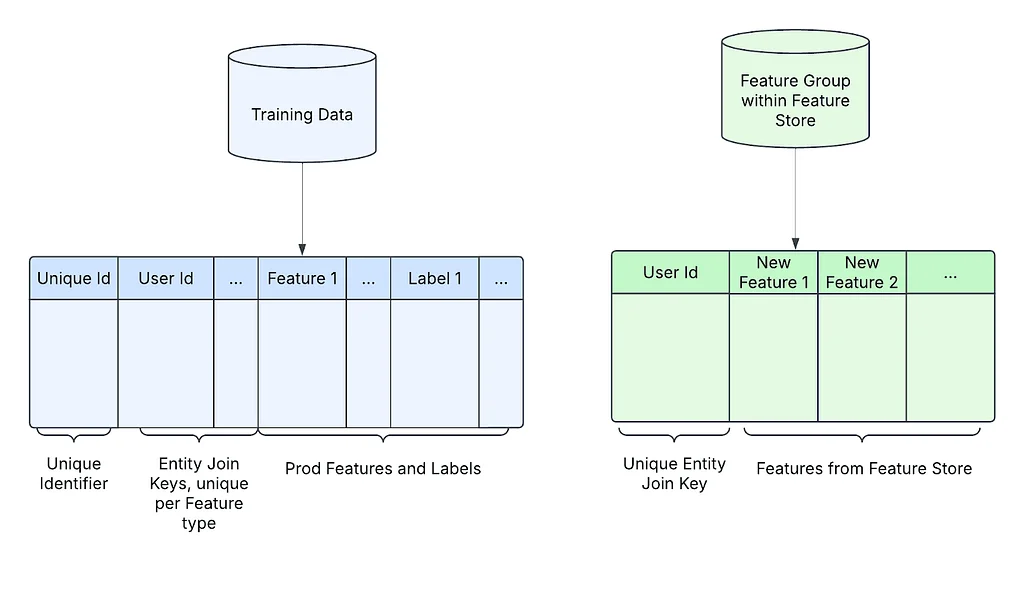
Pinterestでは、最新のレコメンデーションおよび広告モデルを、数十ペタバイトのデータに基づいてトレーニングし、ユーザーが愛する生活をカーケートすることをミッションとしています。これらのモデルは、ユーザーの関心に合ったコンテンツを提示するパーソナライズドレコメンデーションを駆動しています。新しい機能の実験は一般的なタスクであり、最初のステップは、新しい機能をトレーニングデータセットに統合することです。最も直接的な方法はForward Loggingですが、この方法には、高いカレンダー日コスト、高い開発時間コスト、分離の不足、リソースの無駄と不安定という課題があります。Feature Backfillは、これらの課題を解消するために一般的に使用される代替手段です。このブログポストでは、著者たちは、コストと反復時間を最大90倍削減するためのFeature Backfillソリューションの作成方法を探索しています。著者たちは、Sparkを使用してトレーニングテーブル内の機能を実体化する初期のバックフィルソリューション。これは、オンデマンドのMLエンジニアによってトリガーされる再利用可能なAirflow DAGとして運営します。ただし、このソリューションには、同時バックフィルがない、高いコンピュートコスト、手動パーティション管理という課題があります。これらの課題を解消するために、著者たちは、2段階のバックフィルアプローチを採用したv2バージョンを開発しました。このアプローチは、プロセスを2つの主要ステージ、Feature StagingとFeature Promotionにストリームライン化しています。