Ray を使用した Pinterest ML インフラストラクチャーのスケーリング:トレーニングからエンドツーエンド ML パイプライン
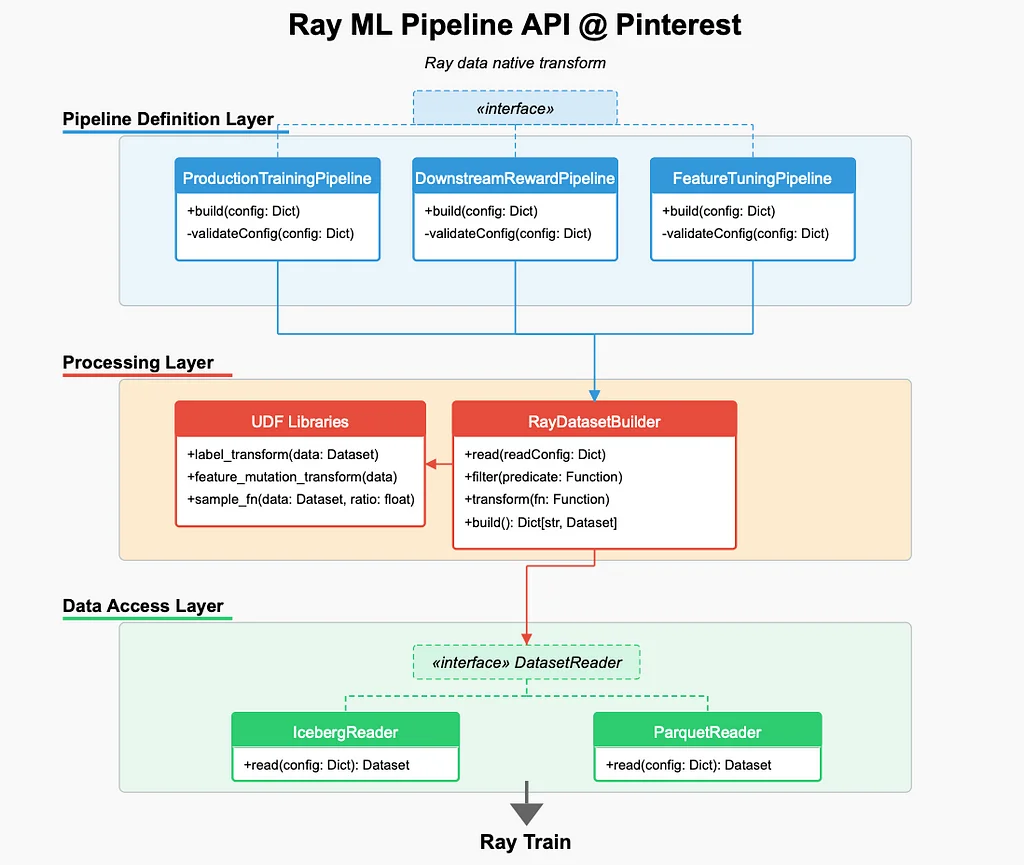
Pinterestでは、MLエンジニアが、遅いデータパイプライン、コストのかかるフィーチャーイテレーション、および非効率的なコンピュート使用によるフィーチャー開発、サンプリング戦略、およびラベル実験の最適化に挑戦しています。 これらの課題に対処するために、Pinterestは、Rayの機能をトレーニングの範囲を超えてフィーチャー開発、サンプリング、およびラベルモデリングに拡張しました。 伝統的なMLインフラストラクチャーは、遅いデータパイプライン、コストのかかるフィーチャーイテレーション、および非効率的なコンピュート使用によって制限されていました。 Pinterestは、4つの主要な改善に焦点を当てて、RayネイティブのMLインフラストラクチャースタックを導入しました。 それは、Ray DataネイティブのパイプラインAPI、Iceberg Bucket Joinsによる効率的なデータジョイン、データの永続化による効率的なイテレーション、および大きなワークロードに対するRay Dataの最適化です。 新しいRayパワーのMLワークフローは、MLイテレーションの時間を10倍短縮しながら、インフラストラクチャーのコストを大幅に削減しています。 Ray DataネイティブのパイプラインAPIは、Ray内でフィーチャー開発、サンプリング、およびラベル変換をネイティブに実現し、Sparkのバックフィルを必要としません。 Iceberg Bucket Joinsは、異なるソース間での高速かつ効率的なフィーチャージョインを可能にします。 データの永続化は、変換されたフィーチャーをキャッシュし、適用可能な場合に再使用することで効率的なイテレーションを実現します。 Ray Dataの最適化は、異なるパイプラインで2-3倍のスピードアップを達成し、Pinterestではよりスケーラブル、効率的、およびコスト効果的なMLインフラストラクチャーを実現しています。