機械学習ワークロードのネットワーク効率の最適化(パートI):特徴量トリマー
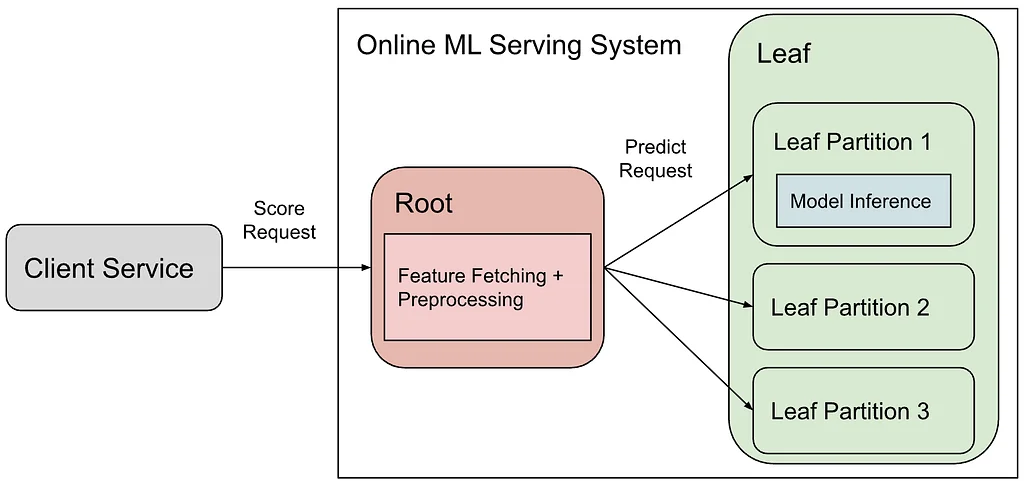
Pinterest のオンライン ML サービングシステムは、クライアントサービスが Pin のスコアをリクエストするルートリーフアーキテクチャを使用しています。ルートコンポーネントは特徴量の取得と前処理を処理し、リーフはモデル推論を実行します。これは多くの場合 GPU 上で行われます。この設計は、新しいモデルのオンボーディングを簡素化し、CPU と GPU のワークロードを分離することでリソース利用率を最適化します。しかし、多くの特徴量を渡すことによるルートとリーフパーティション間のネットワークボトルネックが生じました。当初、ネットワーク使用量を削減するために lz4 圧縮が実装され、帯域幅の大幅な節約につながりましたが、CPU 使用率とレイテンシがわずかに増加しました。これは良いスタートでしたが、不要な特徴量を送信するという根本的な問題は残っていました。この問題に対処するために「Send What You Use」アプローチが開発され、特定のモデルが必要とする特徴量のみを送信するようにしました。モデルの入力と出力を定義するモデルシグネチャは、特徴量要件の信頼できる情報源として機能します。モデルはトレーニングおよびエクスポートされる際に、そのシグネチャが一緒に保存されます。Leaften はこれらのシグネチャをロードして、必要な特徴量のみを処理する特徴量コンバーターを構築します。ルートとリーフ間で特徴量要件を同期するために、モデルシグネチャは軽量なアーティファクトとして公開されます。これらのシグネチャはバンドルレベルのマッピングに集約され、既存の設定とともにルートにデプロイされます。このデプロイは、モデルのロールアウトと同じ段階的な配信プロセスに従い、一貫性を確保し、円滑なロールバックを可能にします。この統合により、Feature Trimmer はルート上の特徴量許可リストを動的に更新でき、必須の特徴量のみが送信されることを保証します。システムは、バージョン管理されたルックアップとフォールバックメカニズムを使用して、頻繁なモデル更新と段階的なロールアウトを処理するように設計されています。これにより、ルートの特徴量要件ビューが、リーフにデプロイされた実際のモデルと同期した状態に保たれます。不要な特徴量をトリミングすることにより、Pinterest はネットワークトラフィックを大幅に削減し、インフラストラクチャの効率を向上させました。