Pinterestにおける大規模データ処理の次世代技術:Moka (後編)
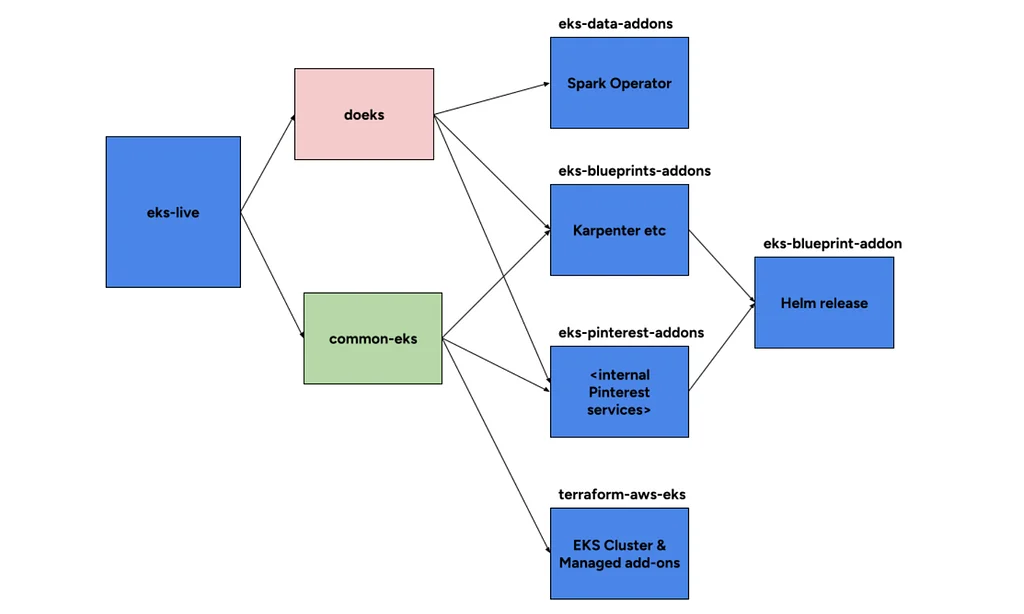
Pinterestは、老朽化したHadoopベースのシステムを置き換えるために、次世代データ処理プラットフォームであるMokaを開発しています。このプラットフォームは、AWS Elastic Kubernetes Service (EKS) 上にデプロイされ、テスト、開発、ステージング、本番の4つの環境で稼働しています。EKSクラスターのデプロイは、カスタムAWSモジュールとHelmチャートで拡張されたTerraformによって管理されています。Mokaの重要なコンポーネントは、そのロギングインフラストラクチャであり、Fluent Bitを使用して、EKSコントロールプレーン、Sparkアプリケーション、およびシステムポッドからAmazon S3にログを収集し、エクスポートしています。Fluent Bitは、SparkアプリケーションのログをユニークなジョブIDでグループ化し、YuniKornのログを解析してリソース使用量の概要を把握するように設定されています。可観測性のために、PinterestはPrometheus互換のフレームワークを使用してメトリクスを収集しています。彼らは、既存のTSDBベースのStatsboardシステムとPrometheusメトリクスをブリッジするために、カスタムサイドカーであるkubemetricsexporterを開発しました。OpenTelemetry Collectorは、テレメトリデータの受信、処理、エクスポートに使用され、Prometheusメトリクス用に特定のパイプラインが構成されています。この堅牢なインフラストラクチャは、Pinterestの大規模なデータ処理を効率的かつ信頼性の高いものにすることを目指しています。