Pinterestの基盤モデルにおけるほぼ線形なトレーニングスケーラビリティの達成
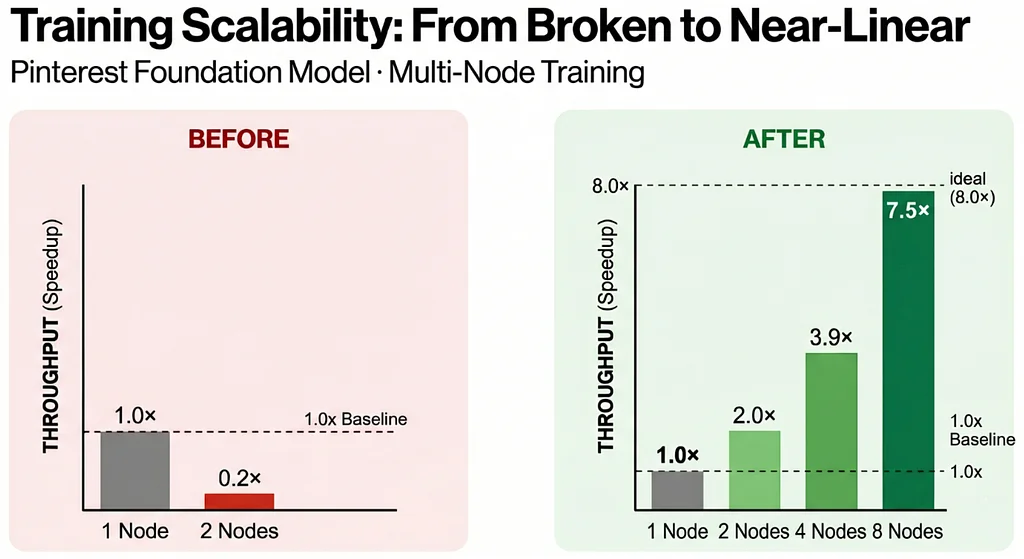
Pinterestの基盤モデルは、レコメンデーションシステムにとって極めて重要であり、毎日何百万人ものユーザーに影響を与えています。当初、これらの大規模モデルのマルチノードトレーニングはパフォーマンスが悪く、マシンの追加はプロセスを劇的に遅くしていました。ネットワーク改善のためにAWS Elastic Fabric Adapter(EFA)を使用しても、スケーリングは非効率なままでした。プロファイリングにより、分散埋め込みルックアップが重大な通信ボトルネックを引き起こし、GPUがデータの到着を待っていることが明らかになりました。チームは、この通信オーバーヘッドに対処するためにいくつかの最適化を実装しました。Quantized Communications(QComms)は、埋め込みテンソルを圧縮することでデータペイロードを削減しました。Balanced shardingは、GPU間のワークロード分散を改善しました。Bandwidth-aware embedding optimizationは、埋め込み次元を半分にすることでデータ移動を削減しました。重要なブレークスルーは、当初AllReduceを最適化するために実装された2D Parallelismであり、ローカル通信を改善しました。最終的に、2D ParallelismのトポロジーをAll-to-Allを最適化するように反転させ、高コストな操作をノード内で維持し、ノード間の同期にはより安価なAllReduceを使用しました。これにより、ほぼ線形のスケーリングが実現し、2ノードで2.0倍、4ノードで3.9倍、そして8ノードで印象的な7.5倍のスケーリングを達成しました。これらの進歩により、より大きなモデルのトレーニングが可能になり、Pinterestのレコメンデーションサーフェスでのユーザーエンゲージメントの大幅な向上と、より迅速な実験サイクルが実現しました。