Pinterestにおける次世代大規模データ処理:Moka(2部構成、パート1)
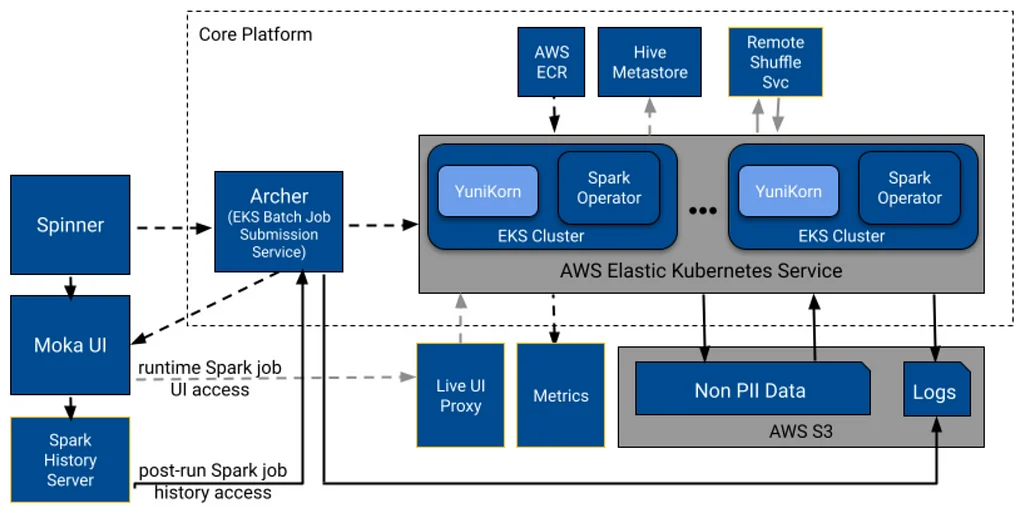
Pinterestのデータエンジニアリングチームは、現在のHadoopベースのプラットフォームであるMonarchを置き換えるための、新しい大規模データ処理プラットフォームを構築しています。チームは、ビッグデータコミュニティでの人気と採用の増加により、Kubernetesベースのシステムを代替として検討しました。新しいプラットフォームは、コンテナの広範なサポート、PinterestのカスタムSparkフォークの実行、および運用・保守コストの削減といった特定の基準を満たす必要がありました。チームは、さまざまなプラットフォームでSparkを実行するための包括的な評価を実施し、コンテナベースの分離とセキュリティ、デプロイの容易さ、組み込みフレームワークといった利点から、Kubernetes中心のフレームワークに傾倒しました。Kubernetesは、他のシステムよりもコンテナ管理とデプロイに対して、よりきめ細かなサポートを提供しますが、データ管理、ストレージ、処理の組み込みサポートは不足しています。チームの現在のHadoopでのデプロイモデルは煩雑であり、Terraform、コンテナイメージ、Helmを使用した、よりシンプルなアプローチに移行しています。新しいプラットフォームは、Monarchを置き換えるためにKubernetesとEKSを活用しますが、EKSを既存のPinterest環境に統合することや、Hadoopコンポーネントの代替を見つけることなど、いくつかの課題があります。チームは、機密性のないデータのみにアクセスするバッチSparkワークロードを処理できる新しいプラットフォーム「Moka」を構築しており、将来的にはさらに機能を追加する予定です。Mokaの初期のハイレベル設計には、Spinner、Archer、Spark Operatorなどの一連のコンポーネントを通じて、ジョブが提出・処理されるバッチSparkワークロードを処理できるシステムが含まれています。チームは、次のブログシリーズでプラットフォームのコアアプリケーション中心の側面について、さらに詳細を提供する予定です。