Medium上のPinterest EngineeringによるRSSストーリー フォロー 謎のML(機械学習)トレーニングの停滞を追跡する PinterestのMLトレーニングプラットフォームであるMLEnvは、PyTorchのバージョンアップ後、著しいパフォーマンス低下に見舞われました。この問題は、トレーニングスループットを50%以上も減少させました。デバッグプロセスは、GPUの屋根型スループットの調査から始まりました。この測定では、データローダーを除外しても20%のパフォーマンス低下が明らかになりました。さらに、個々のモデルモジュールに焦点を当て、遅延の原因を特定するための分析が行われました。特定のTransformerモジュールであるモジュールAが、主な原因として特定されました。PyTorchプロファイラーは、以前は存在していたCompiledFunctionsが、アップグレードされたバージョンではこのモジュールに対して存在しなくなっていることを示しました。torch.compileの調査では、非インフラストラクチャPyTorchディスパッチモードが存在し、torch.compileがそれをサポートしていないことを示すログが発見されました。最小限の再現可能なスクリプトは、この問題がトレーナークラス内で具体的に現れることを確認しました。問題のあるコンポーネントは、デフォルトで有効になっているFLOPsカウントに使用されるコンテキストマネージャーであることが特定されました。このコンテキストマネージャーを無効にすると、torch.compileの問題が解決し、CompiledFunctionsが復元されました。しかし、この修正はエンドツーエンドのスループットを改善しませんでした。焦点はデータローディングと分散トレーニングの側面に再び移り、Ray.dataが原因ではないことが、ネイティブPyTorchアプリケーションとして実行した場合でも同じGPU屋根型スループットの問題が観察されたことから除外されました。いくつかの観察結果は、断続的な遅いイテレーション、同期中のストラグラー効果、そしてNvidiaのNsight Systemsプロファイラーを有効にすると遅延が解消されるという奇妙な動作を指摘しました。単一GPUでのテストにより、分散トレーニングが根本原因ではないことが確認されました。Rayセットアップでtorch.compileを完全に無効にすると、元のスループットが回復し、torch.compile内のグラフブレイクが遅延に関連していることが示唆されました。広範なグラフブレイクを持つ最小限の再現可能なモデルを作成した結果、遅いイテレーションが繰り返し発生することが観察されました。Nsight Systemsトレースは、これらの遅いイテレーション中にメインのトレーニングスレッドがグローバルインタプリタロック(GIL)を保持していることを明らかにしましたが、これはすべてのポーズを説明するものではありませんでした。Linuxのperfツールを使用したさらなる分析と、chrome://tracingによるトレースの可視化により、疑わしいPythonプロセスが浮き彫りになりました。このプロセスは、高コストな計算、具体的には仮想メモリ統計を収集するsmap_gather_statsというLinuxカーネルコールを実行していました。 Tracking Down Mysterious ML Training Stalls medium.com
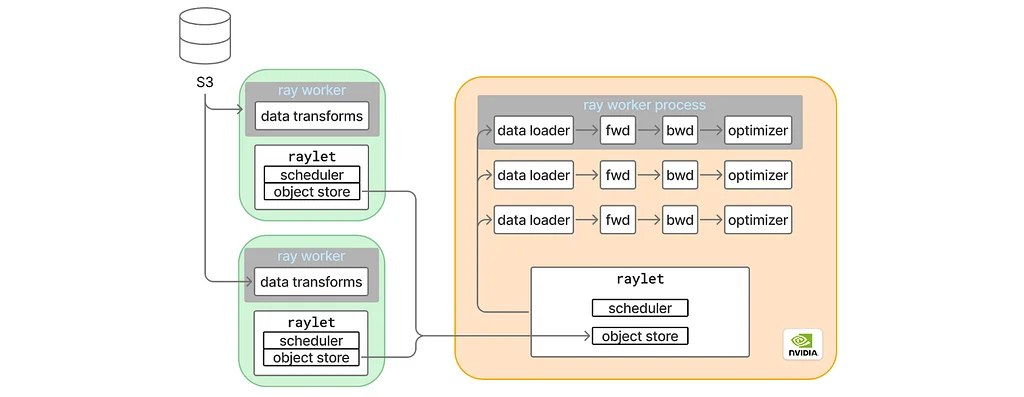
torch.compileの調査では、非インフラストラクチャPyTorchディスパッチモードが存在し、torch.compileがそれをサポートしていないことを示すログが発見されました。最小限の再現可能なスクリプトは、この問題がトレーナークラス内で具体的に現れることを確認しました。問題のあるコンポーネントは、デフォルトで有効になっているFLOPsカウントに使用されるコンテキストマネージャーであることが特定されました。このコンテキストマネージャーを無効にすると、torch.compileの問題が解決し、CompiledFunctionsが復元されました。しかし、この修正はエンドツーエンドのスループットを改善しませんでした。焦点はデータローディングと分散トレーニングの側面に再び移り、Ray.dataが原因ではないことが、ネイティブPyTorchアプリケーションとして実行した場合でも同じGPU屋根型スループットの問題が観察されたことから除外されました。いくつかの観察結果は、断続的な遅いイテレーション、同期中のストラグラー効果、そしてNvidiaのNsight Systemsプロファイラーを有効にすると遅延が解消されるという奇妙な動作を指摘しました。単一GPUでのテストにより、分散トレーニングが根本原因ではないことが確認されました。Rayセットアップでtorch.compileを完全に無効にすると、元のスループットが回復し、torch.compile内のグラフブレイクが遅延に関連していることが示唆されました。広範なグラフブレイクを持つ最小限の再現可能なモデルを作成した結果、遅いイテレーションが繰り返し発生することが観察されました。Nsight Systemsトレースは、これらの遅いイテレーション中にメインのトレーニングスレッドがグローバルインタプリタロック(GIL)を保持していることを明らかにしましたが、これはすべてのポーズを説明するものではありませんでした。Linuxのperfツールを使用したさらなる分析と、chrome://tracingによるトレースの可視化により、疑わしいPythonプロセスが浮き彫りになりました。このプロセスは、高コストな計算、具体的には仮想メモリ統計を収集するsmap_gather_statsというLinuxカーネルコールを実行していました。