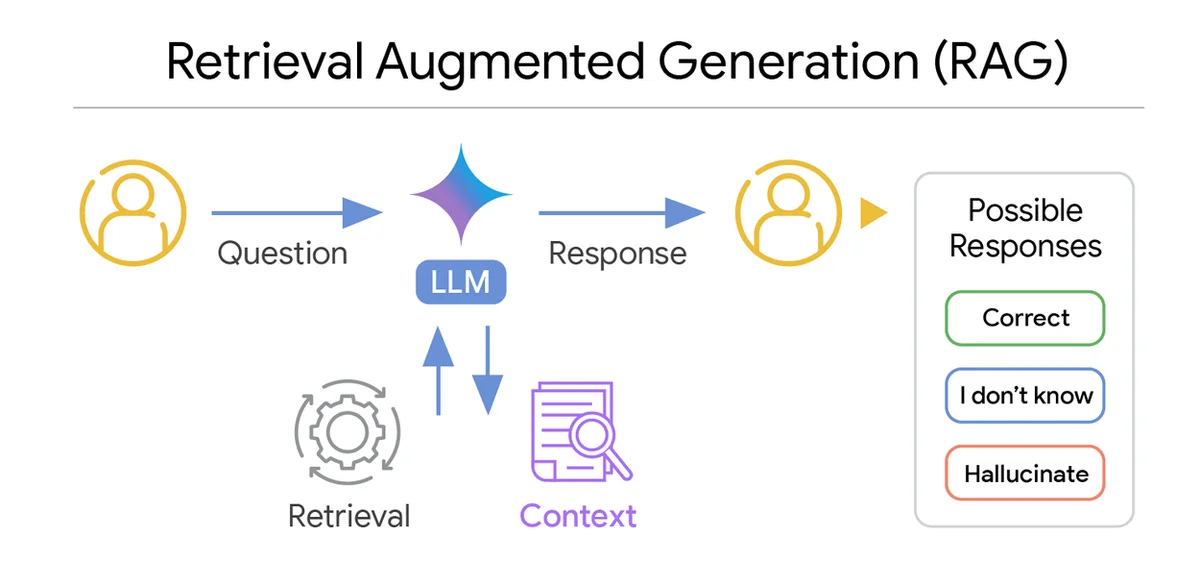
検索拡張生成(RAG)に関するより深い洞察:十分なコンテキストの役割
Retrieval Augmented Generation (RAG) システムは、大規模言語モデル (LLM) に関連する外部情報を提供することで、LLM を強化します。理想的には、LLM は正しい答えを生成するか、特定の重要な情報が不足している場合は「わかりません」と応答します。RAG システムの主な課題は、幻覚情報(したがって、誤った情報)によってユーザーを誤解させる可能性があることです。著者は、コンテキストの関連性だけを測定することは間違っていると考えています。彼らは、コンテキストが LLM が質問に答えるのに十分な情報を提供しているかどうかを知りたいと考えています。著者は、コンテキストがクエリに対する明確な答えを提供するのに必要なすべての情報を含んでいる場合に「十分」と定義し、必要な情報が不足している場合に「不十分」と定義しています。著者は、LLM のコンテキストの十分性を定量化する方法を開発し、Vertex AI RAG Engine で LLM Re-Ranker をリリースします。著者は、LLM が質問に対する正しい答えを提供するのに十分な情報を持っているかどうかを知ることが可能であることを示しています。著者は、これらのアイデアを使用して、RAG システムのパフォーマンスに影響を与える要因を分析し、いつ、なぜ成功または失敗するのかを分析します。著者は、クエリとコンテキストのペアを評価する十分なコンテキスト自動評価器を開発し、十分なコンテキストを非常に高い精度で分類できることを示しています。著者は、彼らの十分なコンテキスト自動評価器を使用して、さまざまな LLM とデータセットのパフォーマンスを分析し、いくつかの重要な発見につながっています。