明確化の学習:アクションベースのコントラスト自己トレーニングを用いたマルチターン会話
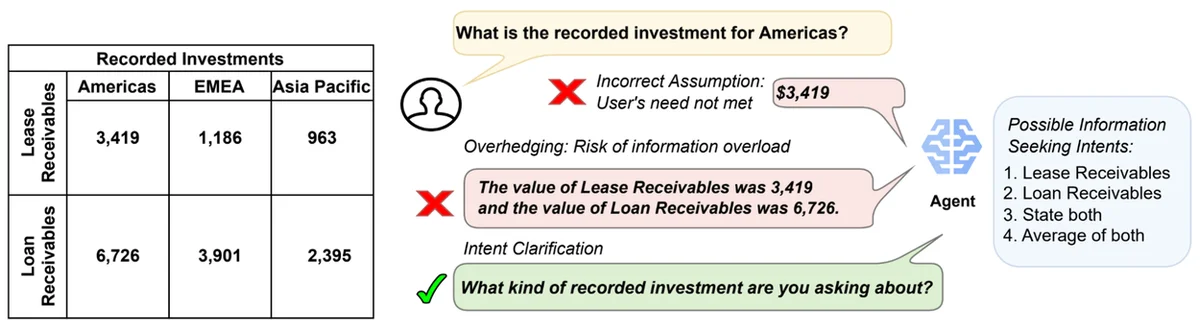
大規模言語モデル(LLM)は、知的会話エージェントの開発における主要なパラダイムとなっているが、曖昧性の解消などのマルチターン会話スキルが不足していることが多い。この問題に対処するために、著者は、データ効率の高い会話ポリシーの学習を可能にする準オンラインの好み最適化アルゴリズムであるAction-Based Contrastive Self-Training(ACT)を提案している。ACTは、従来のファインチューニングアプローチやDPOに比べて、会話モデリングの改善に大きな効果を示している。著者はまた、複雑なSQLコード生成のための曖昧性の解消を目的とした新しいタスクであるAmbigSQLを紹介している。ACTには、好みデータセットの構築、拒否された応答の合成、DPOオブジェクトを使用したポリシーモデルのチューニングが含まれる。著者は、ACTをオープンウェイトLLMとさまざまな会話データセットで実験し、従来のファインチューニング、反復推論好み最適化、GeminiとClaudeのインコンテキスト学習例などのさまざまなベースラインと比較している。ACTは、すべてのメトリックで最高のパフォーマンスを達成しており、曖昧性を暗黙的に認識するチューニング済みモデルの能力を測定した場合、従来のファインチューニングよりも最大19.1%の相対的な改善を実現している。著者はまた、ACTの各コンポーネントの利点を理解するために削除実験を実施しており、アクションベースの好み、オンポリシーサンプリング、トラジェクトシミュレーションが、マルチターン目標の完了の改善に重要であることを発見している。全体として、ACTは、人間のフィードバックとの事前の整合に関係なく、パフォーマンスを改善できるモデル非依存アプローチである。